Alteryx Designer Desktop Ideas
Share your Designer Desktop product ideas - we're listening!Submitting an Idea?
Be sure to review our Idea Submission Guidelines for more information!
Submission Guidelines- Community
- :
- Community
- :
- Participate
- :
- Ideas
- :
- Designer Desktop : Ideas activas
Featured Ideas
Hello,
After used the new "Image Recognition Tool" a few days, I think you could improve it :
> by adding the dimensional constraints in front of each of the pre-trained models,
> by adding a true tool to divide the training data correctly (in order to have an equivalent number of images for each of the labels)
> at least, allow the tool to use black & white images (I wanted to test it on the MNIST, but the tool tells me that it necessarily needs RGB images) ?
Question : do you in the future allow the user to choose between CPU or GPU usage ?
In any case, thank you again for this new tool, it is certainly perfectible, but very simple to use, and I sincerely think that it will allow a greater number of people to understand the many use cases made possible thanks to image recognition.
Thank you again
Kévin VANCAPPEL (France ;-))
Thank you again.
Kévin VANCAPPEL
Please improve the Excel XLSX output options in the Output tool, or create a new Excel Output tool,
or enhance the Render tool to include an Excel output option, with no focus on margins, paper size, or paper orientation
The problem with the current Basic Table and Render tools are they are geared towards reporting, with a focus on page size and margins.
Many of us use Excel as simply a general output method, with no consideration for fitting the output on a printed page.
The new tool or Render enhancement would handle different formats/different schemas without the need for a batch macro, and would include the options below.
The only current option to export different schemas to different Sheets in one Excel file, without regard to paper formatting, is to use a batch macro and include the CReW macro Wait a Second, to allow Excel to properly shut down before a new Sheet is created, to avoid file-write-contention issues.
Including the Wait a Second macro increased the completion time for one of my workflows by 50%, as shown in the screehshots below.
I have a Powershell script that includes many of the formatting options below, but it would be a great help if a native Output or Reporting tool included these options:
Allow options below for specific selected Sheet names, or for All Sheets
AllColumns_MaxWidth: Maximum width for ALL columns in the spreadsheet. Default value = 50. This value can be changed for specific columns by using option Column_SetWidth.
Column_SetWidth: Set selected columns to an exact width. For the selected columns, this value will override the value in AllColumns_MaxWidth.
Column_Centered: Set selected columns to have text centered horizontally.
Column_WrapText: Set selected columns to Wrap text.
AllCells_WrapText: Checkbox: wrap text in every cell in the entire worksheet. Default value = False.
AllRows_AutoFit: Checkbox: to set the height for every row to autofit. Default value False.
Header_Format: checkbox for Bold, specify header cells background color, Border size: 1pt, 2pt, 3pt, and border color, Enable_Data_Filter: checkbox
Header_freeze_top_row: checkbox, or specify A2:B2 to freeze panes
Sheet_overflow: checkbox: if the number of Sheet rows exceeds Excel limit, automatically create the next sheet with "(2)" appended
Column_format_Currency: Set selected columns to Currency: currency format, with comma separators, and negative numbers colored red.
Column_format_TwoDecimals: Set selected columns to Two decimals: two decimals, with comma separators, and negative numbers colored red.
Note: If the same field name is used in Column_Currency and Column_TwoDecimals, the field will be formatted with two decimals, and not formatted as currency.
Column_format_ShortDate: Set selected columns to Short Date: the Excel default for Short Date is "MM/DD/YYYY".
File_suggest_read_only: checkbox: Set flag to display this message when a user opens the Excel file: "The author would like you to open 'Analytic List.xlsx' as read-only unless you need to make changes. Open as read-only?
vb code: xlWB.ReadOnlyRecommended = True
File_name_include_date_time: checkboxes to add file name Prefix or Suffix with creation Date and/or Time
========
Examples:
My only current option: use a batch macro, plus a Wait a Second macro, to write different formats/schemas to multiple Sheets in one Excel file:

Using the Wait a Second macro, to allow Excel to shut down before writing a new Sheet, to avoid write-contention issues, results in a workflow that runs 50% longer:

