Alteryx Designer Desktop Ideas
Share your Designer Desktop product ideas - we're listening!Submitting an Idea?
Be sure to review our Idea Submission Guidelines for more information!
Submission Guidelines- Community
- :
- Community
- :
- Participate
- :
- Ideas
- :
- Designer Desktop: Hot Ideas
Featured Ideas
Hello,
After used the new "Image Recognition Tool" a few days, I think you could improve it :
> by adding the dimensional constraints in front of each of the pre-trained models,
> by adding a true tool to divide the training data correctly (in order to have an equivalent number of images for each of the labels)
> at least, allow the tool to use black & white images (I wanted to test it on the MNIST, but the tool tells me that it necessarily needs RGB images) ?
Question : do you in the future allow the user to choose between CPU or GPU usage ?
In any case, thank you again for this new tool, it is certainly perfectible, but very simple to use, and I sincerely think that it will allow a greater number of people to understand the many use cases made possible thanks to image recognition.
Thank you again
Kévin VANCAPPEL (France ;-))
Thank you again.
Kévin VANCAPPEL
Hey YXDB Bosses,
Let's move forward with our YXDB. Maybe give AMP a real edge over e1. Here are some things that could may YXDB super-powered:
- Metadata
- Workflow information about what created that poorly named output file.
- When was the file originally created/updated.
- SORT order. If there is a sort order for the data, what is it?
- Other stuff
- INDEX. Currently you get spatial indexes (or you can opt out). If I want to search through a 100+MM record file, it is a sequential read of all of the data. With an index I could grab data without the expense of a calgary file creation. Don't go crazy on the indexing option, just allow users to set 1+ fields as index (takes more time to write).
- I'm sure that you've been asked before, but CREATE DIRECTORY if the output directory doesn't exist.
- Old School - Crazy Idea
- Generation Data Groups (GDG)
This will likely make @NicoleJ 's eyes roll 🙄 but back in the days, we could write our data to the SAME filename and the old data became 1 version older. You could read the (0) version of the file or read from 1, 2, 3 or more previous versions of the data using the same name (e.g. .\Customers|||3). The write of the output file would do all of the backing up of the data (easy to use) and when the initial defined limit expires, the data drops off.
- Generation Data Groups (GDG)
Just a little more craziness from me
cheers
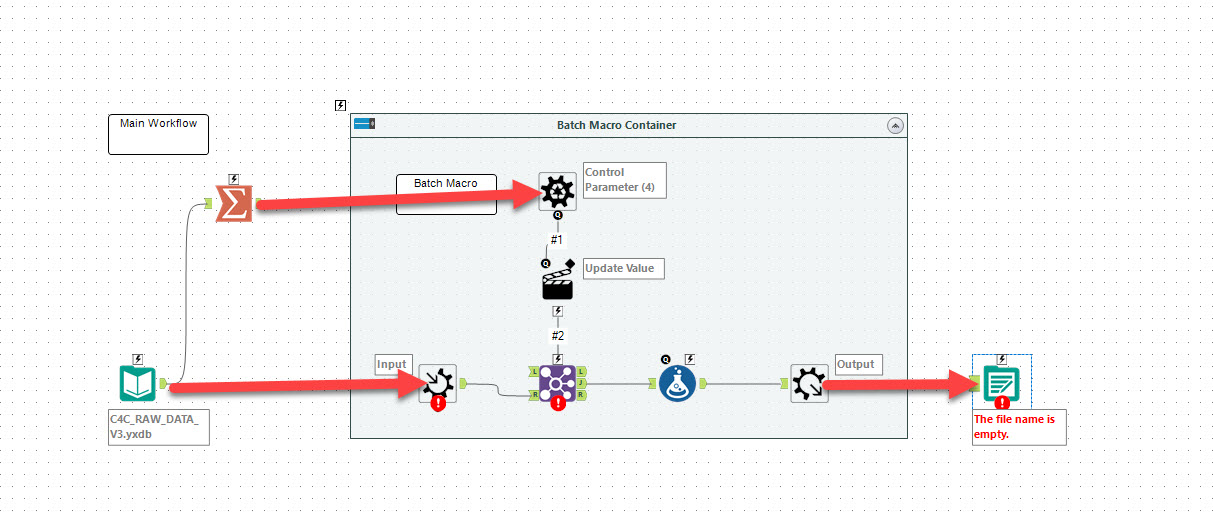
I like to suggest having a Batch Macro Container (besides the existing Container) which acts as a Batch Macro within a Workflow and is stored within the Workflow.
I understand that having a batch macro available as a separate tool can be very powerful and reduces redundant work. However, very often Batch Macros are set up for a specific workflow only and are of no use for other workflows. The Creation of a Batch Macro in a container will significantly reduce the time to deploy a batch macro and keeps the Macro folder clean of one-time Batch Macros.
Attached a picture of how this could look like
Thanks
Manuel
We are using silent Alteryx installation and would like to package license activation within the package. We do not want to expose Alteryx license key to the users to prevent them from sharing it with someone else. Requesting to add a flag/setting to allow admins to not display license key under Options>Manage Licenses.
Related request https://community.alteryx.com/t5/Alteryx-Designer-Discussions/Is-it-possible-to-hide-the-serial-key-...
Salesforce Input connector tool currently uses REST API.
Can we please enhance this tool to use BULK API?
Use Case:
We are sourcing about 2 million rows of opportunity data from Salesforce do to some insight analysis. This Alteryx workflow takes over an hour to run. The same dataset when pulled using a different ETL tool (Informatica) produces the dataset within 2 min! That makes a HUGE difference when you have a number of process to run in a limited amount of time. Enabling BULK API functionality on Salesforce input tool will help solve this problem.
A few suggestions that I think can improve the Sharepoint Files Output Tool:
- Maybe I'm missing it, but I cannot see how you can delete a file from the output list once you've added it:
- Have the write headers output checkbox ticked by default as I expect this is the more common expectation:
- Take the file extension by default based on the users selection in the Options tab as I shouldn't have to write .xlsx for the extension:




Hi there,
When connecting to data sources using DCM - could we please add the ability to make JDBC connections?
see:
https://community.alteryx.com/t5/Engine-Works/JDBC-Connections-in-Alteryx/ba-p/968782
As mentioned in these threads - JDBC is very common in large enterprises - and in many cases is better supported by the technology teams / developer community and so is much easier to make a connection. Added to this - there are many databases (e.g. DB2) where JDBC connections are just much easier
Please could you add JDBC connections to the DCM tooling?
Thank you
Sean
cc: @wesley-siu @_PavelP
Hello All,
I'm using the dynamic input tool for SQL requests in my Workflow (WF).
I'm using the "Replace a Specific String" to replace elements in the SQL statement dynamically depeding on results of prevoius tools, user input etc.
So the statement looks like
select * from Schema_Name_xx where invoice_number = 'invoice_number_xx'
Since Schema_Name_xx is no valid Schema in the Database, the statement (= Validation) won't work. Only if I replace Schema_Name_xx by e.g. Invoice_Data_Current it will work, same with the invoice number, invoice_number_xx is replaced by e.g. 4711.
Therefore, validation makes no sense and will never work, only if the WF is running, the correct Schema is inserted in the SQL statement by the "Replace a Specific String" function.
It would be great to disable it in the users settings or wherever in the Designer, changing a config file would also be great :-)
Pls. note: I'm thinking (since I'm not allowed anyway ;-)) about changing/disabeling anything in the Alteryx Server settings.
Reason:
1. Speed: Validating a WF with SQL statements that don't work takes time (every time I save it), sometimes I get even a timeout...
2. WF error entries: Each upload with a failed validation creates an entry in the WF result list which makes it harder to seperate them from the "real" WF errors...
Thanks & Best Regards,
Thomas
When writing an expression in a Formula tool, I love that you can just type an open bracket and suggestions pop up that allow you to auto-fill the rest of the variable name. What I find frustrating, however, is that once you type the open bracket, the highlighted field automatically moves to the one where your mouse is pointing, regardless of if you have moved your mouse or not. I think it makes more sense to always highlight the first field in the list and only take mouse position into account once it has actually moved.
It is hard to describe in just a picture as opposed to a video but essentially I had my mouse below where I was typing in the screenshot below then when I typed the open bracket, the 3rd field listed automatically got selected even though I never moved my mouse.

