Alteryx Designer Desktop Ideas
Share your Designer Desktop product ideas - we're listening!Submitting an Idea?
Be sure to review our Idea Submission Guidelines for more information!
Submission Guidelines- Community
- :
- Community
- :
- Participate
- :
- Ideas
- :
- Designer Desktop
Featured Ideas
Hello,
After used the new "Image Recognition Tool" a few days, I think you could improve it :
> by adding the dimensional constraints in front of each of the pre-trained models,
> by adding a true tool to divide the training data correctly (in order to have an equivalent number of images for each of the labels)
> at least, allow the tool to use black & white images (I wanted to test it on the MNIST, but the tool tells me that it necessarily needs RGB images) ?
Question : do you in the future allow the user to choose between CPU or GPU usage ?
In any case, thank you again for this new tool, it is certainly perfectible, but very simple to use, and I sincerely think that it will allow a greater number of people to understand the many use cases made possible thanks to image recognition.
Thank you again
Kévin VANCAPPEL (France ;-))
Thank you again.
Kévin VANCAPPEL
Please improve the Excel XLSX output options in the Output tool, or create a new Excel Output tool,
or enhance the Render tool to include an Excel output option, with no focus on margins, paper size, or paper orientation
The problem with the current Basic Table and Render tools are they are geared towards reporting, with a focus on page size and margins.
Many of us use Excel as simply a general output method, with no consideration for fitting the output on a printed page.
The new tool or Render enhancement would handle different formats/different schemas without the need for a batch macro, and would include the options below.
The only current option to export different schemas to different Sheets in one Excel file, without regard to paper formatting, is to use a batch macro and include the CReW macro Wait a Second, to allow Excel to properly shut down before a new Sheet is created, to avoid file-write-contention issues.
Including the Wait a Second macro increased the completion time for one of my workflows by 50%, as shown in the screehshots below.
I have a Powershell script that includes many of the formatting options below, but it would be a great help if a native Output or Reporting tool included these options:
Allow options below for specific selected Sheet names, or for All Sheets
AllColumns_MaxWidth: Maximum width for ALL columns in the spreadsheet. Default value = 50. This value can be changed for specific columns by using option Column_SetWidth.
Column_SetWidth: Set selected columns to an exact width. For the selected columns, this value will override the value in AllColumns_MaxWidth.
Column_Centered: Set selected columns to have text centered horizontally.
Column_WrapText: Set selected columns to Wrap text.
AllCells_WrapText: Checkbox: wrap text in every cell in the entire worksheet. Default value = False.
AllRows_AutoFit: Checkbox: to set the height for every row to autofit. Default value False.
Header_Format: checkbox for Bold, specify header cells background color, Border size: 1pt, 2pt, 3pt, and border color, Enable_Data_Filter: checkbox
Header_freeze_top_row: checkbox, or specify A2:B2 to freeze panes
Sheet_overflow: checkbox: if the number of Sheet rows exceeds Excel limit, automatically create the next sheet with "(2)" appended
Column_format_Currency: Set selected columns to Currency: currency format, with comma separators, and negative numbers colored red.
Column_format_TwoDecimals: Set selected columns to Two decimals: two decimals, with comma separators, and negative numbers colored red.
Note: If the same field name is used in Column_Currency and Column_TwoDecimals, the field will be formatted with two decimals, and not formatted as currency.
Column_format_ShortDate: Set selected columns to Short Date: the Excel default for Short Date is "MM/DD/YYYY".
File_suggest_read_only: checkbox: Set flag to display this message when a user opens the Excel file: "The author would like you to open 'Analytic List.xlsx' as read-only unless you need to make changes. Open as read-only?
vb code: xlWB.ReadOnlyRecommended = True
File_name_include_date_time: checkboxes to add file name Prefix or Suffix with creation Date and/or Time
========
Examples:
My only current option: use a batch macro, plus a Wait a Second macro, to write different formats/schemas to multiple Sheets in one Excel file:

Using the Wait a Second macro, to allow Excel to shut down before writing a new Sheet, to avoid write-contention issues, results in a workflow that runs 50% longer:

The Append Fields tool will issue a Warning if/when the Source data stream has no records that reads something like this:
Append Fields (823) There are no records present in the source.
I can imagine many situations when this issue should be flagged as a Warning. However, I have use cases when both the Source and Target data streams are expected to be empty. Because it is a common, expected scenario, I do not want it flagged as a Warning for the user.
My Idea: provide another option to suppress warnings for this situation.
Perhaps it could be a standalone checkbox, for example:
[x] Suppress Warning when both source and target streams are empty
Alternatively, the tool currently has 3 options to manage warnings or errors related to "too many" records. Perhaps this could be added as a 4th option to the dropdown list, although that would necessitate changing the label slightly.
I sometimes have to swap (change the order of) two tools in a flow. It is a bothersome task, especially when there are many connections around them. I would like to suggest two new features for such a situation. It would help if either could be realized.
Swap tools
Select two tools, right-click, and select "Swap" option.

Move and connect around
Drag a tool holding down Alt key (or something) to move it from the stream and connect around. After that, we can drag and drop the tool to the right place.