Hello all,
According to wikipedia :
https://en.wikipedia.org/wiki/Embedded_database
An embedded database system is a database management system (DBMS) which is tightly integrated with an application software; it is embedded in the application.
It's often like a single file/dll that you can use inside an application without the user having to connect (or at least to configure it) to it (it's all done inside the application). So, it's widely portable.
Why it does matter ?
As of today, there is not a single example of in database workflow because all the supported databases need the user to:
1/install an odbc driver (most of time, he won't have the rights to do so)
2/configure an odbc connection (sometimes, he doesn't have the rights to)
3/configure a connection on Alteryx (ok, he can)
So it requires IT action, which can be pretty long (in ùany organization, it requires several weeks !!). And even with all of that,the users must be granted privilege to access database and the customer need to develop its own examples and write its own specific documentation.
Well, this is not efficient.
What I suggest is Alteryx to use one of embedded database for training support/one tool examples. SQLlite seems good, maybe a more analytics oriented (like DuckDB ) would be more efficient.
The requirement are, I think, the following :
-OpenSource and free
-Fast
-SQL compliant
-With a bulk load ability
Best regards,
Simon
Similar to this idea, I think it would be really helpful to be able to search for fields in the dropdowns when using the Sort tool. Having to scroll through all of the possible field names can be a chore if you have 50+

In the Input tool, I rely heavily on the recent connection history list. As soon as a file falls off of this list, it takes me a while to recall where it's saved and navigate to the file I'm wanting to use. It would be great to have a feature that would allow users to set their favorite connections/files so that they remain at the top of the connection history list for easy access.

This is a pretty quick suggestion:
I think that there are a lot of formulas that would be easier to write and maintain if a SQL-style BETWEEN operator was available.
Essentially, you could turn this:
ToNumber([Postal Code]) > 1000 AND ToNumber([Postal Code]) < 2500
Into this:
ToNumber([Postal Code]) BETWEEN 1000 AND 2500
That way, if you later had to modify the ToNumber([Postal Code]), you only have to maintain it once. Its both aesthetically pleasing and more maintainable!
Hello,
Just like Monetdb or Vertica, Clickhouse is a column-store database, claiming to be the fastest in the world. It's available on Cloud (like Snowflake), linux and macos (and here for free, it's open-source). it's also very well ranked in analytics database https://db-engines.com/en/system/ClickHouse and it would be a good differenciator with competitors.
https://clickhouse.com/
it has became more popular than Greenplum that is supported : (black snowflake, red greenplum, orange clickhouse)


Best regards,
Simon
Good morning!
This may be a very simple thing, but would it be possible to add a DateTimeQuarter() function? We have DateTime Second, Minute, Day, Month, and Year, and being able to have an easy formula for the quarter as well would be incredibly convenient.
Thanks,
Kat
Today, I am able to take an excel file from a folder and drag it onto the canvas, which automatically creates an Input Data tool.
I would like to be able to drag an excel file right from outlook to do the same!
Referencing the previous idea: Inputs/Output should have the option to read/write a compressed file (ZIP or GZIP)
This idea has been implemented for inputting .zip files. However, we still need to use the run command workaround for outputs. It's very common for many users to want to output their .csv, .xlsx, .pdf to a .zip. The functionality would also need to extend to Gallery.
See the following links for people that are looking for this type of functionality:
https://community.alteryx.com/t5/Alteryx-Designer-Discussions/Output-files-to-ZIP/td-p/163502
https://community.alteryx.com/t5/Alteryx-Designer-Discussions/Zip-files/td-p/151456
Feel free to merge this idea with the previous one for continuity.
When making any type of macro, it's important to test the functionality of the macro via a debug. This is accomplished successfully with normal tools, however there's a bug that will not allow the user to debug In-DB macros that use either of the following standard Alteryx tools:
- Macro Input In-DB
- Macro Output In-DB
If either of these tools are included in the macro you are building, an error message will appear not allowing you to open a debug.
Error message: Question Tool Load Error: A question tool with a tool id of XXX is missing the associated question data.
Of course, Macro input and output tools do not require any specific action/question tool associated with it. This is a bug. A user pointed out the XML issue almost 3 years ago here:
In summary: "It appears that the tool itself inserts a hidden Question attribute into the XML which can also be seen in Workflow Configuration"
Source:
Examples....
A normal macro, using standard tools:

After debugging a standard macro, the Macro Input/Output tools correctly change to a Text Input and a Browse tool. This allows the macro author to test the macro.

