Alteryx Designer Desktop Ideas
Share your Designer Desktop product ideas - we're listening!Submitting an Idea?
Be sure to review our Idea Submission Guidelines for more information!
Submission Guidelines- Community
- :
- Community
- :
- Participate
- :
- Ideas
- :
- Designer Desktop: New Ideas
Featured Ideas
Hello,
After used the new "Image Recognition Tool" a few days, I think you could improve it :
> by adding the dimensional constraints in front of each of the pre-trained models,
> by adding a true tool to divide the training data correctly (in order to have an equivalent number of images for each of the labels)
> at least, allow the tool to use black & white images (I wanted to test it on the MNIST, but the tool tells me that it necessarily needs RGB images) ?
Question : do you in the future allow the user to choose between CPU or GPU usage ?
In any case, thank you again for this new tool, it is certainly perfectible, but very simple to use, and I sincerely think that it will allow a greater number of people to understand the many use cases made possible thanks to image recognition.
Thank you again
Kévin VANCAPPEL (France ;-))
Thank you again.
Kévin VANCAPPEL
In older versions, I could delete the text of an annotation. It didn't matter if I wrote it or if it was autogenerated. Now, I cannot remove the text of the annotation. Yes, I know that I can hide the annotation of that tool. I want to delete the text. I have to select all the text and replace it with a space. I don't know why this functionality changed. Please change it back.
Hello all,
I just love the DCM feature. However, you have to enable it manually in system settings after the install or the update.
I don't think there is a good reason for that and it would save time to enable it by default.

Best regards,
Simon
Under the Runtime setting, there is an existing option to "Disable All Tools that Write Output". This is incredibly useful when developing workflows when you don't want to overwrite existing files.
But this option doesn't disable all outputs, like Publishing to Tableau!
I suggest adding the option to disable ALL kinds of outputs, uploads, and publishing (except possibly logging and caching).
Hello,
please remove the hard limit of 5 output files from the Python tool, if possible.
It would be very helpful for the user to forward any amount of tables in any format with different columns each.
Best regards,
Hello,
the Python scripts sometimes get lost or updated when the user forgets to save his/her Jupyter notebook.
Please enhance.
Thanks and best regards,
Fabian Rudolf
Current issue with Alteryx Software is that each time an Alteryx file is opened it tries to establish a connection with Database or File. This results in:
- Lockout situations when Enterprise password is changed
- No ability to share Alteryx Workflows with Colleagues (when they open it will have author of files credentials resulting in locking out author)
- Countless phone calls with Enterprise IT to reset password.
Should be a feature/enhancement that we can either toggle on/off whether we want our flows to establish connection with data source/file when we first open the Alteryx file. This toggle would save countless time and effort from developers when working with secured connections that require credentials.
Hello! I'm just wanting to highlight a couple of small issues I've found when trying to use the TS Covariate Forecast.
1. The example workflow does not open. This has been tested on multiple machines with different users. Right clicking the macro allows for the option 'Open Example Workflow':
However the button does not work/do anything. It is listed as a tool with a 'one tool example' (https://help.alteryx.com/20213/designer/sample-workflows-designer) so i would expect this to work.
2. Fix left/right labelling of input anchors. Currently the anchors are labelled incorrectly (compared with the join tool):


This can make things confusing when looking at documentation/advice on the tool, in which it is described as the left/right inputs.
Thanks!
TheOC
A few suggestions that I think can improve the Sharepoint Files Output Tool:
- Maybe I'm missing it, but I cannot see how you can delete a file from the output list once you've added it:
- Have the write headers output checkbox ticked by default as I expect this is the more common expectation:
- Take the file extension by default based on the users selection in the Options tab as I shouldn't have to write .xlsx for the extension:




Reporting automation capability is absolutely a great feature that puts Alteryx far ahead its competitors.
Unfortunately, Alteryx reporting tools start to become old fashioned in terms of :
- look & feel
- charts library
- charts configuration
It would be great if Alteryx could redesigned its reporting tools in order to allow the generation of smashing, flashy, modern visualizations mixing nice charts and maps.
Many thanks !
Hello,
I discussed with Alteryx support via email and they informed to post on here for a possible enhancement to Alteryx.
The issue I'm facing is that in raw data coming from SAP, the raw column names have carriage returns in them.
In Alteryx, in the display window, it will just show the first line before the carriage return and not the rest of the text, even though the text is all in one cell in Excel.
In Alteryx, I also tried exporting the file and it will just show the first line before the carriage return and not the rest of the text, even though the text is all in one cell in Excel.
However, when using any tools, the full column names are displayed.
An enhancement would be for the display window and export tool to have the full column names displayed.
Add ability to lock comment boxes size, shape, position (send to back), location on the canvas. This would allow a developer to use a template when creating workflow without accidently selecting and/or adjusting these attributes. It will also allow a user to put a tool over the top of the comment box without fear of messing up the visual display of the workflow or it getting hidden underneath the comment box.
I've obviously been doing lots of work with APIs for this to be my second idea posted today which relates to an improved based on recent work with APIs, but I also believe this is wider reaching.
I've been using Alteryx now for over 4 years and always assumed implicit behaviour of the select tool, so would add a select tool as best practice into a workflow after input tools to catch any data type issues. However I discovered that only fields where you either change the data type, length or field name result in that behaviour being configured and subsequently ensured. I discovered this as part of API development where I had an input field which was a string e.g. 01777777. Placing a select tool after this shows this is a string data type, however if the input was changed to 11777777 the select tool changes to a numeric data type. Therefore downstream formulas such as concatenating two strings would fail.
The workaround to this is to change the select tool to string:forced, which is fine when you know about it, but I suspect that a large majority of users don't. Plus if you have something like 2022-01-26 which is recognised initially as a string, then the forced option will be string:forced, however if you wanted it to be date:forced you need to add a first select tool to change to date, and a second select tool to change to string:forced.
Therefore my suggestion is to add a checkbox option in the select tool to Force all field types, which would update the xml of the tool and therefore ensure what I currently assume would be implicit behaviour is actually implemented.
When working with APIs it is quite common to use the JSON parse tool to parse out the download data which has been returned from the API. However the JSON data may be missing key:value pairs as they are not in the response. This causes issues with downstream tools where there are missing fields. The current workaround for this is to use either the Crew macro Ensure fields, or union on a text input file to force the missing fields downstream.
The issue with this is:
1) Users may not be aware of the requirement to ensure fields are present
2) You need to know the names of all the fields to include in the ensure fields macro
Therefore the feature request is to add an option to the JSON parse tool to add the model schema as an input.
For example with the UK companies house API, to get a list of all the directors at a company the model schema is
{
"active_count": "integer",
"etag": "string",
"items": [
{
"address": {
"address_line_1": "string",
"address_line_2": "string",
"care_of": "string",
"country": "string",
"locality": "string",
"po_box": "string",
"postal_code": "string",
"premises": "string",
"region": "string"
},
"appointed_on": "date",
"country_of_residence": "string",
"date_of_birth": {
"day": "integer",
"month": "integer",
"year": "integer"
},
"former_names": [
{
"forenames": "string",
"surname": "string"
}
],
"identification": {
"identification_type": "string",
"legal_authority": "string",
"legal_form": "string",
"place_registered": "string",
"registration_number": "string"
},
"links": {
"officer": {
"appointments": "string"
},
"self": "string"
},
"name": "string",
"nationality": "string",
"occupation": "string",
"officer_role": "string",
"resigned_on": "date"
}
],
"items_per_page": "integer",
"kind": "string",
"links": {
"self": "string"
},
"resigned_count": "integer",
"start_index": "integer",
"total_results": "integer"
}
But fields such as "resigned_on" are not always present in the data if there are no directors who have resigned. Therefore to avoid a user missing the requirement for unidentified fields needing to be added, if there was an optional input which took the model schema and therefore created the missing fields would greatly improve the API development process and minimise future errors being encountered once a workflow is in production.
Hi there Alteryx team,
When we load data from raw files into a SQL table - we use this pattern in almost every single loader because the "Update, insert if new" functionality is so slow; it cannot take advantage of SSVB; it does not do deletes; and it doesn't check for changes in the data so your history tables get polluted with updates that are not real updates.
This pattern below addresses these concerns as follows:
- You explicitly separate out the inserts by comparing to the current table; and use SSVB on the connection - thereby maximizing the speed
- The ones that don't exist - you delete, and allow the history table to keep the history.
- Finally - the rows that exist in both source and target are checked for data changes and only updated if one or more fields have changed.
Given how commonly we have to do this (on almost EVERY data pipe from files into our database) - could we look at making an Incremental Update tool in Alteryx to make this easier? This is a common functionality in other ETL platforms, and this would be a great addition to Alteryx.

