Alteryx Designer Desktop Ideas
Share your Designer Desktop product ideas - we're listening!Submitting an Idea?
Be sure to review our Idea Submission Guidelines for more information!
Submission Guidelines- Community
- :
- Community
- :
- Participate
- :
- Ideas
- :
- Designer Desktop
Featured Ideas
Hello,
After used the new "Image Recognition Tool" a few days, I think you could improve it :
> by adding the dimensional constraints in front of each of the pre-trained models,
> by adding a true tool to divide the training data correctly (in order to have an equivalent number of images for each of the labels)
> at least, allow the tool to use black & white images (I wanted to test it on the MNIST, but the tool tells me that it necessarily needs RGB images) ?
Question : do you in the future allow the user to choose between CPU or GPU usage ?
In any case, thank you again for this new tool, it is certainly perfectible, but very simple to use, and I sincerely think that it will allow a greater number of people to understand the many use cases made possible thanks to image recognition.
Thank you again
Kévin VANCAPPEL (France ;-))
Thank you again.
Kévin VANCAPPEL
Hello all,
So, right now, we have two very separated products : Alteryx Designer and Alteryx Designer Cloud. But what if you want to go from Alteryx Designer on your desktop to the cloud ?
well, you will have to rewrite every single workflow because you can't publish or import your current workflow on Alteryx Designer Cloud. You cannot export Designer Cloud workflow to Alteryx Designer on Desktop either.
This is a huge limitation on cloud implementation and sells and the ONLY product I know that's not compatible between on-premise and cloud.
Please Alteryx, this is a no-brainer situation if you want to convince your customers !
Best regards,
Simon
Our team was very excited with the deployment of Alteryx One Enterprise Edition, but had to scratch our head on why DateTimeNow and Data Cleansing is available to Full Users but not Basic Users. What had us scratching our heads further, is Designer Cloud for Basic Users have DateTimeNow and Data Cleansing.
Hopefully the community and Alteryx can agree these are basic tools for everyone!
Alteryx Help References:
Alteryx>Alteryx One Editions>User Roles>Basic User Role>Basic User Capabilities
Alteryx>Alteryx One Editions>User Roles>Full User Role>Full User Capabilities
Alteryx>Alteryx One Platform Editions>Enterprise Edition>Enterprise Edition Capabilities
Hello,
As of today, DCM is great to store credentials. But once we want to dive deeper in technicity, like using macros or Applications, it's really bad. One of the things I hate is that we can't retrieve any informations from the DCM connection, just the id. Not good for logs, really bad for understanding and have some conditional logic related to connection type or name.
Here an example


Nice, I managed to retrieve an id but I have no idea of what it means : what kind of connection? what's name?
Best regards,
Simon

I'm not sure if this will ever be possible, but I know that it would greatly benefit me and I'm sure thousands of other users. In my work place I am constantly working in a conference room and at my desk. At my desk I am wired into an Ethernet connection while in the conference room I am wireless. When I start my workflows after working with my team in the conference room, I can't go back to my desk until the workflow is finished running because I am changing internet connections and I lose connection to the databases. With the pause button it would become possible to run a workflow and then change my internet without losing connection to the databases.
Another use for this would be while testing a workflow with a new tool. There are times I run a workflow that can take a few hours, but then I realize there is a mistake somewhere in my workflow, where the data hasn't reached yet. I think it would be very helpful to be able to pause the workflow and add the new tool in, while seeing results from tools it has already passed through.
But yet again this is just an idea that relates to me, I wonder what the rest of the community thinks.
Many users will probably follow best practice style guides with Alteryx to use comment boxes under tools to describe in detail what is happening with these tools - such as this one shared by @BenMoss.
However a limitation of this is the comment boxes do not move with the tools, so if you have a well documented workflow but then need to add a new tool, you need to adjust all the spacing and re-align the tools, which with a large workflow can be time consuming.

