Alteryx Designer Desktop Ideas
Share your Designer Desktop product ideas - we're listening!Submitting an Idea?
Be sure to review our Idea Submission Guidelines for more information!
Submission Guidelines- Community
- :
- Community
- :
- Participate
- :
- Ideas
- :
- Designer Desktop: New Ideas
Featured Ideas
Hello,
After used the new "Image Recognition Tool" a few days, I think you could improve it :
> by adding the dimensional constraints in front of each of the pre-trained models,
> by adding a true tool to divide the training data correctly (in order to have an equivalent number of images for each of the labels)
> at least, allow the tool to use black & white images (I wanted to test it on the MNIST, but the tool tells me that it necessarily needs RGB images) ?
Question : do you in the future allow the user to choose between CPU or GPU usage ?
In any case, thank you again for this new tool, it is certainly perfectible, but very simple to use, and I sincerely think that it will allow a greater number of people to understand the many use cases made possible thanks to image recognition.
Thank you again
Kévin VANCAPPEL (France ;-))
Thank you again.
Kévin VANCAPPEL
Hello all,
As of today, you must set which database (e.g. : Snowflake, Vertica...) you connect to in your in db connection alias. This is fine but I think we should be able to also define the version, the release of the database. There are a lot of new features in database that Alteryx could use, improving User Experience, performance and security. (e.g. : in Hive 3.0, there is a catalog that could be used in Visual Query Builder instead of querying slowly each schema)
I think of a menu with the following choices :
-default (legacy) and precision of the Alteryx default version for the db
-autodetect (with a query launched every time you run the workflow when it's possible). if upper than last supported version, warning message and run with the last supported version settings.
-manual setting a release (to avoid to launch the version query every time). The choices would be every supported alteryx version.
Best regards,
Simon
-
Category In Database
-
Data Connectors
-
Desktop Experience
-
User Settings
Hello all,
Big picture : on Hadoop, a table can be
-internal (it's managed by Hive or Impala, and act like any other database)
-external (it's managed by hadoop, can be shared among the different hadoop db such as hive and impala and you can't delete it by default when dropping the table
for info, about suppression on external table :
https://docs.cloudera.com/HDPDocuments/HDP3/HDP-3.1.4/using-hiveql/content/hive_drop_external_table_...
Alteryx only creates internal tables while it would be nice to have the ability to create external tables that we can query with several tools (Hive, Impala, etc).
It must be implemented
-by default for connection
-by tool if we want to override the default
Best regards,
Simon
-
Category In Database
-
Data Connectors
Hello,
As of today, we can't choose exactly the file format for Hadoop when writing/creating a table. There are several file format, each wih its specificity.
Therefore I suggest the ability to choose this file format :
-by default on connection (in-db connection or in-memory alias)
-ability to choose the format for the writing tool itself.
Best regards,
Simon
-
Category In Database
-
Data Connectors
Hello all,
We all love pretty much the in-memory multi-row formula tool. Easy to use, etc. However, the indb counterpart does not exist.
I see that as a wizard that would generate windowing functions like LEAD or LAG
https://mode.com/sql-tutorial/sql-window-functions/
Best regards,
Simon
-
Category In Database
-
Data Connectors
Sometimes I need to connect to the data in my Database after doing some filtering and modeling with CTEs. To ensure that the connection runs quicker than by using the regular input tool, I would like to use the in DB tool. But is doesn't working because the in DB input tool doesn't support CTEs. CTEs are helpful for everyday life and it would be terribly tedious to replicate all my SQL logic into Alteryx additionally to what I'm already doing inside the tool.
I found a lot of people having the same issue, it would be great if we can have that feature added to the tool.
-
Category In Database
-
Data Connectors
Please add support for Databricks' Unity Catalog
Currently, when selecting a Databricks-connection in the “Connect In-DB”-tool, and opening the “Query Builder”, only tables in the catalog named “hive_metastore” are listed. That is, Alteryx submits the following SQL query to Databricks:
Listing tables 'catalog : hive\_metastore, schemaPattern : %, tableTypes : null, tableName : %'
However, with Unity Catalog in Databricks the namespace is three-tier and there may be multiple catalogs (and not just the "hive_metastore" catalog), see https://docs.microsoft.com/en-gb/azure/databricks/lakehouse/data-objects#--what-is-a-catalog
I reached out to Alteryx support, which replied that you currently have a feature request for implementing this change (ID TDCB-4056) and they furthermore suggested that I post here.
Thanks in advance.
-
Category In Database
-
Data Connectors
Currently the Databricks in-database connector allows for the following when writing to the database
- Append Existing
- Overwrite Table (Drop)
- Create New Table
- Create Temporary Table
This request is to add a 5th option that would execute
- Create or Replace Table
Why is this important?
- Create or Replace is similar to the Overwrite Table (Drop) in that it fully replaces the existing table however, the key differences are
- Drop table completely removes the table and it's data from Databricks
- Any users or processes connected to that table live will fail during the writing process
- No history is maintained on the table, a key feature of the Databricks Delta Lake
- Create or Replace does not remove the table
- Any users or processes connected to that table live will not fail as the table is not dropped
- History is maintained for table versions which is a key feature of Databricks Delta Lake
- Drop table completely removes the table and it's data from Databricks
While this request was specific to testing on Azure Databricks the documentation for Azure and AWS for Databricks both recommend using "Replace" instead of "Drop" and "Create" for Delta tables in Databricks.


