Alteryx Designer Desktop Ideas
Share your Designer Desktop product ideas - we're listening!Submitting an Idea?
Be sure to review our Idea Submission Guidelines for more information!
Submission Guidelines- Community
- :
- Community
- :
- Participate
- :
- Ideas
- :
- Designer Desktop: New Ideas
Featured Ideas
Hello,
After used the new "Image Recognition Tool" a few days, I think you could improve it :
> by adding the dimensional constraints in front of each of the pre-trained models,
> by adding a true tool to divide the training data correctly (in order to have an equivalent number of images for each of the labels)
> at least, allow the tool to use black & white images (I wanted to test it on the MNIST, but the tool tells me that it necessarily needs RGB images) ?
Question : do you in the future allow the user to choose between CPU or GPU usage ?
In any case, thank you again for this new tool, it is certainly perfectible, but very simple to use, and I sincerely think that it will allow a greater number of people to understand the many use cases made possible thanks to image recognition.
Thank you again
Kévin VANCAPPEL (France ;-))
Thank you again.
Kévin VANCAPPEL
-
Category Calgary
-
Desktop Experience
It would be very helpful if we could pick from a list of installed calgary datasets in the dropdown menu:
we currently have the ability to choose geocoder/drivetime/Allocate datasets which are typically stored in the .ini files, but don't currently have the ability to choose calgary datasets.

-
Category Calgary
-
Category Interface
-
Desktop Experience
It would be nice if we could resize the linked calgary tables box in the calgary input tool. It only shows 2 tables by default. I would like to be able to show more at times. I can change the size of the fields and query boxes, but the linked tables box is fixed at 2 rows by default.

-
Category Calgary
-
Desktop Experience
I love the new (relatively) ConsumerView Decoder Tool! I used to do it the hard way, and it was fragile.
However, one thing is still missing: the Mosaic fields (MOSAIC HOUSEHOLD and MOSAIC ZIP4) - these are output from the tool as nulls. So, not only do you not get it decoded, you have to join back to the input to get the fields back as they were.
First, at least please pass them through as they were.
But preferably, decode them to the Mosaic Segment/Group names.
I realize (or couldn't find) the source for the Mosaic segment definitions is not currently in a Calgary database, but the tool is in the Calgary group.
-
Category Calgary
-
Category Demographic Analysis
-
Desktop Experience
A great feature would be for CASS to provide the address type as Residential or Business. Better yet, further breakdown of address type into single-family, apartment, retail, office, commercial, warehouse, etc. This would be very beneficial when analyzing address data from the Tom Tom Address Points Calgary database and can allow a end-user to filter prioritize addresses in their analysis based on the type of address.
-
Category Address
-
Category Calgary
-
Desktop Experience
I would like to be able to add an in-house built Calgary db to the list of data sources in the pull down on the Calgary Input tool. A customer database, for example.
In the picture you can see the Kalibrate Technologies Traffic Counts and TomTom US Address Points in the pull down. I would like to add my own Calgary db to the list of choices.

{kind=link}
-
Category Calgary
-
Desktop Experience
I have not found this function or a workaround, only as "recent connections" which normally, are not saved on Virtual Machines.
This would save the time it takes to find the path/folder where Calgary DBs are saved.
if this has been proposed or fixed already, please delete this idea!
-
Category Calgary
-
Category Connectors
-
Category Input Output
-
Data Connectors
Love the functionality to create filters on the Calgary database but it would be nice to be able to select the columns you wanted returned. There are times where you only want a couple columns but the input tool will return all columns creating a larger dataset then required. You can add a select right after the input but this is after the entire dataset has been loaded into memory. Combining the two would make the Calgary input tool behave more like a database then a standard "dumb" input source.
-
Category Calgary
-
Category Input Output
-
Data Connectors
-
Desktop Experience
Please have the Calgary Tools put the file names in the annotation automatically like all other input/output tools.