Therefore the improvement would be to have an ability to lock comment boxes to individual tools (similar to a group function in Office).
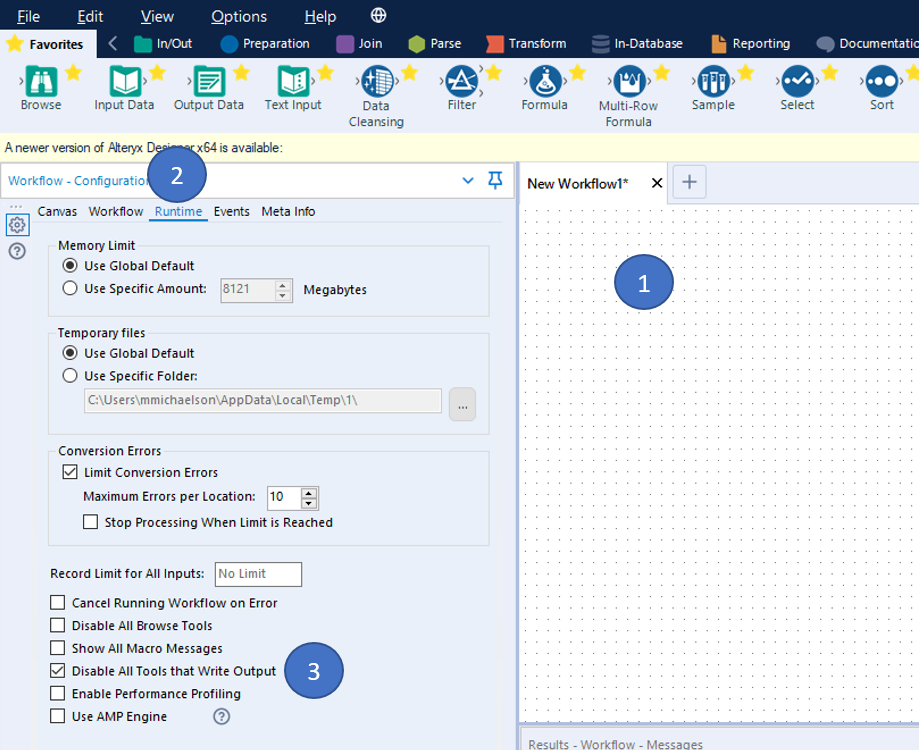
Today, there is an checkbox to "Disable All Tools that Write Output" within the Runtime settings for a workflow. Setting this option requires at least 3 clicks:
- Click on the canvas
- Click the "Runtime" tab in the Configuration pane
- Click the checkbox
Could a keyboard shortcut be added for this? I've spoken to several users who leverage this feature and, while it is already a time saver, it seems helpful enough where a keyboard shortcut is warranted.
Hello all,
We all have experienced these last years the now famous concept of hide/unhide password :
Here a few examples of it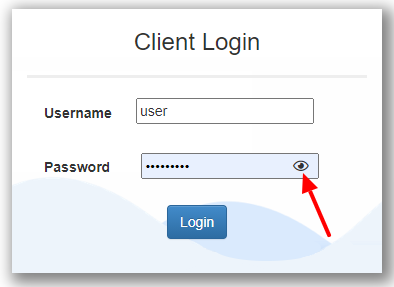
I would like this exact principle everywhere we have a password on Alteryx.
Best regards,
Simon

Hello all,
According to wikipedia :
https://en.wikipedia.org/wiki/Join_(SQL)
CROSS JOIN returns the Cartesian product of rows from tables in the join. In other words, it will produce rows which combine each row from the first table with each row from the second table.[1]
Example of an explicit cross join:
SELECT *
FROM employee CROSS JOIN department;
Example of an implicit cross join:
SELECT *
FROM employee, department;
The cross join can be replaced with an inner join with an always-true condition:
SELECT *
FROM employee INNER JOIN department ON 1=1;
For us, alteryx users, it would be very similar to Append Fields but for in-db.
Best regards,
Simon
In the Input tool, I rely heavily on the recent connection history list. As soon as a file falls off of this list, it takes me a while to recall where it's saved and navigate to the file I'm wanting to use. It would be great to have a feature that would allow users to set their favorite connections/files so that they remain at the top of the connection history list for easy access.

