Alteryx Designer Desktop Ideas
Share your Designer Desktop product ideas - we're listening!Submitting an Idea?
Be sure to review our Idea Submission Guidelines for more information!
Submission Guidelines- Community
- :
- Community
- :
- Participate
- :
- Ideas
- :
- Designer Desktop: Hot Ideas
Featured Ideas
Hello,
After used the new "Image Recognition Tool" a few days, I think you could improve it :
> by adding the dimensional constraints in front of each of the pre-trained models,
> by adding a true tool to divide the training data correctly (in order to have an equivalent number of images for each of the labels)
> at least, allow the tool to use black & white images (I wanted to test it on the MNIST, but the tool tells me that it necessarily needs RGB images) ?
Question : do you in the future allow the user to choose between CPU or GPU usage ?
In any case, thank you again for this new tool, it is certainly perfectible, but very simple to use, and I sincerely think that it will allow a greater number of people to understand the many use cases made possible thanks to image recognition.
Thank you again
Kévin VANCAPPEL (France ;-))
Thank you again.
Kévin VANCAPPEL
For people recently met with RegEx, you are lucky if the expression is short and understandable or "human readable".
But there are extreme cases too where it's really a pain to solve the puzzle.
if you'd like to catch e-mail addresses from masses of unstructured data this will work;
/^([a-z0-9_\.-]+)@([\da-z\.-]+)\.([a-z\.]{2,6})$/
and here is the elaboration;
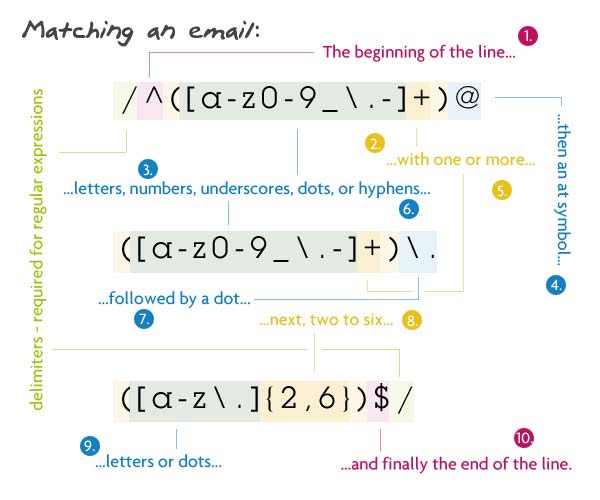
when colorful it's fun but barely readable still... Here is a Regexper version

This visualizer I came across at https://regexper.com/ is awesome.
- Can you please integrate this into Designer for ease of reading and understanding existing RegEx...
- Can it be possible to develop an interactive tool to prepare;
- The graphical representation of our regular expression first
- And then writing it in the same old fashion...
Please support the idea if you like...
-
Feature Request
-
User Experience Design
I've seen several posts and questions concerning NULL dates. Is 09/31/2010 a valid date? I know that 02/29/206 isn't valid and that 02/00/2006 isn't either, but I really don't like finding out about these in conversion warning messages.
I might suggest a function that returns True or False on the date check and let the user configure appropriate rules to rethink the attempted date prior to committing the field to the date data type.
Cheers,
Mark
-
Feature Request
-
Tool Improvement
So lets say I have five incoming connection. SQL, Redshift, Excel...whatever. I know I can right click, or control-right click on each incoming connection and select cache and run workflow. I'd imagine there would be a run and cache all incoming connections but there isn't. I realize I can arrange all incoming connections so they arrange easily so I can box them all, but on complex workflows, this might get complicated.
-
Feature Request
-
General Suggestion
the SQL Editing screen has recently been changed (thank you @JPoz and team!) - and now has syntax indenting and keyword coloring.
Could I ask that you make a minor change in the indenting, where the on part is indented underneath the Join?
Select
Field1,
Field2,
field3
from
Table1
inner join table2
On Table1.key = table2.key
and table1.keyb = table2.keyb
inner join table3
on table3.key = table1.key
and table3.date = table1.date
-
Feature Request
-
General
-
Tool Improvement
Exactly as the subject says: It would be incredibly useful to be able to change the colour, and possibly the line thickness of the connectors between tools.
We have workflows with huge amounts of stuff going on, as I'm sure many people do.