However, when trying the same thing with In-DB tools in a macro, an error message appears:
In-DB macro 1:

In-DB Macro error message (after clicking "Open Debug"):

Toggle individual expressions on/off in the formula tool.
On more than a few occasions I have a number of expressions in a single formula tool and find myself wanting to turn off a few or many, but not all.
It'd be great if there was a checkbox to activate/inactivate : on/off : include/exclude : select/deselect (whatever language you like for the concept) an individual expression.
Simple as a text box. with maybe a 'select/deselect ALL box available incase you want to turn most off then only select a single one?
The Formula Tool does a good job of autocompleting expressions (for example an open square bracket will show you variables in your dataset), as well as syntax highlighting (coloring variables, keywords, strings, etc).


I propose having this feature available in all tools that use the expression editor, particularly common ones such as the Multi-Row Formula Tool and the Multi-Field Formula Tool.
This parity across tools would provide a more consistent experience for the user and increase one's productivity using these tools. It's incredibly helpful for beginners and seasoned Alteryx users alike and should be available wherever possible.
Can a function be added to the Text-to-Column tool that allows selecting "split on entire entry" or "split on entry-as-a-whole" for the delimiters field?
Background:
Currently if we type vs. in the delimiters field, it'll look for each character separately including spaces.
The recommendation in the tool help is to use RegEx for splitting on whole words, but for some, RegEx is quite intimidating and adding this function would be a big help for new users.
Proposed Change:
2 Radio Buttons added to the Text-to-Column tool
- Split by Each Entry
- Current functionality
- Should be default
- Splits on every letter, space, punctuation, etc. separately
- Split by Entire Entry
- Allow splitting by using entire entry in the field
- Still includes spaces, letters, and punctuation, but now sees as "whole-word"
Example of function:
- Radio button set to "split by entire entry"
- Delimiter field has: vs.
- Tool sees ______ vs. ______ in a column in the data
- Tool splits ______ and ______ into new columns leaving out the entire vs. including the spaces entered around it