-
Category In Database
-
Data Connectors
Alteryx really needs to show a results window for the InDB processes. It is like we are creating blindly without it. Work arounds are too much of a hassle.
-
Category In Database
-
Data Connectors
We really need a block until done to process multiple calculations inDB without causing errors. I have heard that there is a Control Container potentially on the road map. That needs to happen ASAP!!!!
-
Category In Database
-
Data Connectors
Hi all,
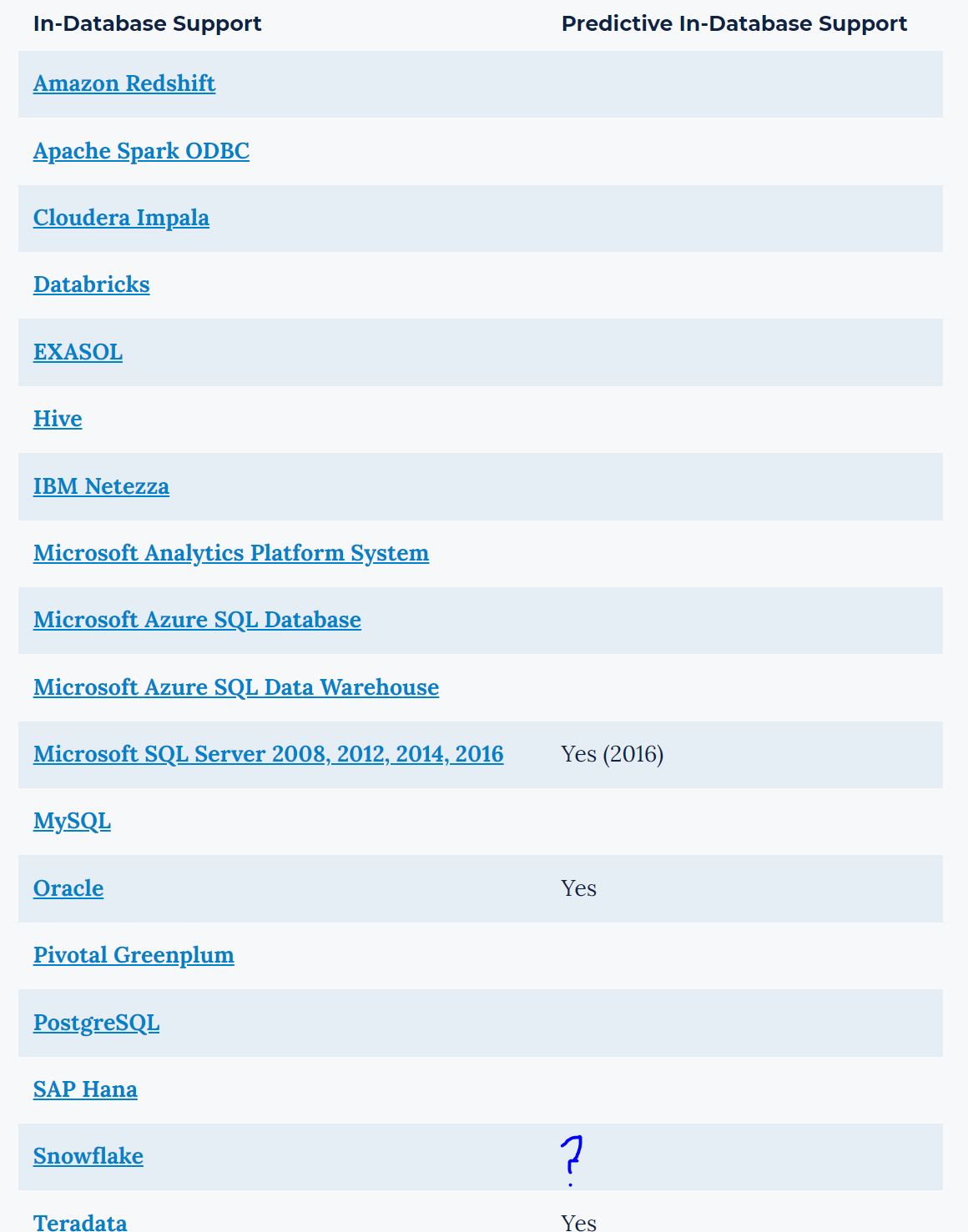
Something really interesting I found - and never knew about, is there are actually in-DB predictive tools. You can find these by having a connect-indb tool on the canvas and dragging on one of the many predictive tools.
For instance:
boosted model dragged on empty campus:

Boosted model tool deleted, connect in-db tool added to the canvas:

Boosted Model dragged onto the canvas the exact same:

This is awesome! I have no idea how these tools work, I have only just found out they are a thing. Are we able to unhide these? I actually thought I had fallen into an Alteryx Designer bug, however it appears to be much more of a feature.
Sadly these tools are currently not searchable for, and do not show up under the in-DB section. However, I believe these need to be more accessible and well documented for users to find.

Cheers,
TheOC
-
Category In Database
-
Data Connectors
For in-DB use, please provide a Data Cleansing Tool.

-
Category In Database
-
Data Connectors
Hello,
As of today, when you connect o, a database, you go through a batch of queries to retrieve which database it is ( cf https://community.alteryx.com/t5/Alteryx-Designer-Ideas/Smart-Visual-Query-Builder-for-in-db-less-te... where I suggest a solution to speed up the process) and then, Alteryx queries the metadata. In order to get the column in each table, Alteryx use a SHOW TABLES and then loop on each table. This is really slow.
However, since Hive 3.0, an information_schema with the list of columns for each table is now available. I suggest to use the information_schema.columns instead of the time-consuming loop.

PS : I don't know if it's linked to the Active Query Builder, the third-party tool behind the Visual Query Builder. In that case, it would be a good idea to update it as suggested here https://community.alteryx.com/t5/Alteryx-Designer-Ideas/Update-Query-Builder-component/idi-p/799086
Best regards,
Simon
-
Category In Database
-
Category Input Output
-
Data Connectors
Would be great if you could support Snowflake window functions within the In-DB Summarize tool
-
Category In Database
-
Data Connectors
We're not too happy with the Gallery Data Connections not being available for the IN-DB data input tool but that will hopefully be a feature to be looked at in future product improvements; Let us know if there are reasons not having this feature already.
Thank you.
-
Category In Database
-
Data Connectors
Hello,
I would like to allow my Gallery User to select the fields in my in database workflow, just like we can do in-memory. As of today, it's just impossible to do that.
Best regards,
Simon
-
Category In Database
-
Data Connectors
Hi there Alteryx team,
When we load data from raw files into a SQL table - we use this pattern in almost every single loader because the "Update, insert if new" functionality is so slow; it cannot take advantage of SSVB; it does not do deletes; and it doesn't check for changes in the data so your history tables get polluted with updates that are not real updates.
This pattern below addresses these concerns as follows:
- You explicitly separate out the inserts by comparing to the current table; and use SSVB on the connection - thereby maximizing the speed
- The ones that don't exist - you delete, and allow the history table to keep the history.
- Finally - the rows that exist in both source and target are checked for data changes and only updated if one or more fields have changed.
Given how commonly we have to do this (on almost EVERY data pipe from files into our database) - could we look at making an Incremental Update tool in Alteryx to make this easier? This is a common functionality in other ETL platforms, and this would be a great addition to Alteryx.

