Alteryx Designer Desktop Ideas
Share your Designer Desktop product ideas - we're listening!Submitting an Idea?
Be sure to review our Idea Submission Guidelines for more information!
Submission Guidelines- Community
- :
- Community
- :
- Participate
- :
- Ideas
- :
- Designer Desktop: Hot Ideas
Featured Ideas
Hello,
After used the new "Image Recognition Tool" a few days, I think you could improve it :
> by adding the dimensional constraints in front of each of the pre-trained models,
> by adding a true tool to divide the training data correctly (in order to have an equivalent number of images for each of the labels)
> at least, allow the tool to use black & white images (I wanted to test it on the MNIST, but the tool tells me that it necessarily needs RGB images) ?
Question : do you in the future allow the user to choose between CPU or GPU usage ?
In any case, thank you again for this new tool, it is certainly perfectible, but very simple to use, and I sincerely think that it will allow a greater number of people to understand the many use cases made possible thanks to image recognition.
Thank you again
Kévin VANCAPPEL (France ;-))
Thank you again.
Kévin VANCAPPEL
Hello,
In Datascience, Levenshtein and Jaro Winkler distances are used to quanitify a similarity between two strings.
Here the wikipedia pages
https://en.wikipedia.org/wiki/Levenshtein_distance
https://en.wikipedia.org/wiki/Jaro%E2%80%93Winkler_distance
Note 1 : the Levenshtein and Jaro Distances are already used in Fuzzy Matching tool, so that shouldn't be a huge work to include it in formula
Note 2 : there is a useful macro on the galley https://gallery.alteryx.com/#!app/LevenshteinDistance/5c54701f826fd30988f02779
Note 3 : some product already have it implemented such as Apache Hive or Qlik Sense
Best regards,
Simon
Hi there,
My idea comes when I've built an application, where user select filter from drop-down list. However it contains thousands of records, so it takes lot's of time to find desired record.
In Excel and MS Access when you use filter you can put many letter and filter shows rows that match the input. In Alteryx user can only put first letter, which is huge drawback to my users.
This is how it works in Excel:

Hope you like it!
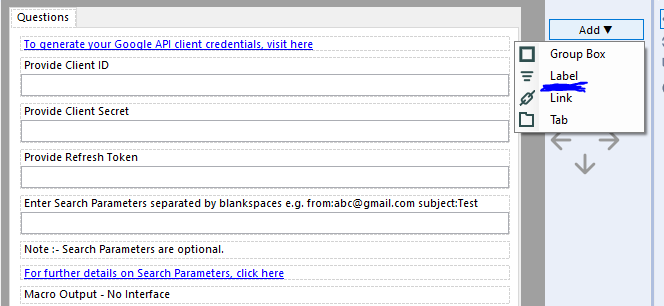
Hi all,
Is it possible to add an option to 'Add an Image' in the settings option of Interface Designer while building Apps or macros?
Currently, we can add Group box, Link, Tab, and Label. It would be really helpful if we can add static images as well!!
This would enable a developer to add an explanatory image just as a link or label is used to communicate to end user.
I am attaching a screenshot for the reference.