Being able to colour code the connections between tools would help us to trace things from place to place when stepping through the workflow.
-
Feature Request
-
Setup & Configuration
-
User Experience Design
I suggest that it would be beneficial to add in a column filter that can automatically remove columns based on a condition, such as removing columns where all values are NULL or if they contain something in the values.
Should have a True and False output, like the normal Filter tool, so you can check what is being removed.
e.g. Would help with when you get poorly formatted excel sheets that add in hundreds of redundant columns, or if your workflow has generated NULL columns that should be removed, without having to Transpose, Filter, Cross tab etc to clear them out.
Thanks,
Doug
-
Feature Request
-
New Tool
Please could we add Qubole to supported data sources,
It is possible to connect to Qubole via ODBC Connection
However, this error message is often returned on a query: InboundNamedPipe GetOverlappedResult: The pipe has been ended
I've been advised by Alteryx Support that this is likely due to the ODBC driver.
If it's possible to add Qubole to supported data sources it would save a lot of time committed to troubleshooting this error.
All the best
-
Category Connectors
-
Category Input Output
-
Data Connectors
-
Feature Request
The Python tool has been a tremendous boon in being able to add capability that is not yet available in the Alteryx platform.
It would make the Python Tool much more usable and useful if you can define the inputs explicitly rather than just relying on the good behaviour of both the user; and also the python code that reads the inbound data (Alteryx.Read('#1'))
This is not something that the Jupyter notebook code-interface may handle directly (because the Jupyter notebook has no priveledged knowledge of the workflow outside it); so this may be best handled by the container itself.
The key here is that if my python app requires 2 inputs - it should be possible to define these explicitly so that we can test; and also so that we can prevent errors and make this more bullet-proof.
The same would apply on the outbound nodes for the Python tool.
-
API SDK
-
Category Developer
-
Feature Request
-
General
For example I have an ERROR MESSAGE tool that is rather verbose. I chose to modify the annotation as: ZIP Code Check. I presumed that the result would simply be "ZIP Code Check", but Alteryx added that to the beginning of the annotation rather than replacing the whole annotation. I reported this as a bug, but was told that this was designed to operate in this manner. It was suggested that I bring this out as a "New Idea" to the community for review. If you agree that the tools should operate in a similar fashion for annotation (or other actions) across the pallet, please STAR this. Otherwise, I'm happy to hear your feedback.
Thanks,
Mark


-
Category Apps
-
Desktop Experience
-
Feature Request
Hello,
In Alteryx Designer application, in User Settings, please add an option for us to check/uncheck whether we would like to show/hide the Splash Screen upon app launch.
Thanks!
-
Feature Request
My idea is to have the AlteryxEngineCMD.exe to run a workflow as part of the standard Alteryx license.
Use case - be able to run Alteryx from the command line without the need to buy the entire Scheduler package (at $6,500/seat).
I understand why certain features are add on, but the ability to run AlteryxEngineCMD.exe (I feel) should be part of the standard license which is already $5K+. For those who only need to be able to run a command line execution of a workflow $6.5K is a lot of money!
-
API
-
Feature Request
The reporting tools do not currently support HTML structured or unstructured lists https://www.w3schools.com/tags/tag_ul.asp
All vertical combination creates tables which group the lines together. Even if you manually create this - you get an error saying that ul (or ol or il) are not supported in composer

This creates a challenge in 2 ways:
a) When creating lists in reporting outputs - you lose the functionality of structured lists (numbering with letters; numbers etc)
b) additionally - selecting the text in tables behaves differently than selecting data that is created in lists.
Please could you add the ability to create lists in addition to tables in the reporting tools by supporting the ol; ul; and il tags?
NOTE: this could initially be done just by supporting the tags; and then later this could be a summarize option on the summarize tool; and a bullet option in the text tool.



-
Category Reporting
-
Desktop Experience
-
Feature Request
Some of us work in teams to build complex workflows, resulting in various versions that have to be stitched together. It would be amazing to have the workflow on a shared drive and have a mode where multiple users can build, review, and modify simultaneously. (This was one of the biggest sells for our company migration from Microsoft Office to Google suite).
This would promote collaboration, learning, and more efficient and quality driven workflows.