Hello all,
As of today, we use the good old alias in-memory to connect to our datasources in in-memory. We have several environments so we use constants in order to change the name of the in-memory alias during execution.
To illustrate :

Depending of the environment, the constant « v_gp_contexte » will take different values :
- GP_DS08_SIDATA for la dev.
- GP_EE_SIDATA for prod.
Sounds nice, right? But now, we would like to use DCM and the nightmare begins :
We can't manually change the name and set the question :

if we look at the xml of the workflow, we only find an id so editing it is useless :

(for informationDCM connections are stored in some sqlite db in C:\Users\{yourname}\AppData\Local\Alteryx
So, I would like to use the DCM inside the in-memory alias (the in-memory alias is stored and can be edited), just like for in-db connection alias.
Best regards,
Simon
Hello all,
According to wikipedia https://en.wikipedia.org/wiki/Materialized_view
In computing, a materialized view is a database object that contains the results of a query. For example, it may be a local copy of data located remotely, or may be a subset of the rows and/or columns of a table or join result, or may be a summary using an aggregate function.
The process of setting up a materialized view is sometimes called materialization.[1] This is a form of caching the results of a query, similar to memoization of the value of a function in functional languages, and it is sometimes described as a form of precomputation.[2][3] As with other forms of precomputation, database users typically use materialized views for performance reasons, i.e. as a form of optimization.
So, I would like to create that in Alteryx, for obvious performance reasons in some use cases.
This is not a duplicate of https://community.alteryx.com/t5/Alteryx-Designer-Desktop-Ideas/In-DB-Create-View/idi-p/157886
Best regards,
Simon
Hello all,
According to wikipedia :
https://en.wikipedia.org/wiki/Embedded_database
An embedded database system is a database management system (DBMS) which is tightly integrated with an application software; it is embedded in the application.
It's often like a single file/dll that you can use inside an application without the user having to connect (or at least to configure it) to it (it's all done inside the application). So, it's widely portable.
Why it does matter ?
As of today, there is not a single example of in database workflow because all the supported databases need the user to:
1/install an odbc driver (most of time, he won't have the rights to do so)
2/configure an odbc connection (sometimes, he doesn't have the rights to)
3/configure a connection on Alteryx (ok, he can)
So it requires IT action, which can be pretty long (in ùany organization, it requires several weeks !!). And even with all of that,the users must be granted privilege to access database and the customer need to develop its own examples and write its own specific documentation.
Well, this is not efficient.
What I suggest is Alteryx to use one of embedded database for training support/one tool examples. SQLlite seems good, maybe a more analytics oriented (like DuckDB ) would be more efficient.
The requirement are, I think, the following :
-OpenSource and free
-Fast
-SQL compliant
-With a bulk load ability
Best regards,
Simon
Hello all,
Apache Doris ( https://doris.apache.org/ ) is a modern datawarehouse with a lot of ambitions. It's probably the next big thing.

You can read the full doc here https://doris.apache.org/docs/get-starting/what-is-apache-doris but to sum it up, it aims to be THE reference solution for OLAP by claiming even better performance than Clickhouse, DuckDB or MonetDB. Even benchmarks from the Clickhouse team seem to agree.
Best regards,
Simon
I'd like to see Alteryx allow a second install of your license on a second, personal machine. Tableau allows this and IMO is why there is such a robust online / blog community around that product.
For those of us that work at mid-size to large organizations, there are often strict rules governing internal data and use of cloud-based data sources. If I discover some new trick I'd like the share with my fellow Alteryx analysts outside of my company, I have no clear way to do that the same way I can with Tableau where I can do it at home not using my company's data.
Being able to learn new features and test things out on commonly available public data (ever notice that Superstore data set everyone who gets Tableau has?) would accelerate what we're able to do with the community site here and the larger analytics blogging community.
Hello all,
As of today, when you want to retrieve or create a file on Apache Spark for Databricks, you have only two choices : CSV and Avro
However it's clearly missing parquet file type :
-it's faster
-it's better for storage
-it's standard and already supported as input/output of Alteryx or for HDFS so doesn't seem hard to add here.
Best regards,
Simon

