Alteryx Designer Desktop Ideas
Share your Designer Desktop product ideas - we're listening!Submitting an Idea?
Be sure to review our Idea Submission Guidelines for more information!
Submission Guidelines- Community
- :
- Community
- :
- Participate
- :
- Ideas
- :
- Designer Desktop
Featured Ideas
Hello,
After used the new "Image Recognition Tool" a few days, I think you could improve it :
> by adding the dimensional constraints in front of each of the pre-trained models,
> by adding a true tool to divide the training data correctly (in order to have an equivalent number of images for each of the labels)
> at least, allow the tool to use black & white images (I wanted to test it on the MNIST, but the tool tells me that it necessarily needs RGB images) ?
Question : do you in the future allow the user to choose between CPU or GPU usage ?
In any case, thank you again for this new tool, it is certainly perfectible, but very simple to use, and I sincerely think that it will allow a greater number of people to understand the many use cases made possible thanks to image recognition.
Thank you again
Kévin VANCAPPEL (France ;-))
Thank you again.
Kévin VANCAPPEL
My employer just started with Alteryx, so I'm sure after a few months, this will be basic simple, but I'm sure I'm not the only person who has made this mistake, so there you go...
I was running a larger workflow that ends with outputting a table with about 80 columns. Everything was working fine, except for one column, which kept coming up as all 0s. Took me a while to find it, but the error all traced back to an error I made with a "Contains" function in a Formula node.
The Alteryx "Contains" function takes two arguments, 'string' and 'target'. I interpreted this as 'find this string in this target variable', and entered two arguments: the string of characters I was looking for first, and then the name of the column I wanted to search in second.
I think I had this backwards. You need to enter the column name first, then the substring you want to look for second. So the column name is the 'string' and the search term is the 'target'. Me getting these reversed did not produce any errors or warnings, which I understand (e.g. maybe you might want to pairwise search for the text in one column in the text of another).
I think the terms 'string' and 'target' are kind of vague labels in this case (in Excel, for example, the analogous "Search" function takes the arguments 'find_text' and 'within_text', which is a lot harder to misinterpret). So I would suggest changing the argument names in Designer and the online documentation, or at least adding text to the Alteryx Documentation (https://help.alteryx.com/2019.2/Reference/Functions.htm) that clarifies which is which.
Normally, I'd say this is a pretty minor thing, but since this is a potential 'silent error', I'd argue it's worthwhile.
(Also, the online documentation seems to imply there is a "CaseInsensitive" argument you can pass to "Contains", however I don't think there actually is. May want to edit that for clarity.)
Thanks!
 Contains function.PNG")
Dear Alteryx Team,
Dynamic Input Tool is a great tool to import easily multiple files using files paths parameters ... having the same tool for outputs would be great to export many files in pre-established folder.
Many thanks
Arno
I suggest an additional tool that would allow adding columns to the data, if and only if they do not exist already.
Currently working with data that has a dynamic set of columns can be a bit tiresome as the Select tool will not allow to select columns that have not been witnessed in the data.
Adding a tool that would ensure that certain columns are available downstream can currently be achieved by:
- 'Append Fields' tool with a 'Text Input' tool which will always append the fields, renaming them on the fly if needed
- 'Union' tool with a 'Text Input' tool
Both options do not seem straight forward and I expect have a performance impact.
A separate tool to achieve this seems the more user friendly and performance oriented way.
Hello,
In Formula tool beneficial will be implementation conditional formatting (similar like in Excel) allowing to change cell style (i.e. background color or bolding) based on specific rule. Currently such functionality is available in Table tool however it might be more convenient to use it in Formula tool and avoid Table tool.
Hi all,
Based on the thread here https://community.alteryx.com/t5/Data-Preparation-Blending/Support-for-unsigned-int-database-type/m-... - there would be value in natively supporting the Unsigned Int data type in Alteryx.
This idea was raised by @jgreene.
Note: this does appear to be directly supported in the core OCBC library (as long as it's supported by the ODBC driver for the specific database in question), so hopefully this won't be a huge lift:
https://docs.microsoft.com/en-us/sql/odbc/reference/appendixes/sql-data-types
@jgreene- would you mind adding any further information about the DBMS you are using which supports unsigned int, and any other info that may help the team to develop and test this (e.g. any link you can find to an available ODBC driver for this database etc?)
Thank you
Sean
Hi there,
Similar to @aselameab1 - I was having trouble with using the Linear regression tool because it was giving error messages that were not explanatory or self descriptive.
@chadanaber identified the issue - that a specific field only had one unique value which was causing the regression tool to fail - however the error message provided gives no useful or helpful indication that this is the issue. You can see that the error message below is pretty tough to understand.
