Alteryx Designer Desktop Ideas
Share your Designer Desktop product ideas - we're listening!Submitting an Idea?
Be sure to review our Idea Submission Guidelines for more information!
Submission Guidelines- Community
- :
- Community
- :
- Participate
- :
- Ideas
- :
- Designer Desktop: Hot Ideas
Featured Ideas
Hello,
After used the new "Image Recognition Tool" a few days, I think you could improve it :
> by adding the dimensional constraints in front of each of the pre-trained models,
> by adding a true tool to divide the training data correctly (in order to have an equivalent number of images for each of the labels)
> at least, allow the tool to use black & white images (I wanted to test it on the MNIST, but the tool tells me that it necessarily needs RGB images) ?
Question : do you in the future allow the user to choose between CPU or GPU usage ?
In any case, thank you again for this new tool, it is certainly perfectible, but very simple to use, and I sincerely think that it will allow a greater number of people to understand the many use cases made possible thanks to image recognition.
Thank you again
Kévin VANCAPPEL (France ;-))
Thank you again.
Kévin VANCAPPEL
I was just responding to a post about the Make Columns tool, and I noticed that there is not an example workflow for this tool built into Designer. It is also missing from the Transform category, so I never think of it.


Could we please have a Type field added to the "Select Fields to Cleanse" configuration window for the Data Cleansing Tool? This small feature would save a lot of time (saving the time needed to check the Metadata for every field every time I use the Data Cleansing Tool). Similar functionality to the way the Summarize Tool displays both Field and Type (just one additional field).
Today:

Future Version:

Pardon my sad photoshopping 🙂
Note: I realize the Data Cleansing is a macro and this functionality is not currently available with the "Check Box" interface tool.
Thank you!
I think the undo/redo capabilities in Alteryx could be greatly improved. Here is an idea that I think would be beneficial...
I'd like to see which exact tools are affected by my undo/redo actions. An idea was suggested a couple years ago to move your location on the canvas, but that was not added to the roadmap. Instead, is it possible to add the tool ID to the undo menu so that it is obvious which tool each line is detailing?
This is the current debug menu that shows your previous actions:

When a tool is created, the ID can be displayed in this menu, but this is not shown when a change is made to an existing tool. My suggestion is that the menu would say:
4. Change Sort (3) Properties
This same change should be made in the Edit dropdown menu.

Hello,
As of today, when you connect o, a database, you go through a batch of queries to retrieve which database it is ( cf https://community.alteryx.com/t5/Alteryx-Designer-Ideas/Smart-Visual-Query-Builder-for-in-db-less-te... where I suggest a solution to speed up the process) and then, Alteryx queries the metadata. In order to get the column in each table, Alteryx use a SHOW TABLES and then loop on each table. This is really slow.
However, since Hive 3.0, an information_schema with the list of columns for each table is now available. I suggest to use the information_schema.columns instead of the time-consuming loop.

PS : I don't know if it's linked to the Active Query Builder, the third-party tool behind the Visual Query Builder. In that case, it would be a good idea to update it as suggested here https://community.alteryx.com/t5/Alteryx-Designer-Ideas/Update-Query-Builder-component/idi-p/799086
Best regards,
Simon
Hi there,
My idea comes when I've built an application, where user select filter from drop-down list. However it contains thousands of records, so it takes lot's of time to find desired record.
In Excel and MS Access when you use filter you can put many letter and filter shows rows that match the input. In Alteryx user can only put first letter, which is huge drawback to my users.
This is how it works in Excel:

Hope you like it!
This is a hybrid idea related to both posts regarding dynamic tool configuration during runtime / without having to run an analytic app.
What I would like to propose is a new optional connection type for the interface tools that can be updated with incoming connections (having a Q letter with white background), namely Drop Down, List Box, Tree and Map tools. This could be a simple R letter in a square for example, which would be located to the left of the incoming question anchor.
Use Case
Imagine an app where there are two control containers and three interface tools (Action tools excluded from the count) outside those containers, one of them is a Text Box connected to a filter tool (via an Action tool) in the first control container with the purpose of limiting the dataset by specifying a city for example, another one is a Numeric Up Down for limiting the dataset by the average transaction amounts that are greater than the specified amount. These two interface tools are contained in a Group Box in the Interface Designer.
The third interface tool is a Drop Down tool which obtains the values (which will be Store Name for this example) from the results of the Select tool (in the second control container that is connected to the output anchor of the first control container) that is connected to an incoming filter tool which is modified by the previously mentioned interface tools. Output anchor of this Select tool is connected to the hypothetical R anchor on the top of the Drop Down tool, which is then connected to an outgoing filter tool that is connected to a series of tools which ends with a Browse tool that displays basic KPI information for the store specified from the Drop Down tool.
The main difference of the R (Refresh) anchor from the Q anchor is that it will enable the user to dynamically update the incoming values (i.e., choices for a drop down tool) without having to run the workflow. Alteryx Designer will automatically execute only the tools necessary to be able to update the values (up to a certain point of the workflow only, which may also be indicated by the boundaries of the control containers containing the target tool) for the R anchor connected applicable Interface tools specified above. This will be possible by clicking the hypothetical confirm button (same appearance with the Apply Data Manipulations button) which only appears next to the Interface tools (or the Group Boxes containing them instead) that are automatically determined by Alteryx Designer to be providing downstream data to the the tools (T anchor of the Filter tool for example) sending values to the applicable Interface tools having an incoming R anchor connection.
I saw that a similar feature recently became available with Alteryx Analytics Cloud Platform with the App Builder product, and I think that Alteryx Designer Desktop could definitely benefit both from this feature and additional App Builder features (that can be adapted to Desktop counterpart) in the upcoming releases.
Hello,
As I mentioned in this previous idea : https://community.alteryx.com/t5/Alteryx-Designer-Ideas/Generic-In-database-connection-please-stop-i...
field mapping in generic in-db connection is based on Microsoft Sql Server. Given the specificity of MSQL Server field types, I would like to change that in order to at least be able to use another database. Without that, this feature has no sense at all.
Best regards,
Simon
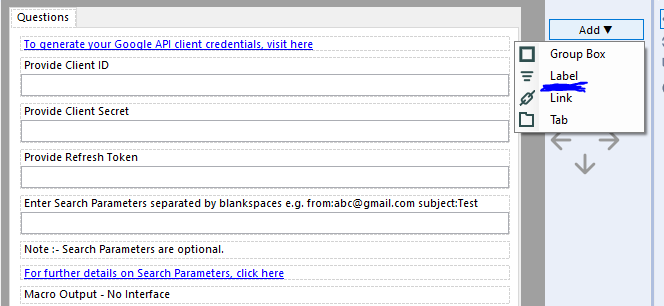
Hi all,
Is it possible to add an option to 'Add an Image' in the settings option of Interface Designer while building Apps or macros?
Currently, we can add Group box, Link, Tab, and Label. It would be really helpful if we can add static images as well!!
This would enable a developer to add an explanatory image just as a link or label is used to communicate to end user.
I am attaching a screenshot for the reference.

Thanks in advance!!
Regards,
Shreyansh Rathod
Alteryx has the ability to connect to data sources using fat clients and ODBC but not JDBC. If the ability to use JDBC could be added to the product it could remove the need to install fat clients.
Just like there is search bar for Select Tool, there should be one for Data Cleansing tool also.
With the growing demand for data privacy and security, synthetic data generation is becoming an increasingly popular technique for generating datasets that can be shared without compromising sensitive information especially in the healthcare industry.
While Alteryx provides a range of tools, I believe that a custom tool could help meet the specific needs of a lot of healthcare organizations and customers.
Some potential features of a custom synthetic data generation tool for Alteryx could include:
Integration with other Alteryx tools: The tool could be seamlessly integrated with other Alteryx tools to provide a comprehensive data preparation and analysis platform.
Customizable data generation: Users could set parameters and define rules for generating synthetic data that accurately represents the statistical properties of the original dataset.
Data visualization and exploration: The tool could include features for visualizing and exploring the generated data to help users understand and validate the results.
I believe that a custom synthetic data generation tool could help our organization and customers generate high-quality synthetic datasets for testing, model training, and other purposes.
It would be awesome if there was a cross tab in DB option because right now I have to stream out millions of records to build a cross tab.
Imagine the scenario where you have an input that has new columns everyday, like the one that can be seem above. But with millions of rows. And you need to build the Total column. This cannot be achieved with the formula tool, because the columns of the input are dynamic.
| Client | 20220101 | 20220102 | 20220103 | 20220104 | 20220105 | 20220106 | 20220107 | 20220108 | 20220109 | Total |
| 0000001 | 356 | 223 | 454 | 542 | 827 | 321 | 614 | 759 | 977 | 5628 |
...
The default way that i use and see people using to solve this type of problem is transposing the data/summarizing/joining back the data. I tested this with the Enable Performance Profiling for 10 million rows (workflow attached), and as expected, when you transpose/summarize/join back a large volume of rows, you spend too much computing power. For this test, at least 5x more time than by just using the formula tool (workflow attached):