The Sharepoint file tools are certainly a step in the right direction, but it would be great to enhance the files types that it is possible to write to sharepoint from Alteryx.
The format missing that I think is probably most in demand is pdf. If we're using the Alteryx reporting suite to create PDF reports, it would be awesome to have an easy way to output these to Sharepoint.
https://help.alteryx.com/20213/designer/sharepoint-files-output-tool
https://community.alteryx.com/t5/Public-Community-Gallery/Sharepoint-Files-Tool/ta-p/877903
Hello all,
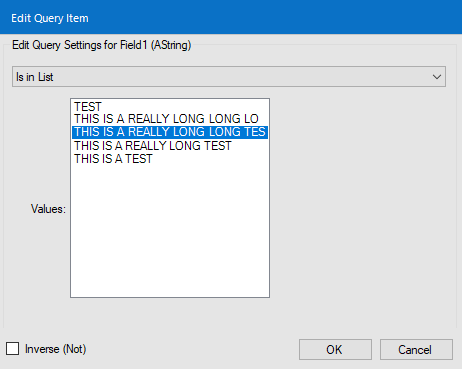
Here the issue : when you have a lot of tables, the Visual Query Builder can be very slow. On my Hive Database, with hundreds of tables, I have the result after 15 minutes and most of the time, it crashes, which is clearly unusable.
I can change the default interface in the Visual Query Builder tool but for changing this setting, I need to load all the tables in the VQB tool.
I would like to set that in User Settings to set it BEFORE opening the Visual Query Builder.

Best regards,
Simon
After talking with support we found out that Oracle Financial Cloud ERP is not listed among supported Data Sources as stated in the url below:
We would like this added as our company will begin working heavily with Oracle Financial Cloud ERP to bring data from that into our SQL servers. Is there a reason why that connection is not currently being investigated and set up?
Thanks,
Chris
Hi, I was using the Image Template tool and I noticed that the icons for import and export are switched.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- New Idea 272
- Accepting Votes 1,818
- Comments Requested 24
- Under Review 174
- Accepted 56
- Ongoing 5
- Coming Soon 11
- Implemented 481
- Not Planned 116
- Revisit 62
- Partner Dependent 4
- Inactive 674
-
Admin Settings
20 -
AMP Engine
27 -
API
11 -
API SDK
218 -
Category Address
13 -
Category Apps
113 -
Category Behavior Analysis
5 -
Category Calgary
21 -
Category Connectors
245 -
Category Data Investigation
77 -
Category Demographic Analysis
2 -
Category Developer
208 -
Category Documentation
80 -
Category In Database
214 -
Category Input Output
640 -
Category Interface
239 -
Category Join
103 -
Category Machine Learning
3 -
Category Macros
153 -
Category Parse
76 -
Category Predictive
77 -
Category Preparation
394 -
Category Prescriptive
1 -
Category Reporting
198 -
Category Spatial
81 -
Category Text Mining
23 -
Category Time Series
22 -
Category Transform
88 -
Configuration
1 -
Content
1 -
Data Connectors
961 -
Data Products
2 -
Desktop Experience
1,533 -
Documentation
64 -
Engine
126 -
Enhancement
325 -
Feature Request
213 -
General
307 -
General Suggestion
6 -
Insights Dataset
2 -
Installation
24 -
Licenses and Activation
15 -
Licensing
12 -
Localization
8 -
Location Intelligence
80 -
Machine Learning
13 -
My Alteryx
1 -
New Request
192 -
New Tool
32 -
Permissions
1 -
Runtime
28 -
Scheduler
23 -
SDK
10 -
Setup & Configuration
58 -
Tool Improvement
210 -
User Experience Design
165 -
User Settings
79 -
UX
222 -
XML
7
- « Previous
- Next »
- TUSHAR050392 on: Read an Open Excel file through Input/Dynamic Inpu...
- AudreyMcPfe on: Overhaul Management of Server Connections
-
 AlteryxIdeasTea
AlteryxIdeasTeam on: Expression Editors: Quality of life update - StarTrader on: Allow for the ability to turn off annotations on a...
-
 AkimasaKajitani
on:
Download tool : load a request from postman/bruno ...
AkimasaKajitani
on:
Download tool : load a request from postman/bruno ...
- rpeswar98 on: Alternative approach to Chained Apps : Ability to ...
-
caltang
on:
Identify Indent Level
- simonaubert_bd on: OpenAI connector : ability to choose a non-default...
- maryjdavies on: Lock & Unlock Workflows with Password
- noel_navarrete on: Append Fields: Option to Suppress Warning when bot...