-
Category Calgary
-
Desktop Experience
In my environment, installing Core Data Bundle to network drive ("prepare a network install") runs for hours or days due to network factors. If interrupted, I need to start from scratch again.
These changes would greatly improve the installation:
- Maintain verbose installer log to track progress and confirm that all selected files are successfully installed.
- Add a repair mode to the installer to repair interrupted installations. When run in this mode, only missing/corrupt data files will be re-installed as necessary (much faster than fresh install).
- Support use of a shortcut like "CURRENT" on my network drive to the real installation directory (say "Q3_2017"). This would allow me to point to the latest release and users who "register from a network location" via "CURRENT" shortcut path will always get the latest data files. As an administrator, I have no way to know if my Alteryx users are configured to use an obsolete data set that I want to clean up from my network drive.
- When I prepare a network installation, I'd like to specify an expiry date and warning message that users will see in their workflows if they access obsolete data sets. Example: "Core data set XXX is obsolete as of 12/31/2017. Register current version via \\my-network-drive\alteryx\???\DataInstall.exe...". Nice to have would be a warning date and an error date to provide grace period. This would be similar to the CASS data set expiry date.
-
Category Calgary
-
Desktop Experience
As a GIS department, we use numerous spatial datasets on a daily basis. Many of these are quite large and we are looking for ways to optimize their performance. Right now, we are forced to use an indexed folder system to increase performance, but we would like to move to Calgary databases. The problem is, that Calgary databases only hold point features which limits the number of our datasets that we can use it with. If we could spatially index line and polygon features as well, that would dramatically increase the usefulness of a Calgary database.
-
Category Calgary
-
Category Spatial
-
Desktop Experience
-
Location Intelligence
Could we please have the option of selecting the fields, like the join tool, within the Calgary Join tool? It is especially problematic when I simply want to assign spatial object name to a point; i.e customers within a DMA or sales territory.
This would be agreat addition within the ConsumeView Matching tool as well.
Thanks!
-
Category Calgary
-
Desktop Experience
Occasionally, the Calgary Loader tool will not write out all fields passed to it. This seems to happen after writing out a certain number of fields then later, when rerunning, adding a new output field. Very annoying because you don't know it will happen until processing is complete and you examine the result. I usually manually delete the calgary files prior to rerunning, to avoid the versioning, but it still happens.
Also, please make the versioning optional with a check box, default off.
-
Category Calgary
-
Category Input Output
-
Data Connectors
-
Desktop Experience
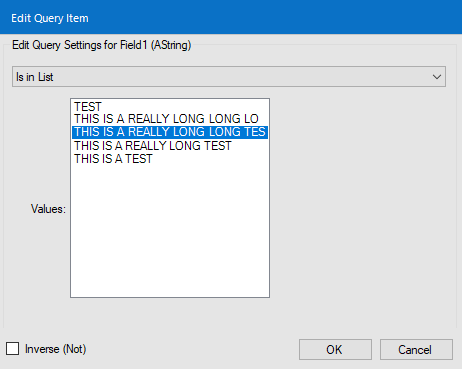
When choosing "In List" values in a CYDB input, the normal Windows functions do not work (shift+click, ctl+A, ctl+click, etc.).
When having to choose, say, 20 values, it is a big annoyance to have to click each value (20 clicks).
Have been told this is a bug so I wanted to put it on your radar for a fix.
-
Category Calgary
-
Desktop Experience
As with Output Data tool, it would be very helpful to have this option within the Calgary Loader tool. I have a series of ordered analytic apps and if I could name the Calgary database using the "Take File/Table Name from Field" option I would be able to chain the apps and be much more efficient.
Thanks.
-
Category Calgary
-
Desktop Experience
-
Category Calgary
-
Desktop Experience
-
Category Calgary
-
Desktop Experience
-
Category Calgary
-
Desktop Experience
Our team works with a lot of in-house transaction data sets that have been put into a calgary database. It would be much easier to build apps that use the calgary input tool without having to configure html code.