-
Category In Database
-
Category Macros
-
Data Connectors
-
Desktop Experience
Hi Alteryx Team!
Think an easy/useful tool enhancement would be to add a search bar on the "Tables" tab in the "Choose Table or Specify Query" popup when connecting to an In-DB source.
Current state, you have to scroll through all your tables to find the one you're looking for. Would be a HUGE help and time saver if I could just go in and search for a key word I know is in my table name.
Thanks!
-
Category Connectors
-
Category In Database
-
Data Connectors
Hi,
Standard In-DB connection configuration for PostgreSQL / Greenplum makes "Datastream-In" In-DB tool to load data line by line instead of using Bulk mode.
As a result, loading data in a In-DB stream is very slow.
Exemple
Connection configuration


Workflow

100 000 lines are sent to Greenplum using a "Datastream-in" In-DB tool.
This is a demo workflow, the In-DB stream could be more complex and not replaceable by an Output Data In-Memory.
Load time : 11 minutes.
It's slow and spam the database with insert for each lines.
However, there is a workaround.
We can configure a In-Memory connection using the bulk mode :


And paste the connection string to the "write" tab of our In-DB Connection :

Load time : 24 seconds.
It's fast as it uses the Bulk mode.
This workaround has been validated by Greenplum team but not by Alteryx support team.
Could you please support this workaround ?
Tested on version 2021.3.3.63061
-
Category In Database
-
Data Connectors
Hi Alteryx,
Can we get the R tools/models to work in database for SNOWFLAKE.
In-Database Overview | Alteryx Help
I understand that Snowflake currently doesn't support R through their UDFs yet; therefore, you might be waiting for them to add it.
I hear Python is coming soon, which is good & Java already available..
However, what about the ‘DPLYR’ package? https://db.rstudio.com/r-packages/dplyr/
My understanding is that this can translate the R code into SQL, so it can run in-DB?
Could this R code package be appended to the Alteryx R models? (maybe this isn’t possible, but wanted ask).
Many Thanks,
Chris
-
Category In Database
-
Category Predictive
-
Data Connectors
-
Desktop Experience
Hello all,
Despite a few limitations, Alteryx is great when you work with full table (i.e when you rewrite entirely the table). But in real life, very few workflows work like that :
Here are some real life use cases that should be easy to deal with on Alteryx :
-delta on a key
-delta on a key + last record based on a date
-update records
-start_date and end_date for a value
etc
Best regards,
Simon

{kind=link}
-
Category In Database
-
Data Connectors
- New Idea 216
- Accepting Votes 1,826
- Comments Requested 25
- Under Review 154
- Accepted 61
- Ongoing 5
- Coming Soon 6
- Implemented 480
- Not Planned 122
- Revisit 67
- Partner Dependent 4
- Inactive 674
-
Admin Settings
19 -
AMP Engine
27 -
API
11 -
API SDK
217 -
Category Address
13 -
Category Apps
111 -
Category Behavior Analysis
5 -
Category Calgary
21 -
Category Connectors
240 -
Category Data Investigation
75 -
Category Demographic Analysis
2 -
Category Developer
206 -
Category Documentation
78 -
Category In Database
212 -
Category Input Output
632 -
Category Interface
236 -
Category Join
101 -
Category Machine Learning
3 -
Category Macros
153 -
Category Parse
75 -
Category Predictive
77 -
Category Preparation
385 -
Category Prescriptive
1 -
Category Reporting
198 -
Category Spatial
81 -
Category Text Mining
23 -
Category Time Series
22 -
Category Transform
87 -
Configuration
1 -
Data Connectors
949 -
Desktop Experience
1,498 -
Documentation
64 -
Engine
123 -
Enhancement
282 -
Feature Request
212 -
General
307 -
General Suggestion
4 -
Insights Dataset
2 -
Installation
24 -
Licenses and Activation
15 -
Licensing
10 -
Localization
8 -
Location Intelligence
80 -
Machine Learning
13 -
New Request
178 -
New Tool
32 -
Permissions
1 -
Runtime
28 -
Scheduler
21 -
SDK
10 -
Setup & Configuration
58 -
Tool Improvement
210 -
User Experience Design
165 -
User Settings
73 -
UX
220 -
XML
7
- « Previous
- Next »
- RWvanLeeuwen on: Applying a PCA model to new data
- charlieepes on: Multi-Fill Tool
- vijayguru on: YXDB SQL Tool to fetch the required data
- apathetichell on: Github support
- Fabrice_P on: Hide/Unhide password button
- cjaneczko on: Adjustable Delay for Control Containers
-
 Watermark
on:
Dynamic Input: Check box to include a field with D...
Watermark
on:
Dynamic Input: Check box to include a field with D...
- aatalai on: cross tab special characters
- KamenRider on: Expand Character Limit of Email Fields to >254
- TimN on: When activate license key, display more informatio...
| User | Likes Count |
|---|---|
| 51 | |
| 13 | |
| 12 | |
| 9 | |
| 7 |