Thanks in advance!!
Regards,
Shreyansh Rathod
Can you put a check box on the container title bar to make it easier to enable/disable containers in the process window? And can you make the minimize/maximize option for a conatiner a separate option from enable/disable?
I noticed through the ODBC driver log that Alteryx doesn't care about the kind of base I precise. It tests every single kind of base to find the good one and THEN applies the queries to get the metadata info.
Here an example. I have chosen an Hive in db connection. If I read the simba logs, i can find those lines :
Mar 01 11:37:21.318 INFO 5264 HardyDataEngine::Prepare: Incoming SQL: select USER(), APPLICATION_ID() from system.iota
Mar 01 11:37:22.863 INFO 5264 HardyDataEngine::Prepare: Incoming SQL: select USER as USER_NAME from SYSIBM.SYSDUMMY1
Mar 01 11:37:23.454 INFO 5264 HardyDataEngine::Prepare: Incoming SQL: select * from rdb$relations
Mar 01 11:37:23.546 INFO 5264 HardyDataEngine::Prepare: Incoming SQL: select first 1 dbinfo('version', 'full') from systables
Mar 01 11:37:23.707 INFO 5264 HardyDataEngine::Prepare: Incoming SQL: select #01/01/01# as AccessDate
Mar 01 11:37:23.868 INFO 5264 HardyDataEngine::Prepare: Incoming SQL: exec sp_server_info 1
Mar 01 11:37:24.093 INFO 5264 HardyDataEngine::Prepare: Incoming SQL: select top (0) * from INFORMATION_SCHEMA.INDEXES
Mar 01 11:37:24.219 INFO 5264 HardyDataEngine::Prepare: Incoming SQL: SELECT SERVERPROPERTY('edition')
Mar 01 11:37:24.423 INFO 5264 HardyDataEngine::Prepare: Incoming SQL: select DATABASE() as `database`, VERSION() as `version`
Mar 01 11:37:24.635 INFO 5264 HardyDataEngine::Prepare: Incoming SQL: select * from sys.V_$VERSION at where RowNum<2
Mar 01 11:37:25.230 INFO 5264 HardyDataEngine::Prepare: Incoming SQL: select cast(version() as char(10)), (select 1 from pg_catalog.pg_class) as t
Mar 01 11:37:25.415 INFO 5264 HardyDataEngine::Prepare: Incoming SQL: select NAME from sqlite_master
Mar 01 11:37:25.756 INFO 5264 HardyDataEngine::Prepare: Incoming SQL: select xp_msver('CompanyName')
Mar 01 11:37:26.156 INFO 5264 HardyDataEngine::Prepare: Incoming SQL: select @@version
Mar 01 11:37:26.376 INFO 5264 HardyDataEngine::Prepare: Incoming SQL: select * from dbc.dbcinfo
Mar 01 11:37:26.522 INFO 5264 HardyDataEngine::Prepare: Incoming SQL: SELECT @@VERSION;
I can understand that when Alteryx doesn't know the kind of base he tries everything.. (eg : in memory visual query builder) but here, I have selected the Hive database and I have to loose more than 5 seconds for nothing.
I rarely use the Group By tab on batch macros, but it's unfortunately always the first tab that pops up. When I have a questions tab on a batch macro, it would be great if it appeared first (ie I should see the questions tab when I click on my batch macro.) Thanks!

Currently, when one uses the Google BigQuery Output tool, the only options are to create a table, or append data to an existing table. It would be more useful if there was a process to replace all data in the table rather than appending. Having the option to overwrite an existing table in Google BigQuery would be optimal.
On the UNION tool, allow for deselecting columns that aren't relevant. Leave the union exactly as it is, and you could go into the manual configuration. Align the columns just as you would in the manual configuration. The addition would be that you have the behavior like you see in a join tool where you could deselect C1, C2, C3.... Cx.
Too many times I have a union and there are fields I simply don't even want to bring in, but then have to add a select tool right after in order to remove them.
Similar to the thoughts in this idea, it would be great if the parenthesis matching functionality could be added to the formula tool as well.
Can we have a User Setting that allows the users to select if Alteryx should prevent the computer to go into Sleep or Hibernate mode when running a workflow?
I like the new cache option in 2018.3, but I would like it to function a little bit different. Let's say you cache at a certain point and then continue to build after that. If I reach another checkpoint and want to cache, it currently re-runs the entire workflow (ie it ignores my cache upstream and just goes back to the beginning of the workflow); instead, I would rather have it utilize the upstream cache. Personally, caching is usually an iterative effort during development where I keep caching along the way. The current functionality of the cache is not conducive to this. Thanks!
Hello!
I remember a while ago running into a peculiar error:
'The R.exe exit code (4294967295) indicted an error'. This was peculiar, as the data output was still seemingly correct, however, the error made me double-check the community for answers.
There are some very technical sources here:
https://community.alteryx.com/t5/Alteryx-Designer-Discussions/R-tool-Fake-Errors/td-p/25163
https://community.alteryx.com/t5/Alteryx-Designer-Discussions/Boosted-Model-Error/td-p/5509
but in short, this seems to be caused by a return code from C++ libraries, being understood by R as an error. Its a very inconsistent error, typically caused by low memory. This creates what most call a 'fake error' - the code runs perfectly fine, but seems to produce an error that doesn't actually indicate anything wrong.
Within those threads, its also stated that calling the garbage collection function (gc()) does tend to solve the problem on R exit, however this requires a user to understand basic R, and have access to the macro to be able to change the code - thus making predictive analytics more intimidating than it already is for new Alteryx users.
The first occurrence of this error seems to be way back in 2015, however the error is still being reported by users (see posts from 2020 and 2021):
https://community.alteryx.com/t5/Alteryx-Designer-Discussions/Password-protected-Excel-files-R-solut...
https://community.alteryx.com/t5/Alteryx-Designer-Knowledge-Base/Error-The-R-exe-exit-code-n-indicat...
An important issue of these 'fake errors', is not only that they cause confusion, but also that they will cause analytic apps and server workflows to not work as expected, and stop running depending on the configuration.
My suggestion would be to revisit this issue, as by my understanding it occurs inconsistently, and calling garbage collection does not always seem to fix it. Even if the Error message is still created, it may be worth Alteryx suppressing these errors, in the case they are not real errors.
Steps to reproduce:
(as mentioned, its very inconsistent)
1. Open the Boosted Model example workflow
2. *10 the number of maximum trees in the model, in the boosted model configuration (Model customization)
3. Run the workflow, inspect the results (which are seemingly correct), and the error message in the results window.