-
Feature Request
-
General
Before Designer 2019.4 there was a "bug" in the workflow statistics collection that under the "SampleModule" data from the UsageGallery collection the name of the workflow run from within Designer was available. We used that information to determine the common workflows run in our community as well as generating a measure of community growth. The "bug" was removed in 2019.4 and now we can only determine the number of runs, but not the number of distinct workflows that were run. This idea to do return the workflow name run to the information stored in the Mongo database.

-
Feature Request
For deeply structured XML - it would be very helpful to be able to search XML (as you would using the DOM). Even better would be to implement XML Query capability (a visual tool) within Alteryx so that XML data can be directly queried: https://en.wikipedia.org/wiki/XQuery
-
Feature Request
-
General
I enjoy using Alteryx. It saves me a lot of time compared to manually writing scripts. But one of my frustrations is the lack of 'intelligence' in the IDE. Please make it so that if I change a name of a column in a select tool or a join, every occurence of that variable/column in selects, summarises, formulae and probably all tools downstream of the select tool renames as well. In other IDEs I believe this is called refactoring. It doesn't seem like an big feature to make, it would save enormous amounts of time and would make me very happy.
While we're on the 'intelligence' of the IDE, there is a small, easily fixable bug. When I have a variable with spaces in the middle, for example, 'This is my column name', and start writing in the code field "[Thi" then the drop downbox suggests "[This is my column name]". All good so far. But if I get a little further in the variable name, and write instead "[This i", then the dropdown box suggests "[This is my column name]", and I click this, the result is this: "[This [This is my column name]". Alternatively, I could write "[This is my col" and the result would be "[This is my [This is my column name]". Clearly this could be avoided by my using column names with underscores or hyphens; but I wanted to highlight to you the poor functionality here.
Kind regards,
Ben Hopkins
-
Feature Request
As Alteryx becomes more focussed on the Enterprise - it is important that we build capabilities that support the needs of large-scale BI.
One of these critical needs is dealing with heterogeneous data from different systems that use different IDs for every critical entity / concept (e.g. client; product)
Here's the example:
Problem:
- In any large enterprise - there are several thousand different line-of business systems
- Each of these was probably built at a different time, and uses a different key for specific concepts - like Client & Product
- Most large enterprises that I've worked at do not have a pre-built way of transforming these codes so...
- This means that any downstream analytics finds it almost impossible to give single-view-of-customer or single-view-of-product.
Solution option A:
Reengineer all upstream systems. Not feasible
Solution option B:
Expect some reference-data team to fix this by building translations. More feasible but not fast
Remaining Solution Option:
Just as Kimball talked about - the only real way is to define a set of enterprise dimensions, which are the defined master-list of critical concepts that you need to slice-and-dice by (client; product; currency; shipping method; etc) in a way which is source-system agnostic
Then you need a method in the middle to transform incoming data to use these codes. This process is called "Conforming"
What would this look like in Alteryx?
Setup
- We would use the connect product to define a new dimension - say "Product".
- Give this a unique ID which is source-system independant; and then add on the attributes that are important for analytics (product type; category; manufacturer; etc)
- Then decide how to handle change (slowly changing dimension or SCD type 0,1,2, etc). Alteryx should take full responsibility for managing this SCD history; as do many of the competitors
- We then create a list of possible synonym types (within Connect). For example - a product may have a synonym ID from your supplier; from your ERP system; from your point of sale system. that's 3 different IDs for any product.
- We then load up the master data - this is painful but necessary
In Use:
- I read in data into alteryx via any input tool
- I bring in a "Conforming" tool off the toolbox (new tool which is needed)
- It asks me which column or columns I wish to conform
- For each - it asks me which synonym type to use
- It then adds a translated column for me to use which ties back to the enterprise dimension - and spits out the errors where the synonym is necessary.
Impact:
In BI in smaller contexts, or quick rapid-fire BI - you don't have to worry about this. But as soon as you go past a few hundred line-of-business systems and are trying to do enterprise reporting, you really have to take this serious. This is a HUGE part of every BI persons's role in a large enterprise - and it is painful; slow and not very rewarding. If we could create this idea of a simple-to-use and high-velocity conforming process - this would absolutely tear the doors off enterprise BI - and no-one else is doing this yet!