So, what i propose here is:
1) That the Multi-Field formula could be able to evaluate a set of columns dynamically and generate just one new column (the sum of the evaluated columns, the concatenation of it...).
Example of Designer Discussion that would be benefit from it: https://community.alteryx.com/t5/Alteryx-Designer-Discussions/Transposing-Filtering-and-Summarizing-...
2) That the Multi-Field formula could be able to reference column-1, column-2, column+1, column+2, like the Multi-Row formula is.
Example of Designer Discussion that would benefit from it: https://community.alteryx.com/t5/Alteryx-Designer-Discussions/Copy-Field-and-create-two-mor-fields-w...
Thanks.
Currently, when one uses the Google BigQuery Output tool, the only options are to create a table, or append data to an existing table. It would be more useful if there was a process to replace all data in the table rather than appending. Having the option to overwrite an existing table in Google BigQuery would be optimal.
I use the field name auto-complete feature whenever I can. One issue with it, however, is when there are parentheses in a field name. After auto-completing the field name, Alteryx highlights a portion of the field name after the first parenthesis. This is not ideal as I typically expect the cursor to be at the end of the field name so I may continue to type. In this scenario, unfortunately, I would begin to type over my field name and the expression gets messed up.
For example, as shown below, I begin to type "st" and then hit the tab button to complete the field name in my expression.

In this case, because my field name has parentheses in it, however, some of the field name remains highlighted and the cursor does not go to the end of the right bracket, as one would expect.

If I were to continue typing at this point, the highlighted portion of the expression would get erased and replaced.
Field names that do not contain parentheses continue to function correctly as shown below.