Could we add an item to the development backlog to add defensive checks to the predictive analytics tools to check for conditions that will cause them to fail, and rework the error messaging?


I've attached the workflow with the sample data that replicates this issue
Many thanks
Sean
Would be nice to make it so if I change from RowCount to index it all is linked together.
Something like a $FieldName$ which would automatically get substituted.
Also nice in other formula tools, but most useful in places where name needs to be duplicated over and over
The XML Parse tool has a checkbox to ignore errors and continue. This idea works for all options that allow you to ignore errors. It would be great if XML Parse had 2 outputs, 1 for successful records and another for the errored records. This would make it much easier to identify and update (if necessary) errored records.
In my view this would make it more similar to other tools like Filter or Spatial Match where records that don't fit your criteria follow a different flow.
Thanks for considering
In 2018.4, in the Select tool we were able to select the attributes, and then with CTRL+C copy these lines to the clipboard.
You could then paste it for instance to Excel. I used a lot this feature to communicate with third parties, to who I provide data.

Transfer of records from Python SDK RecordRef seems to be slow sending large amounts of data to the Alteryx Engine (e.g. discussion here). Although unclear of the exact specifics, it seems that there's a copy and convert process in play.
Apache Arrow appears to be addressing this issue, and the roadmap and specs are impressive! It seems like (again I have no understanding of the Alteryx Engine specifics) that something like this would be excellent for expanding SDK use cases as well as for other connectors such as the Apache Spark connector.
And it looks like it'd be fun to build into Alteryx! 🙂
The one single feature I miss the most in Alteryx, is the possibility to restart the workflow from wherever I want by using a built-in cache functionality. I have used the 'Cache Dataset V2' macro, but it really is to inflexible and really doesn't make me a happy Alteryx user. I would like to se a more flexible, quicker way of working with cached data.
On a single tool in the workflow I want to be able to set the option to:
- Enable cache
This would enable me to always use cached data from this node when possible - Run to this node
Run from start OR from node with enabled cache to this node.
There should be lots of workflow options regarding the creation/deletion of cached data. Examples:
- Enable data cache on all nodes
This would enable functionality to always use cached data on all nodes in the workflow - Enable data cache on end nodes
This would enable functionality to cache data on all 'Run to this node'-nodes.
...and so on. These are just a few examples, but there should be lots of options and shortcut keys revolving the cached data functionality in the workflow.
It would be really helpful if Alteryx server could connect directly to files on cloud file storage such as Dropbox, Box and OneDrive. For example; a workflow could access specific source files or a folder with multiple files stored on Dropbox and could run the workflow against those files and then write the output to another folder on Dropbox. We are making less and less use of internal file servers, so accessing files directly from the cloud allow for additional deployment scenerios and flexibility.
It would be helpful to have the Read Uncommitted listed as a global runtime setting.
Most of the workflows I design need this set, so rather than risk forgetting to click this option on one of my inputs it would be beneficial as a global setting.
For example: the user would be able to set specific inputs according to their need and the check box on the global runtime setting would remain unchecked.
However, if the user checked the box on the global runtime setting for Read Uncommitted then all of the workflow would automatically use an uncommtted read on all of the inputs.
When the user unchecks the global runtime setting for Read Uncommitted, then only the inputs that were set up with this option will remain set up with the read uncommitted.
It is important to be able to test for heteroscedasticity, so a tool for this test would be much appreciated.
In addition, I strongly believe the ability to calculate robust standard errors should be included as an option in existing regression tools, where applicable. This is a standard feature in most statistical analysis software packages.
Many thanks!
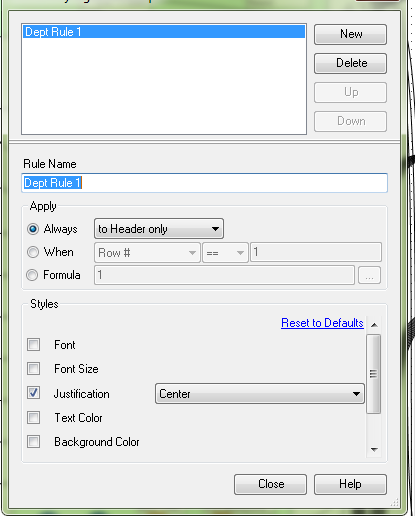
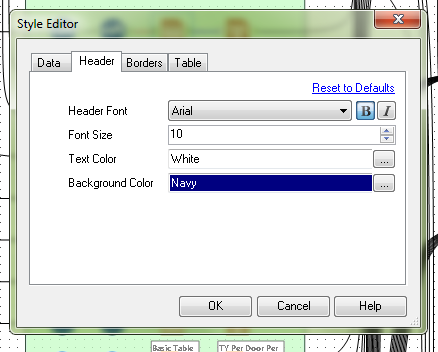
Currently, in order to change the header and data justification to CENTER, one has to select the "Column Rules" button for each column configuration. In a large report (25+ columns), that means selecting each time. It would be more efficient to have the header justification in the Default Table Settings style editor. There is already a setting for font, font size, bold or itallic, text color and background color. I have never created a report for someone where they did not want the headers centered. The workaround is to only feed one column through, then to change the column rules for that column and the Cynamic or Unknown Fields. This works fine, but when I have a report that creates an Excel workbook with 5+ tabs, it gets annoying. It's even more time consuming when I have a report tab, that I need to create sub headings for, so there are multiple report tools for one Excel tab.