To increase Performance on some old Buissness Logic, i am trying to switch an existing system to In-DB tools. This has given me a lot of headache because there is no Multi-Field Formular Tool in the In-DB section. It is a very tedious job to run through every workflow to manually set the same regex for a table with more than 20 Fields.
I have had the idea to implement such a tool myself but i think this could be helpful for other developers in Alteryx Desktop too, so i am bringing this up here.
The Idea is to have a similar approach to the new Multi-Formular Tool like the other already existing Tool in Preperation.
Additional formatting functionality would be great to see in the Interface Designer.
First off, I want to acknowledge other submitted ideas (vote for them too!):
- Allow Drag and Drop in Interface Designer - Alteryx Community
- Alteryx Interface Designer - Place Element Where S... - Alteryx Community
Both of these are great suggestions and I want to show support of them as well!
To take it another step further from targeted placement or drag/drop... I would also like to see new objects included in the ADD menu. We have Groupings but I'd like to see horizontally split groupings. Meaning, I want the ability to place two Date Inputs next to each other, or short prompts across instead of listed vertically.
Example:

Why this matters: If Alteryx aspires to be a bonofied contender in the Analytic Application space (which I think it is), then we need added functionality that puts a greater emphasis on the user-experience side of things. Because as we know, user acceptance, ease of use, and adoption all depend on a clean presentation for the elements they interract with.
If you agree, your "thumbs up" of support is only one click away!
I’ve been using the Regex tool more and more now. I have a use case which can parse text if the text inside matches a certain pattern. Sometimes it returns no results and that is by design.
Having the warnings pop up so many times is not helpful when it is a genuine miss and a fine one at that.
Just like the Union tool having the ability to ignore warnings, like Dynamic Rename as well, can we have the ignore function for all parse tools?
That’s the idea in a nutshell.
Hello,
Unless you're lucky, your input dataset can have fields with the wrong types. That can lead to several issues such as :
-performance (a string is waaaaaaaay slower than let's say a boolean)
-compliance with master data management
-functional understanding (e.g : if i have a field called "modified" typed as string, I don't know if it contains the modification date, an information about the modification, etc... while if it's is typed as date, I already know it's a date)
-ability to do some type-specific operations (you can't multiply a string or extract a week from a string)
right now, the existing tools have been focused on strings but I think we can do better.
Here a proposition :
entry : a dataframe
configuration :
-selection of fields
or
-selection of field types
-ability to do it on a sample (optional)
Algo :
| Alteryx | Byte | bool | only 2 values. 0 and 1 | to be done |
| Alteryx | Int16 | bool | only 2 values. 0 and 1 | to be done |
| Alteryx | Int16 | Byte | min=>0, max <=255 | to be done |
| Alteryx | Int32 | bool | only 2 values. 0 and 1 | to be done |
| Alteryx | Int32 | Byte | min>=0, max <=255 | to be done |
| Alteryx | Int32 | Int16 | min>=-32,768, max <=32,767 | to be done |
| Alteryx | Int64 | bool | only 2 values. 0 and 1 | to be done |
| Alteryx | Int64 | Byte | min>=0, max <=255 | to be done |
| Alteryx | Int64 | Int16 | min>=-32,768, max <=32,767 | to be done |
| Alteryx | Int64 | Int32 | min>=-–2,147,483,648, max <=2,147,483,647 | to be done |
| Alteryx | Fixed Decimal | bool | only 2 values. 0 and 1 | to be done |
| Alteryx | Fixed Decimal | Byte | No decimal part, min>=0, max <=255 | to be done |
| Alteryx | Fixed Decimal | Int16 | No decimal part, min>=-32,768, max <=32,767 | to be done |
| Alteryx | Fixed Decimal | Int32 | No decimal part, min>=-–2,147,483,648, max <=2,147,483,647 | to be done |
| Alteryx | Fixed Decimal | Int36 | No decimal part, min>=-––9,223,372,036,854,775,808, max <=9,223,372,036,854,775,807 | to be done |
| Alteryx | Float | bool | only 2 values. 0 and 1 or 0,-1 | to be done |
| Alteryx | Float | Byte | No decimal part, min>=0, max <=255 | to be done |
| Alteryx | Float | Int16 | No decimal part, min>=-32,768, max <=32,767 | to be done |
| Alteryx | Float | Int32 | No decimal part, min>=-–2,147,483,648, max <=2,147,483,647 | to be done |
| Alteryx | Float | Int36 | No decimal part, min>=-––9,223,372,036,854,775,808, max <=9,223,372,036,854,775,807 | to be done |
| Alteryx | Float | Fixed Decimal | to be done | to be done |
| Alteryx | Double | bool | only 2 values. 0 and 1 or 0,-1 | to be done |
| Alteryx | Double | Byte | No decimal part, min>=0, max <=255 | to be done |
| Alteryx | Double | Int16 | No decimal part, min>=-32,768, max <=32,767 | to be done |
| Alteryx | Double | Int32 | No decimal part, min>=-–2,147,483,648, max <=2,147,483,647 | to be done |