Thank you!
After using the PCA can there be a model object to output to be able to "score" new data?
Similar to PCA transform here https://stackoverflow.com/questions/26182329/how-do-i-convert-new-data-into-the-pca-components-of-my...
As currently there is no way to use this model with new data
Hi
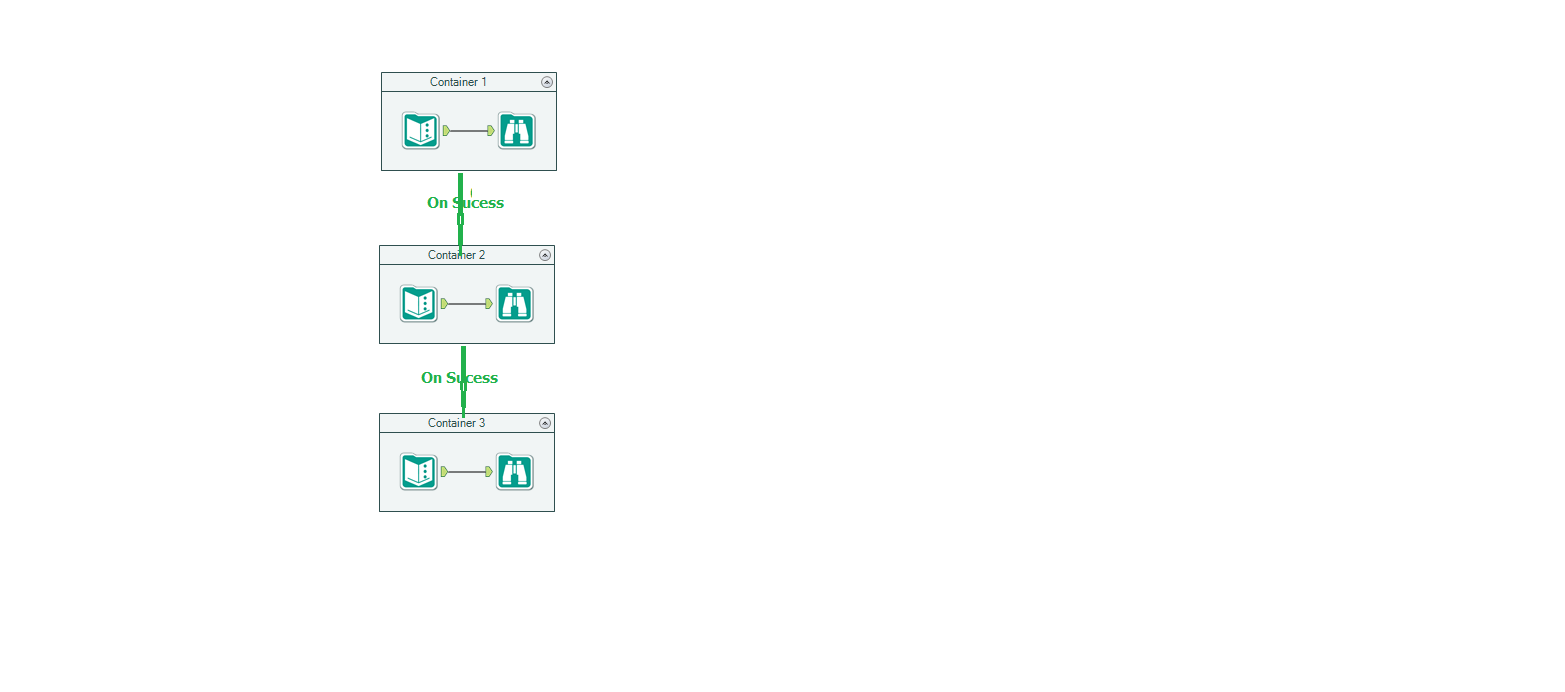
Wanted to control the order of execution of objects in Alteryx WF but right now we have ONLY block until done which is not right choice for so many cases
Can we have a container (say Sequence Container) and put piece of logic in each container and have control by connecting each container?
Hope this way we can control the execution order
It may be something looks like below
Currently the only way to do IF / FOR / WHILE loop is either in Formula tool or via iterative/batch macro.
Instead, it will be hugely useful and a lot more intuitive if there is the ability to build the FOR / WHILE logic embedded in a container (similar to LabVIEW interface https://www.ni.com/en-sg/support/documentation/supplemental/08/labview-for-loops-and-while-loops-exp...).
Advantages include:
- Increased readability. (not having to go into a macro!)
- Increased agility. (more power/ features can be added or modified on the go for something that is more than a Formula tool but not too much interface like a Macro App)
- More intuitive
Dawn.
Hi all!
Based on the title, here's some background information: SHAPLEY Values
Currently, one way of doing so is to utilize the Python tool to write out the script and install the package. However, this will require running Alteryx as an administrator in order to successfully load, test, and run the script. The problem is, a substantial number of companies do not grant such privileges to their Alteryx teams to run as administrator fully as it will always require admin credentials to log in to even open Alteryx after closing it.
I am aware that there is a macro covering SHAP but I've recently tested it and it did not work as intended, plus it covers non-categorical values as determinants only, thereby requiring a conversion of categorical variables into numeric categories or binary categories.
It will be nice to have a built in Alteryx ML tool that does this analysis and produces a graph akin to a heat map that showcases the values like below:

By doing so, it adds more value to the ML suite and actually helps convince companies to get it.
Otherwise teams will just use Python and be done with it, leaving only Alteryx as the clean-up ETL tool. It leaves much to be desired, and can leave some teams hanging.
I hope for some consideration on this - thank you.
Issue
Whenever a Summarize tool is used, it renames the output field (e.g., sales becomes SUM_sales or AVG_sales).
Proposal
I think a reasonable compromise is to by default not rename fields in the Summarize Tool, but to include an option (in the tool, or in global settings) to allow for renaming.
Rationale
I have yet to come across a use case where automatic renaming of aggregated fields is desirable. What I have come across is the annoyance to rename the fields back to what they were with a Dynamic Rename tool, and sometimes having to do this multiple times (e.g., converting back a SUM_SUM_SUM_sales back to sales). Additionally, automatic field renaming causes workflow errors when workflows are later modified by adding/removing a Summarize tool (e.g., if you later add a Summarize tool, all downstream steps will expect the "sales" field and not know to use the "Sum_sales field).
Automatic Renaming feels very much like historic Excel with Pivot Tables field renaming and not reflective of modern code-based workflow best practices.
I appreciate you considering this improvement.
Formula Tool --> Functions --> Operators list
The operator titles for the two comment functions are too similar, the difference cannot be determined unless checking the hover text.
Can the title for /* Comment */ be adjusted to make it more clear that it is for block or multi-line usage?
I didn't understand the difference until I saw this post on LinkedIn:
https://www.linkedin.com/feed/update/urn:li:activity:7165816592063266817/
/* Comment */ --> /* Block Comment */ | /* Multi-line Comment */


Hello all,
As specified in the title, this idea is to distinguish between Append Prefix/Suffix to File and to Table on the Output Data Tool.
For most files (csv...), the table name does not really exist. However, for at least Excel files, if you choose this option, the result will be one sheet by suffix and the only option to have one file by suffix will be to change entire file path.
Best regards,
Simon

- New Idea 272
- Accepting Votes 1.818
- Comments Requested 24
- Under Review 174
- Accepted 56
- Ongoing 5
- Coming Soon 11
- Implemented 481
- Not Planned 116
- Revisit 62
- Partner Dependent 4
- Inactive 674
-
Admin Settings
20 -
AMP Engine
27 -
API
11 -
API SDK
218 -
Category Address
13 -
Category Apps
113 -
Category Behavior Analysis
5 -
Category Calgary
21 -
Category Connectors
245 -
Category Data Investigation
77 -
Category Demographic Analysis
2 -
Category Developer
208 -
Category Documentation
80 -
Category In Database
214 -
Category Input Output
640 -
Category Interface
239 -
Category Join
103 -
Category Machine Learning
3 -
Category Macros
153 -
Category Parse
76 -
Category Predictive
77 -
Category Preparation
394 -
Category Prescriptive
1 -
Category Reporting
198 -
Category Spatial
81 -
Category Text Mining
23 -
Category Time Series
22 -
Category Transform
88 -
Configuration
1 -
Content
1 -
Data Connectors
961 -
Data Products
2 -
Desktop Experience
1.533 -
Documentation
64 -
Engine
126 -
Enhancement
325 -
Feature Request
213 -
General
307 -
General Suggestion
6 -
Insights Dataset
2 -
Installation
24 -
Licenses and Activation
15 -
Licensing
12 -
Localization
8 -
Location Intelligence
80 -
Machine Learning
13 -
My Alteryx
1 -
New Request
192 -
New Tool
32 -
Permissions
1 -
Runtime
28 -
Scheduler
23 -
SDK
10 -
Setup & Configuration
58 -
Tool Improvement
210 -
User Experience Design
165 -
User Settings
79 -
UX
222 -
XML
7
- « Anterior
- Siguiente »
- TUSHAR050392 en: Read an Open Excel file through Input/Dynamic Inpu...
- AudreyMcPfe en: Overhaul Management of Server Connections
-
 AlteryxIdeasTea
AlteryxIdeasTeam en: Expression Editors: Quality of life update - StarTrader en: Allow for the ability to turn off annotations on a...
-
 AkimasaKajitani
en:
Download tool : load a request from postman/bruno ...
AkimasaKajitani
en:
Download tool : load a request from postman/bruno ...
- rpeswar98 en: Alternative approach to Chained Apps : Ability to ...
-
caltang
en:
Identify Indent Level
- simonaubert_bd en: OpenAI connector : ability to choose a non-default...
- maryjdavies en: Lock & Unlock Workflows with Password
- noel_navarrete en: Append Fields: Option to Suppress Warning when bot...
| Usuario | Cantidad |
|---|---|
| 9 | |
| 7 | |
| 6 | |
| 5 | |
| 4 |