+ @AshleyK @BenG @NickJ @ARich @patrick_digan @JoshKushner @samN @Ari_Fuller @Arianna_Fuller
-
Feature Request
For the purposes of troubleshooting/optimization, it might come in handy to have a timestamp column in the Results Pane. Especially with processes time-consuming enough that I let them run in the background, I would like to know which steps are particularly time consuming, and seeing when the messages were generated would at least be a start.
-
Feature Request
Hi Alteryx Designer Dev Team,
There are times where you want to create a variation of a particular pipeline and the data transformations in the beginning of the pipeline are similar but need slightly different configurations. To save time, can we have a right-click context option for each tool to be able to copy/paste or duplicate tool with existing configuration. This saves time by only having to change a few options in the duplicated tool. This is common for tools like, input, output, joins, groupings and reporting tools. An example where this functionality is handy in reporting: you may have a particular way that you always do your charts and instead of configuring the chart options from scratch each time, you copy paste the chart tool with current configuration and then you only have to make minor changes such as the data connections.
Thank you
-
Feature Request
-
Tool Improvement
-
User Experience Design
Hello - the added feature to show the designer tool detail of the four highly used tools (Join, Formula, Filter, and Summarize tool) is an incredible addition to Connect functionality. Can this functionality expand to the In-DB version of the same tools? We leverage In-DB when possible to utilize the processing power of the database. Adding this as well to Connect would be a huge benefit to see the complete picture of a workflow.
-
Feature Request
-
General Suggestion
- New Idea 275
- Accepting Votes 1,815
- Comments Requested 23
- Under Review 173
- Accepted 58
- Ongoing 6
- Coming Soon 19
- Implemented 483
- Not Planned 115
- Revisit 61
- Partner Dependent 4
- Inactive 672
-
Admin Settings
20 -
AMP Engine
27 -
API
11 -
API SDK
218 -
Category Address
13 -
Category Apps
113 -
Category Behavior Analysis
5 -
Category Calgary
21 -
Category Connectors
247 -
Category Data Investigation
77 -
Category Demographic Analysis
2 -
Category Developer
208 -
Category Documentation
80 -
Category In Database
214 -
Category Input Output
641 -
Category Interface
240 -
Category Join
103 -
Category Machine Learning
3 -
Category Macros
153 -
Category Parse
76 -
Category Predictive
77 -
Category Preparation
394 -
Category Prescriptive
1 -
Category Reporting
198 -
Category Spatial
81 -
Category Text Mining
23 -
Category Time Series
22 -
Category Transform
89 -
Configuration
1 -
Content
1 -
Data Connectors
964 -
Data Products
2 -
Desktop Experience
1,538 -
Documentation
64 -
Engine
126 -
Enhancement
331 -
Feature Request
213 -
General
307 -
General Suggestion
6 -
Insights Dataset
2 -
Installation
24 -
Licenses and Activation
15 -
Licensing
12 -
Localization
8 -
Location Intelligence
80 -
Machine Learning
13 -
My Alteryx
1 -
New Request
194 -
New Tool
32 -
Permissions
1 -
Runtime
28 -
Scheduler
23 -
SDK
10 -
Setup & Configuration
58 -
Tool Improvement
210 -
User Experience Design
165 -
User Settings
80 -
UX
223 -
XML
7
- « Previous
- Next »
-
 NicoleJ
on:
Disable mouse wheel interactions for unexpanded dr...
NicoleJ
on:
Disable mouse wheel interactions for unexpanded dr...
- TUSHAR050392 on: Read an Open Excel file through Input/Dynamic Inpu...
- jackchoy on: Enhancing Data Cleaning
- NeoInfiniTech on: Extended Concatenate Functionality for Cross Tab T...
- AudreyMcPfe on: Overhaul Management of Server Connections
-
AlteryxIdeasTea
m on: Expression Editors: Quality of life update - StarTrader on: Allow for the ability to turn off annotations on a...
- simonaubert_bd on: Download tool : load a request from postman/bruno ...
- rpeswar98 on: Alternative approach to Chained Apps : Ability to ...
-
 caltang
on:
Identify Indent Level
caltang
on:
Identify Indent Level
| User | Likes Count |
|---|---|
| 16 | |
| 9 | |
| 7 | |
| 5 | |
| 4 |