| Alteryx | Double | Int36 | No decimal part, min>=-––9,223,372,036,854,775,808, max <=9,223,372,036,854,775,807 | to be done |
| Alteryx | Double | Fixed Decimal | to be done | to be done |
| Alteryx | Double | Float | when no need for doube precision | to be done |
| Alteryx | DateTime | Date | no hours, minutes, seconds | to be done |
| Alteryx | String | bool | only 2 values. 0 and 1 or 0,-1 or True/False or TRUE/FALSE or equivalent in some languages such as VRAI/FAUX, Vrai/Faux | to be done |
| Alteryx | String | Byte | No decimal part, min>=0, max <=255 | to be done |
| Alteryx | String | Int16 | No decimal part, min>=-32,768, max <=32,767 | to be done |
| Alteryx | String | Int32 | No decimal part, min>=-–2,147,483,648, max <=2,147,483,647 | to be done |
| Alteryx | String | Int36 | No decimal part, min>=-––9,223,372,036,854,775,808, max <=9,223,372,036,854,775,807 | to be done |
| Alteryx | String | Fixed Decimal | to be done | to be done |
| Alteryx | String | Float | when no need for doube precision | to be done |
| Alteryx | String | Double | when need for double precision | to be done |
| Alteryx | String | Date | test on several date formats | to be done |
| Alteryx | String | Time | test on several time formats | to be done |
| Alteryx | String | DateTime | test on several datetime formats | to be done |
| Alteryx | WString | bool | only 2 values. 0 and 1 or 0,-1 or True/False or TRUE/FALSE or equivalent in some languages such as VRAI/FAUX, Vrai/Faux | to be done |
| Alteryx | WString | Byte | No decimal part, min>=0, max <=255 | to be done |
| Alteryx | WString | Int16 | No decimal part, min>=-32,768, max <=32,767 | to be done |
| Alteryx | WString | Int32 | No decimal part, min>=-–2,147,483,648, max <=2,147,483,647 | to be done |
| Alteryx | WString | Int36 | No decimal part, min>=-––9,223,372,036,854,775,808, max <=9,223,372,036,854,775,807 | to be done |
| Alteryx | WString | Fixed Decimal | to be done | to be done |
| Alteryx | WString | Float | when no need for doube precision | to be done |
| Alteryx | WString | Double | when need for double precision | to be done |
| Alteryx | WString | String | Latin-1 character only | to be done |
| Alteryx | WString | Date | test on several date formats | to be done |
| Alteryx | WString | Time | test on several time formats | to be done |
| Alteryx | WString | DateTime | test on several datetime formats | to be done |
| Alteryx | V_String | bool | only 2 values. 0 and 1 or 0,-1 or True/False or TRUE/FALSE or equivalent in some languages such as VRAI/FAUX, Vrai/Faux | to be done |
| Alteryx | V_String | Byte | No decimal part, min>=0, max <=255 | to be done |
| Alteryx | V_String | Int16 | No decimal part, min>=-32,768, max <=32,767 | to be done |
| Alteryx | V_String | Int32 | No decimal part, min>=-–2,147,483,648, max <=2,147,483,647 | to be done |
| Alteryx | V_String | Int36 | No decimal part, min>=-––9,223,372,036,854,775,808, max <=9,223,372,036,854,775,807 | to be done |
| Alteryx | V_String | Fixed Decimal | to be done | to be done |
| Alteryx | V_String | Float | when no need for doube precision | to be done |
| Alteryx | V_String | Double | when need for double precision | to be done |
| Alteryx | V_String | String | Same length | to be done |
| Alteryx | V_String | Date | test on several date formats | to be done |
| Alteryx | V_String | Time | test on several time formats | to be done |
| Alteryx | V_String | DateTime | test on several datetime formats | to be done |
| Alteryx | V_WString | bool | only 2 values. 0 and 1 or 0,-1 or True/False or TRUE/FALSE or equivalent in some languages such as VRAI/FAUX, Vrai/Faux | to be done |
| Alteryx | V_WString | Byte | No decimal part, min>=0, max <=255 | to be done |
| Alteryx | V_WString | Int16 | No decimal part, min>=-32,768, max <=32,767 | to be done |
| Alteryx | V_WString | Int32 | No decimal part, min>=-–2,147,483,648, max <=2,147,483,647 | to be done |
| Alteryx | V_WString | Int36 | No decimal part, min>=-––9,223,372,036,854,775,808, max <=9,223,372,036,854,775,807 | to be done |
| Alteryx | V_WString | Fixed Decimal | to be done | to be done |
| Alteryx | V_WString | Float | when no need for doube precision | to be done |
| Alteryx | V_WString | Double | when need for double precision | to be done |
| Alteryx | V_WString | String | Same length,latin- character only | to be done |
| Alteryx | V_WString | WString | Same length | to be done |
| Alteryx | V_WString | V_String | latin- character only | to be done |
| Alteryx | V_WString | Date | test on several date formats | to be done |
| Alteryx | V_WString | Time | test on several time formats | to be done |
| Alteryx | V_WString | DateTime | test on several datetime formats | to be done |
The output would be something like that
| Field | Input type | Proposition | Conversion |
| toto | float | int | formula (with example)/native tool/datetime conversion tool… |
Best regards,
Simon
Very often, I used a container to make notes about certain parts of the workflow. Some of the comments that I created are pretty long. Could the user have the possibility to have at least rows for the title of the container?