-
Category Calgary
-
Desktop Experience
Example: State Code = 'MI' and Mosaic Type = 'A01' could be our Criteria. and State Code, Mosaic Type and Gender would be our crosscount fields.
Calgary crosscount (and append) would output (51 * 71 * 4) 14,484 rows (all states * all mosaic types * all gender values)
The desired crosscount would output (1 * 1 * 4) 4 rows (MI * A01 * 4).
This is a simplified example just to demonstrate my confusion when Alteryx responded to me that the tool is working as designed. In order to reduce the crosscount output, you must restate your query criteria in a filter post the calgary tool. If the count of rows output exceeds a thresshold, you can't even use the tool as it will generate too many rows.
By defining criteria in the Calgary Input tool, only the desired output records are generated. But by defining criteria in the Calgary crosscount tools, only the desired "combinations" have values plus it outputs all permutations and combinations of other non-qualifying records.
Please consider this request for an enhancement.
Thanks,
Mark
-
Category Calgary
-
Desktop Experience
- New Idea 376
- Accepting Votes 1,784
- Comments Requested 21
- Under Review 178
- Accepted 47
- Ongoing 7
- Coming Soon 13
- Implemented 550
- Not Planned 107
- Revisit 56
- Partner Dependent 3
- Inactive 674
-
Admin Settings
22 -
AMP Engine
27 -
API
11 -
API SDK
228 -
Category Address
13 -
Category Apps
114 -
Category Behavior Analysis
5 -
Category Calgary
21 -
Category Connectors
252 -
Category Data Investigation
79 -
Category Demographic Analysis
3 -
Category Developer
217 -
Category Documentation
82 -
Category In Database
215 -
Category Input Output
655 -
Category Interface
246 -
Category Join
108 -
Category Machine Learning
3 -
Category Macros
155 -
Category Parse
78 -
Category Predictive
79 -
Category Preparation
402 -
Category Prescriptive
2 -
Category Reporting
204 -
Category Spatial
83 -
Category Text Mining
23 -
Category Time Series
24 -
Category Transform
92 -
Configuration
1 -
Content
2 -
Data Connectors
982 -
Data Products
4 -
Desktop Experience
1,604 -
Documentation
64 -
Engine
134 -
Enhancement
406 -
Event
1 -
Feature Request
218 -
General
307 -
General Suggestion
8 -
Insights Dataset
2 -
Installation
26 -
Licenses and Activation
15 -
Licensing
15 -
Localization
8 -
Location Intelligence
82 -
Machine Learning
13 -
My Alteryx
1 -
New Request
226 -
New Tool
32 -
Permissions
1 -
Runtime
28 -
Scheduler
26 -
SDK
10 -
Setup & Configuration
58 -
Tool Improvement
210 -
User Experience Design
165 -
User Settings
85 -
UX
227 -
XML
7
- « Previous
- Next »
- abacon on: DateTimeNow and Data Cleansing tools to be conside...
-
 TonyaS
on:
Alteryx Needs to Test Shared Server Inputs/Timeout...
TonyaS
on:
Alteryx Needs to Test Shared Server Inputs/Timeout...
-
 TheOC
on:
Date time now input (date/date time output field t...
TheOC
on:
Date time now input (date/date time output field t...
- EKasminsky on: Limit Number of Columns for Excel Inputs
- Linas on: Search feature on join tool
-
MikeA
on:
Smarter & Less Intrusive Update Notifications — Re...
- GMG0241 on: Select Tool - Bulk change type to forced
-
Carlithian
on:
Allow a default location when using the File and F...
- jmgross72 on: Interface Tool to Update Workflow Constants
-
pilsworth-bulie
n-com on: Select/Unselect all for Manage workflow assets
| User | Likes Count |
|---|---|
| 6 | |
| 5 | |
| 3 | |
| 2 | |
| 2 |