{kind=link}
{kind=link}
{kind=link}
Alteryx Gods,
Following a discussion with a person with whom I spend way too much time, @Jeff_Neklason , we were wondering would it be possible to allow users to drag and drop the position of the actual sections at the top of the designer?
Some users find they use the Developer section more than the Parse section, for example, and it would be beneficial if they could move the Developer section to the left to be more easily accessible.
Thank you Alteryx Gods.
I love you.
Kisses.
xxx
It would be good to be able to fix pie chart colours (either automatically of manually), so that when building a report, categories are given the same colour throughout the report across multiple pie charts. Currently, if the number of categories being shown varies, there is no way to manually align the colours (In the Bar Chart type there is a Style Mode for the Series where you can use a formula to assign a colour based on a criteria such as the name, but not for pie charts).
Hello,
The release notes quality is not exactly at its best nowadays The 2022.1 releases notes available here https://help.alteryx.com/release-notes/designer/designer-20221-release-notes don't mention at least two cool new features :
-DCM for in-database connection.
-distinction between greenplum and postgresql, which is important for me as I post this as an idea : https://community.alteryx.com/t5/Alteryx-Designer-Ideas/Separate-entry-in-in-db-configuration-for-Po...
Note that the corresponding idea aren't also up to date.
It's cool to have new features, it's way better if you gives the full list.
Best regards,
Simon
i investigate a super messy and huge workflow, i have a hard time to trace back the data stream.
it only have around 5 wireless connection, some is easy to find, but some are connect to union..
if have a button to turn all connection back to wire, and better if have option for just solid for temp to show as solid line. it will helps alot.
- New Idea 210
- Accepting Votes 1,827
- Comments Requested 25
- Under Review 152
- Accepted 61
- Ongoing 5
- Coming Soon 6
- Implemented 480
- Not Planned 123
- Revisit 67
- Partner Dependent 4
- Inactive 674
-
Admin Settings
19 -
AMP Engine
27 -
API
11 -
API SDK
217 -
Category Address
13 -
Category Apps
111 -
Category Behavior Analysis
5 -
Category Calgary
21 -
Category Connectors
239 -
Category Data Investigation
75 -
Category Demographic Analysis
2 -
Category Developer
206 -
Category Documentation
77 -
Category In Database
212 -
Category Input Output
632 -
Category Interface
236 -
Category Join
101 -
Category Machine Learning
3 -
Category Macros
153 -
Category Parse
75 -
Category Predictive
76 -
Category Preparation
384 -
Category Prescriptive
1 -
Category Reporting
198 -
Category Spatial
80 -
Category Text Mining
23 -
Category Time Series
22 -
Category Transform
87 -
Configuration
1 -
Data Connectors
948 -
Desktop Experience
1,494 -
Documentation
64 -
Engine
123 -
Enhancement
277 -
Feature Request
212 -
General
307 -
General Suggestion
4 -
Insights Dataset
2 -
Installation
24 -
Licenses and Activation
15 -
Licensing
10 -
Localization
8 -
Location Intelligence
79 -
Machine Learning
13 -
New Request
177 -
New Tool
32 -
Permissions
1 -
Runtime
28 -
Scheduler
21 -
SDK
10 -
Setup & Configuration
58 -
Tool Improvement
210 -
User Experience Design
165 -
User Settings
73 -
UX
220 -
XML
7
- « Previous
- Next »
- vijayguru on: YXDB SQL Tool to fetch the required data
- apathetichell on: Github support
- Fabrice_P on: Hide/Unhide password button
- cjaneczko on: Adjustable Delay for Control Containers
-
 Watermark
on:
Dynamic Input: Check box to include a field with D...
Watermark
on:
Dynamic Input: Check box to include a field with D...
- aatalai on: cross tab special characters
- KamenRider on: Expand Character Limit of Email Fields to >254
- TimN on: When activate license key, display more informatio...
- simonaubert_bd on: Supporting QVDs
- simonaubert_bd on: In database : documentation for SQL field types ve...
| User | Likes Count |
|---|---|
| 48 | |
| 30 | |
| 14 | |
| 11 | |
| 6 |