I have created a screen to show what I have in mind. Potentially users could have the ability to turn this option on or inside the container?

{kind=link}
- New Idea 395
- Accepting Votes 1,783
- Comments Requested 20
- Under Review 181
- Accepted 47
- Ongoing 7
- Coming Soon 13
- Implemented 550
- Not Planned 106
- Revisit 56
- Partner Dependent 3
- Inactive 674
-
Admin Settings
22 -
AMP Engine
27 -
API
11 -
API SDK
230 -
Bug
1 -
Category Address
13 -
Category Apps
114 -
Category Behavior Analysis
5 -
Category Calgary
21 -
Category Connectors
252 -
Category Data Investigation
79 -
Category Demographic Analysis
3 -
Category Developer
220 -
Category Documentation
82 -
Category In Database
215 -
Category Input Output
658 -
Category Interface
246 -
Category Join
109 -
Category Machine Learning
3 -
Category Macros
156 -
Category Parse
78 -
Category Predictive
79 -
Category Preparation
406 -
Category Prescriptive
2 -
Category Reporting
205 -
Category Spatial
83 -
Category Text Mining
23 -
Category Time Series
24 -
Category Transform
93 -
Configuration
1 -
Content
2 -
Data Connectors
985 -
Data Products
4 -
Desktop Experience
1,615 -
Documentation
64 -
Engine
136 -
Enhancement
421 -
Event
1 -
Feature Request
219 -
General
307 -
General Suggestion
8 -
Insights Dataset
2 -
Installation
26 -
Licenses and Activation
15 -
Licensing
15 -
Localization
8 -
Location Intelligence
82 -
Machine Learning
13 -
My Alteryx
1 -
New Request
229 -
New Tool
32 -
Permissions
1 -
Runtime
28 -
Scheduler
26 -
SDK
10 -
Setup & Configuration
58 -
Tool Improvement
210 -
User Experience Design
165 -
User Settings
87 -
UX
228 -
XML
7
- « Previous
- Next »
-
 Carolyn
on:
Blob output to be turned off with 'Disable all too...
Carolyn
on:
Blob output to be turned off with 'Disable all too...
- MJ on: Add Tool Name Column to Control Container metadata...
-
fmvizcaino
on:
Show dialogue when workflow validation fails
- ANNE_LEROY on: Create a SharePoint Render tool
- jrlindem on: Non-Equi Relationships in the Join Tool
- AncientPandaman on: Continue support for .xls files
- EKasminsky on: Auto Cache Input Data on Run
- jrlindem on: Global Field Rename: Automatically Update Column N...
- simonaubert_bd on: Workflow to SQL/Python code translator
- abacon on: DateTimeNow and Data Cleansing tools to be conside...
| User | Likes Count |
|---|---|
| 7 | |
| 3 | |
| 3 | |
| 3 | |
| 2 |