{kind=link}
Similar to the thoughts in this idea, it would be great if the parenthesis matching functionality could be added to the formula tool as well.
I like the new cache option in 2018.3, but I would like it to function a little bit different. Let's say you cache at a certain point and then continue to build after that. If I reach another checkpoint and want to cache, it currently re-runs the entire workflow (ie it ignores my cache upstream and just goes back to the beginning of the workflow); instead, I would rather have it utilize the upstream cache. Personally, caching is usually an iterative effort during development where I keep caching along the way. The current functionality of the cache is not conducive to this. Thanks!
Given the prevalence of XML - it seems that it's worth adding a native XML capability to Alterxy (similar to the discussion with @CharleyMcGee and @KaneG in the discussion forum). Currently XML is treated mostly like a big and oddly behaved text field, which really undermines the usefulness of XML in real applications.
What I'm thinking is:
- Add in a component, which acts like a join, but what it does is validates an XML file vs. an XSD file so that you can see if your XML file matches the schema definition. Tremendously useful if you've ever had to hand-craft XML.
- Add in a native data-type for XML (like you have a data-type for Centroids)
- On this XML data type - you can then do interesting things like walk the document object model, or iterate through all children (which fixes the issue of deeply nested XML being such a pain). This would bring XML parsing into the level of usefulness that programmers in Java & Visual Studio have enjoyed for years
- Finally - an ability to construct XML data files without having to text-hack this. i.e. something similar to the transpose tool, where for a given node, you can add children etc.
These four things would really really assist with getting Alteryx to be able to deal with modern data sets like JSON; XML and even web-page scrubbing.
As always - very happy to commit time to helping shape this - please feel free to reach out if that would be useful.
Thank you all
Sean
CC: @JoeM; @mceleavey; @MarqueeCrew; @NeilR; @Ned; @dawid_nawrot; @TaraM; @GeneR
There needs to be a way to step into macro a which is component of parent workflow for debugging.
Currently the only way to achieve to debug these is to capture the inputs to the macro from the parent workflow, and then run the amend inputs on the macro. For iterative / batch macros, there is no option to debug at all. This can be tedious, especially if there are a number of inputs, large amounts of data, or you are have nested macros.
There should be an option on the tool representing the macro in the parent workflow to trigger a Debug when running the workflow, this would result in the same behavior when choosing 'Debug' from the interface panel in the macro itself: a new 'debug' workflow is created with the inputs received from the parent workflow.
On iterative / batch macros, which iteration / control parameter value the debug will be triggered on should be required. So if a macro returns an error on the 3 iteration, then the user ticks 'Debug' and Iteration = 3. If it doesn't reach the 3rd iteration, then no debug workflow is created.
Under the Runtime setting, there is an existing option to "Disable All Tools that Write Output". This is incredibly useful when developing workflows when you don't want to overwrite existing files.
But this option doesn't disable all outputs, like Publishing to Tableau!
I suggest adding the option to disable ALL kinds of outputs, uploads, and publishing (except possibly logging and caching).
- New Idea 272
- Accepting Votes 1,818
- Comments Requested 24
- Under Review 174
- Accepted 56
- Ongoing 5
- Coming Soon 11
- Implemented 481
- Not Planned 116
- Revisit 62
- Partner Dependent 4
- Inactive 674
-
Admin Settings
20 -
AMP Engine
27 -
API
11 -
API SDK
218 -
Category Address
13 -
Category Apps
113 -
Category Behavior Analysis
5 -
Category Calgary
21 -
Category Connectors
245 -
Category Data Investigation
77 -
Category Demographic Analysis
2 -
Category Developer
208 -
Category Documentation
80 -
Category In Database
214 -
Category Input Output
640 -
Category Interface
239 -
Category Join
103 -
Category Machine Learning
3 -
Category Macros
153 -
Category Parse
76 -
Category Predictive
77 -
Category Preparation
394 -
Category Prescriptive
1 -
Category Reporting
198 -
Category Spatial
81 -
Category Text Mining
23 -
Category Time Series
22 -
Category Transform
88 -
Configuration
1 -
Content
1 -
Data Connectors
961 -
Data Products
2 -
Desktop Experience
1,533 -
Documentation
64 -
Engine
126 -
Enhancement
325 -
Feature Request
213 -
General
307 -
General Suggestion
6 -
Insights Dataset
2 -
Installation
24 -
Licenses and Activation
15 -
Licensing
12 -
Localization
8 -
Location Intelligence
80 -
Machine Learning
13 -
My Alteryx
1 -
New Request
192 -
New Tool
32 -
Permissions
1 -
Runtime
28 -
Scheduler
23 -
SDK
10 -
Setup & Configuration
58 -
Tool Improvement
210 -
User Experience Design
165 -
User Settings
79 -
UX
222 -
XML
7
- « Previous
- Next »
- TUSHAR050392 on: Read an Open Excel file through Input/Dynamic Inpu...
- AudreyMcPfe on: Overhaul Management of Server Connections
-
 AlteryxIdeasTea
AlteryxIdeasTeam on: Expression Editors: Quality of life update - StarTrader on: Allow for the ability to turn off annotations on a...
-
 AkimasaKajitani
on:
Download tool : load a request from postman/bruno ...
AkimasaKajitani
on:
Download tool : load a request from postman/bruno ...
- rpeswar98 on: Alternative approach to Chained Apps : Ability to ...
-
caltang
on:
Identify Indent Level
- simonaubert_bd on: OpenAI connector : ability to choose a non-default...
- maryjdavies on: Lock & Unlock Workflows with Password
- noel_navarrete on: Append Fields: Option to Suppress Warning when bot...