Cc: @Hollingsworth
I've used the Table tool with large data sets to make tables with conditional formatting etc. There's a couple of suggestions I'd like to see.
1. I noticed an issue where if you disconnect from the tool prior to the Table tool before it forgets your settings quite easily and you may need to redo them. This is quite frustrating if you have lots of columns
2. The controls for sorting and interacting with columns aren't very good, if they were more like the select tool controls that would be fantastic. Perhaps this could be resolved with a select tool beforehand but I still think it is worth putting on the table tool itself.
3. Render output. when making excel outputs with multiple sheets of varying sizes, its very difficult to control. The sheets all stretch to the largest size. I've found I've had to put in white space in Report Text tools on one side of a table tool in order to make up the space and prevent stretching. (I found that solution on the forums)
Thanks.
Frank
When building out Alteryx workflows there may be a need to read in different ranges within the same Excel spreadsheet. For example bringing in a table from Sheet1, but also isolating a table name in a particular cell (in my example cell C8).

When turning this into an analytic app, with a file browse is to add an action tool with the default value of "Update Input Data Tool".

However when specifying this option within the analytic app interface, you are only allowed to chose one option of the following:
i) Select a sheet
ii) Select a sheet and specify a range
iii) a named range or
iv) a list of sheet names.
The problem is in the example above I need a sheet and a range, but I want to avoid adding two file browse interface tools as it shouldn't be needed. If the user selects (i) then it loses the reference to cell C8, but I would imagine a lot of users as they get started with apps don't realise this is what will happen.
There is however a way to solve this currently and it requires overwriting the default behaviour and configuring the second action tool (the one that updates the file for C8), to update value with a formula, where you assume the user would select sheet name and then use this formula:
replace([#1],"$`","$C8:C8`")
However I would argue that this has a lot of technical debt, plus if the user needs to modify where the header is, for example to D8 they need to change the input file and the action tool so it works as a workflow and an analytic app.
Solution
Like how the configuration options for the input file, such as which row to input data from or whether first row contains data is maintained, modify the behaviour of the default option in the action tool to maintain references to ranges.
Hello,
As I mentioned in this previous idea : https://community.alteryx.com/t5/Alteryx-Designer-Ideas/Generic-In-database-connection-please-stop-i...
field mapping in generic in-db connection is based on Microsoft Sql Server. Given the specificity of MSQL Server field types, I would like to change that in order to at least be able to use another database. Without that, this feature has no sense at all.
Best regards,
Simon
Alteryx has the ability to connect to data sources using fat clients and ODBC but not JDBC. If the ability to use JDBC could be added to the product it could remove the need to install fat clients.
Hi there,
My idea comes when I've built an application, where user select filter from drop-down list. However it contains thousands of records, so it takes lot's of time to find desired record.
In Excel and MS Access when you use filter you can put many letter and filter shows rows that match the input. In Alteryx user can only put first letter, which is huge drawback to my users.
This is how it works in Excel:

Hope you like it!
Could we please have a Type field added to the "Select Fields to Cleanse" configuration window for the Data Cleansing Tool? This small feature would save a lot of time (saving the time needed to check the Metadata for every field every time I use the Data Cleansing Tool). Similar functionality to the way the Summarize Tool displays both Field and Type (just one additional field).
Today:

Future Version:

Pardon my sad photoshopping 🙂
Note: I realize the Data Cleansing is a macro and this functionality is not currently available with the "Check Box" interface tool.
Thank you!
It would be awesome if there was a cross tab in DB option because right now I have to stream out millions of records to build a cross tab.
Given the prevalence of XML - it seems that it's worth adding a native XML capability to Alterxy (similar to the discussion with @CharleyMcGee and @KaneG in the discussion forum). Currently XML is treated mostly like a big and oddly behaved text field, which really undermines the usefulness of XML in real applications.
What I'm thinking is:
- Add in a component, which acts like a join, but what it does is validates an XML file vs. an XSD file so that you can see if your XML file matches the schema definition. Tremendously useful if you've ever had to hand-craft XML.
- Add in a native data-type for XML (like you have a data-type for Centroids)
- On this XML data type - you can then do interesting things like walk the document object model, or iterate through all children (which fixes the issue of deeply nested XML being such a pain). This would bring XML parsing into the level of usefulness that programmers in Java & Visual Studio have enjoyed for years
- Finally - an ability to construct XML data files without having to text-hack this. i.e. something similar to the transpose tool, where for a given node, you can add children etc.
These four things would really really assist with getting Alteryx to be able to deal with modern data sets like JSON; XML and even web-page scrubbing.
As always - very happy to commit time to helping shape this - please feel free to reach out if that would be useful.
Thank you all
Sean
CC: @JoeM; @mceleavey; @MarqueeCrew; @NeilR; @Ned; @dawid_nawrot; @TaraM; @GeneR
Hello,
A few years ago, Alteryx was 4 released per year and now it's only 2 per year (in 2023, as of today, only one !!)
The reasons why I would the cadence to be back to quarter release :
-a quarter cadence means waiting less time to profit of the Alteryx new features so more value
-quarter cadence is now an industry standard on data software.
-for partners, the new situation means less customer upgrade opportunities, so less cash but also less contacts with customers.
Best regards,
Simon
Currently, when one uses the Google BigQuery Output tool, the only options are to create a table, or append data to an existing table. It would be more useful if there was a process to replace all data in the table rather than appending. Having the option to overwrite an existing table in Google BigQuery would be optimal.
Currently when debug mode is entered in analytic apps and macros, the direct inputs to the app/macro when the error occurred are hardcoded into a workflow in debug mode, so that errors can be more easily detected.
However, inputs into analytic apps also create global variables which can be used in the more code-heavy aspects of Alteryx such as the Formula Tool. These are not updated in the same way which can cause workflows to break in debug mode - it would be really helpful if global variables could be updated in the same way as the inputs into tools are.
It would be nice to be able to concatenate numeric values (integers, doubles, etc.) directly in the Summarize Tool.
I know this would involve converting it to a string on the backend, but I don't believe there would be any data loss when going from numeric to string. I know this can be done by using other tools like Select of Formula to convert to string before the summarize but I don't see any reason why this couldn't be accomplished in a single tool.

{kind=link}
Thanks,
Paul
- New Idea 290
- Accepting Votes 1,791
- Comments Requested 22
- Under Review 166
- Accepted 55
- Ongoing 8
- Coming Soon 7
- Implemented 539
- Not Planned 111
- Revisit 59
- Partner Dependent 4
- Inactive 674
-
Admin Settings
20 -
AMP Engine
27 -
API
11 -
API SDK
220 -
Category Address
13 -
Category Apps
113 -
Category Behavior Analysis
5 -
Category Calgary
21 -
Category Connectors
247 -
Category Data Investigation
79 -
Category Demographic Analysis
2 -
Category Developer
209 -
Category Documentation
80 -
Category In Database
215 -
Category Input Output
645 -
Category Interface
240 -
Category Join
103 -
Category Machine Learning
3 -
Category Macros
153 -
Category Parse
76 -
Category Predictive
79 -
Category Preparation
395 -
Category Prescriptive
1 -
Category Reporting
198 -
Category Spatial
81 -
Category Text Mining
23 -
Category Time Series
22 -
Category Transform
89 -
Configuration
1 -
Content
1 -
Data Connectors
968 -
Data Products
3 -
Desktop Experience
1,550 -
Documentation
64 -
Engine
127 -
Enhancement
342 -
Feature Request
213 -
General
307 -
General Suggestion
6 -
Insights Dataset
2 -
Installation
24 -
Licenses and Activation
15 -
Licensing
13 -
Localization
8 -
Location Intelligence
80 -
Machine Learning
13 -
My Alteryx
1 -
New Request
204 -
New Tool
32 -
Permissions
1 -
Runtime
28 -
Scheduler
24 -
SDK
10 -
Setup & Configuration
58 -
Tool Improvement
210 -
User Experience Design
165 -
User Settings
81 -
UX
223 -
XML
7
- « Previous
- Next »
- Shifty on: Copy Tool Configuration
- simonaubert_bd on: A formula to get DCM connection name and type (and...
-
 NicoleJ
on:
Disable mouse wheel interactions for unexpanded dr...
NicoleJ
on:
Disable mouse wheel interactions for unexpanded dr...
- haraldharders on: Improve Text Input tool
- simonaubert_bd on: Unique key detector tool
- TUSHAR050392 on: Read an Open Excel file through Input/Dynamic Inpu...
- jackchoy on: Enhancing Data Cleaning
- NeoInfiniTech on: Extended Concatenate Functionality for Cross Tab T...
- AudreyMcPfe on: Overhaul Management of Server Connections
-
AlteryxIdeasTea
m on: Expression Editors: Quality of life update
| User | Likes Count |
|---|---|
| 10 | |
| 7 | |
| 5 | |
| 5 | |
| 3 |