Hope this helps!
TheOC
When I create a new table in a in-Db workflow, I want to specify some contraints, especially the Primary Key/Foreign Key
For PK/FK, the UX could be either the selection of some fields of the flow or a free field (to let the user choose a constant).
From wikipedia :
In the relational model of databases, a primary key is a specific choice of a minimal set of attributes (columns) that uniquely specify a tuple (row) in a relation (table).[a] Informally, a primary key is "which attributes identify a record", and in simple cases are simply a single attribute: a unique id.
So, basically, PK/FK helps in two ways :
1/ Check for duplicate, check if the value inserted is legit
2/ Improve query plan, especially for join
Desperately looking for a way to connect to SQL Server Analysis Services through Alteryx as more and more of our large datasets from our older systems are moving to here in the next few months. We can connect using PowerBi with limitations (connecting 'Live' does not allow merge and connecting with Import, you need to use MDX or DAX syntax). We run into import and export limitations, too. We are not allowed access to the underlying tables, but the tables with the measures, dimensions and fields. PowerBi is a big step up from pivot tables, but Alteryx would be so much better. Ideas for connecting this up are are welcome!
The expression editor in the RegEx tool is only a single line, which makes it really hard to edit long regular expressions. See attached photo comparing the expression editor in the RegEx tool compared to the formula tool for the same expression. Please make the RegEx editor box either wrap to multiple lines, have a pop-out expression editor, or something so we can see long expressions.

Given Crew Macro Pack increases Alteryx's capability so much, and is used so pervasively, is there a reason to not include Crew Macro Pack in Alteryx Designer or Alteryx Server by default?
Can anyone give a reason why Alteryx wouldn't bundle Crew Macro Pack?
If not, can we get Crew Macro Pack bundled into Alteryx and have official support for it?
It would be very helpful to have an output of the workflow into a step by step document. so someone who does not have access to Alteryx can undestand the steps taken to create the flow hence the result or output.
Hello Alteryx Community,
If like me, you've been developing in Alteryx for a few years, or if you find yourself as a new developer creating solutions for your organization - chances are you'll need to create some form of support procedure or automation configuration file at some point. In my experience, the foundation of these files is typically explaining to users what each tool in the workflow is doing, and what transformations to the data are being made. These are typically laborious to create and often created in a non-standardized way.
The proposal: Create Alteryx Designer native functionality to parse a workflow's XML and translate the tool configurations into a step by step word document of a given workflow.
Although the expectation is that after something like this is complete a user may need to add contextual details around the logic created, this proposal should eliminate a lot of the upfront work in creating these documents.
Understand some workflow may be very complex but for a simple workflow like the below, a proposed output could be like the below, and if annotations are provided at the tool level, the output could pick those up as well:

Workflow Name: Sample
1) Text Input tool (1) - contains 1 row with data across columns test and test1. This tool connects to Select Tool (2).
2) Select Tool (2) - deselects "Unknown" field and changes the data type of field test1 to a Double. This tool connects to Output (3).
3) Output (3) - creates .xlsx output called test.xlsx
Given the prevalence of XML - it seems that it's worth adding a native XML capability to Alterxy (similar to the discussion with @CharleyMcGee and @KaneG in the discussion forum). Currently XML is treated mostly like a big and oddly behaved text field, which really undermines the usefulness of XML in real applications.
What I'm thinking is:
- Add in a component, which acts like a join, but what it does is validates an XML file vs. an XSD file so that you can see if your XML file matches the schema definition. Tremendously useful if you've ever had to hand-craft XML.
- Add in a native data-type for XML (like you have a data-type for Centroids)
- On this XML data type - you can then do interesting things like walk the document object model, or iterate through all children (which fixes the issue of deeply nested XML being such a pain). This would bring XML parsing into the level of usefulness that programmers in Java & Visual Studio have enjoyed for years
- Finally - an ability to construct XML data files without having to text-hack this. i.e. something similar to the transpose tool, where for a given node, you can add children etc.
These four things would really really assist with getting Alteryx to be able to deal with modern data sets like JSON; XML and even web-page scrubbing.
As always - very happy to commit time to helping shape this - please feel free to reach out if that would be useful.
Thank you all
Sean
CC: @JoeM; @mceleavey; @MarqueeCrew; @NeilR; @Ned; @dawid_nawrot; @TaraM; @GeneR
Hi all,
Something really interesting I found - and never knew about, is there are actually in-DB predictive tools. You can find these by having a connect-indb tool on the canvas and dragging on one of the many predictive tools.
For instance:
boosted model dragged on empty campus:

Boosted model tool deleted, connect in-db tool added to the canvas:

Boosted Model dragged onto the canvas the exact same:

This is awesome! I have no idea how these tools work, I have only just found out they are a thing. Are we able to unhide these? I actually thought I had fallen into an Alteryx Designer bug, however it appears to be much more of a feature.
Sadly these tools are currently not searchable for, and do not show up under the in-DB section. However, I believe these need to be more accessible and well documented for users to find.

{kind=link}
Cheers,
TheOC
- New Idea 225
- Accepting Votes 1,823
- Comments Requested 25
- Under Review 162
- Accepted 60
- Ongoing 5
- Coming Soon 6
- Implemented 480
- Not Planned 120
- Revisit 65
- Partner Dependent 4
- Inactive 674
-
Admin Settings
19 -
AMP Engine
27 -
API
11 -
API SDK
217 -
Category Address
13 -
Category Apps
112 -
Category Behavior Analysis
5 -
Category Calgary
21 -
Category Connectors
240 -
Category Data Investigation
75 -
Category Demographic Analysis
2 -
Category Developer
206 -
Category Documentation
78 -
Category In Database
212 -
Category Input Output
634 -
Category Interface
236 -
Category Join
101 -
Category Machine Learning
3 -
Category Macros
153 -
Category Parse
76 -
Category Predictive
77 -
Category Preparation
385 -
Category Prescriptive
1 -
Category Reporting
198 -
Category Spatial
81 -
Category Text Mining
23 -
Category Time Series
22 -
Category Transform
87 -
Configuration
1 -
Data Connectors
951 -
Data Products
1 -
Desktop Experience
1,502 -
Documentation
64 -
Engine
124 -
Enhancement
289 -
Feature Request
212 -
General
307 -
General Suggestion
4 -
Insights Dataset
2 -
Installation
24 -
Licenses and Activation
15 -
Licensing
11 -
Localization
8 -
Location Intelligence
80 -
Machine Learning
13 -
New Request
180 -
New Tool
32 -
Permissions
1 -
Runtime
28 -
Scheduler
22 -
SDK
10 -
Setup & Configuration
58 -
Tool Improvement
210 -
User Experience Design
165 -
User Settings
73 -
UX
220 -
XML
7
- « Previous
- Next »
- DataNath on: Update Render to allow Excel Sheet Naming
- aatalai on: Applying a PCA model to new data
- charlieepes on: Multi-Fill Tool
- vijayguru on: YXDB SQL Tool to fetch the required data
- apathetichell on: Github support
- Fabrice_P on: Hide/Unhide password button
- NeoInfiniTech on: Adjustable Delay for Control Containers
-
 Watermark
on:
Dynamic Input: Check box to include a field with D...
Watermark
on:
Dynamic Input: Check box to include a field with D...
- aatalai on: cross tab special characters
- KamenRider on: Expand Character Limit of Email Fields to >254
| User | Likes Count |
|---|---|
| 44 | |
| 13 | |
| 12 | |
| 7 | |
| 6 |