Right now, the List Box interface tool allows end users to select multiple options of fields for selections, filtering, and formatting/formulating.
However, it doesn't do quite as good when a use case has over 1,000+ columns/fields. This is made even more complicated with each column/field having somewhat similar naming conventions thereby causing confusion.
Having a search function, as made available in standard Select Tools, Join tools, and other tools that has filtering capacity, will be most helpful for developers to give maximum flexibility to end users.
This is a pretty quick suggestion:
I think that there are a lot of formulas that would be easier to write and maintain if a SQL-style BETWEEN operator was available.
Essentially, you could turn this:
ToNumber([Postal Code]) > 1000 AND ToNumber([Postal Code]) < 2500
Into this:
ToNumber([Postal Code]) BETWEEN 1000 AND 2500
That way, if you later had to modify the ToNumber([Postal Code]), you only have to maintain it once. Its both aesthetically pleasing and more maintainable!
The basic premise is this:
Phantom spacing. Basically something that looks like it has spaces on Excel but is actually formatted as an indentation.
Unfortunately, to read the indentation we will need either a VBA prep or read the XML inside. The latter of which is difficult.
As to VBA, the general steps are to create an indentation formula in order to see the numbers, then go from there. The idea is credited to @clmc9601 as we discussed privately.
As of now, I do not see anyway to do this on Alteryx as a function or even expression. It would be very helpful especially reading trial balances or even Bloomberg outputs as they are formatted with indentation.
Reading indentation from Excel or any other file within Alteryx will be much appreciated, especially in actuarial and finance spaces.
Not sure I'd call this a user setting, but I couldn't figure out the right heading this belongs to.
When opening files, there are often times a couple of files at that aren't run on any kind of schedule or set time frame but you come back to when you need to run them.
There should be a way to set "FAVORITES" for a handful of files that you find yourself referring to on a repeated basis, but too far back to be on the 'recents' list because you open too many other files.
Referencing the previous idea: Inputs/Output should have the option to read/write a compressed file (ZIP or GZIP)
This idea has been implemented for inputting .zip files. However, we still need to use the run command workaround for outputs. It's very common for many users to want to output their .csv, .xlsx, .pdf to a .zip. The functionality would also need to extend to Gallery.
See the following links for people that are looking for this type of functionality:
https://community.alteryx.com/t5/Alteryx-Designer-Discussions/Output-files-to-ZIP/td-p/163502
https://community.alteryx.com/t5/Alteryx-Designer-Discussions/Zip-files/td-p/151456
Feel free to merge this idea with the previous one for continuity.
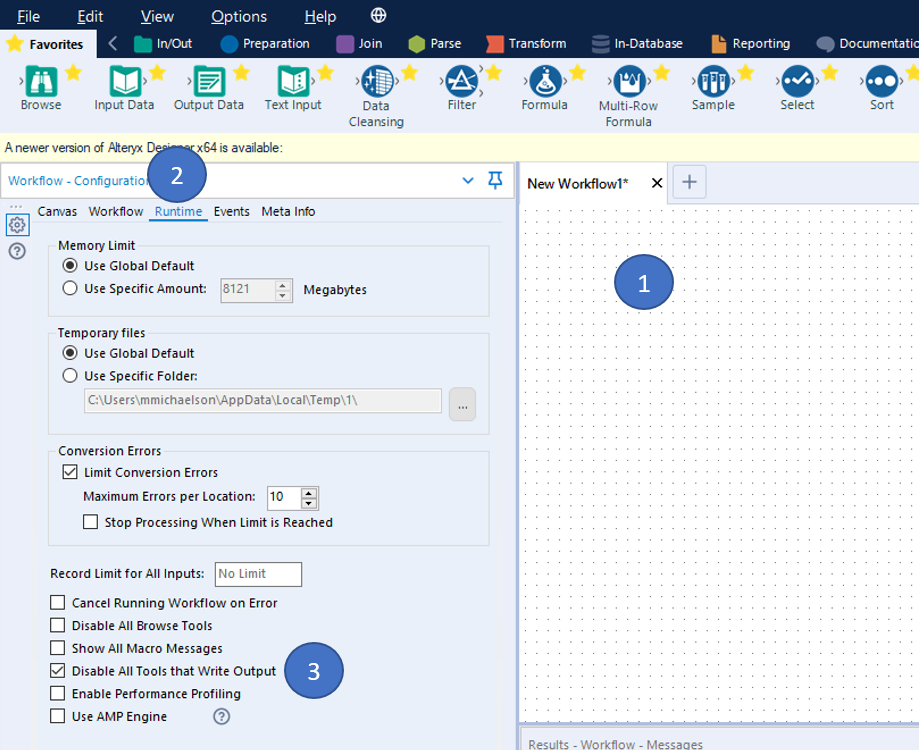
Today, there is an checkbox to "Disable All Tools that Write Output" within the Runtime settings for a workflow. Setting this option requires at least 3 clicks:
- Click on the canvas
- Click the "Runtime" tab in the Configuration pane
- Click the checkbox
Could a keyboard shortcut be added for this? I've spoken to several users who leverage this feature and, while it is already a time saver, it seems helpful enough where a keyboard shortcut is warranted.
Hello all,
I'm currently learning Pythin language and there is this cool feature : you can multiply a string

Pretty cool, no? I would like the same syntax to work for Tableau.
Best regards,
Simon
Hello all,
Sometimes, when you have too much time to retrieve your tables metadas, you can have this message
Initialization Timed Out: Workflow must be run for field meta info to be accurate.
From what I understand, it's Alteryx and the source system that drives the time out value. However, I have some cases where the long time is "normal" and that really hurts the user experience.
So, I would like the ability in settings to change the default value.
Best regards,
Simon

Hi
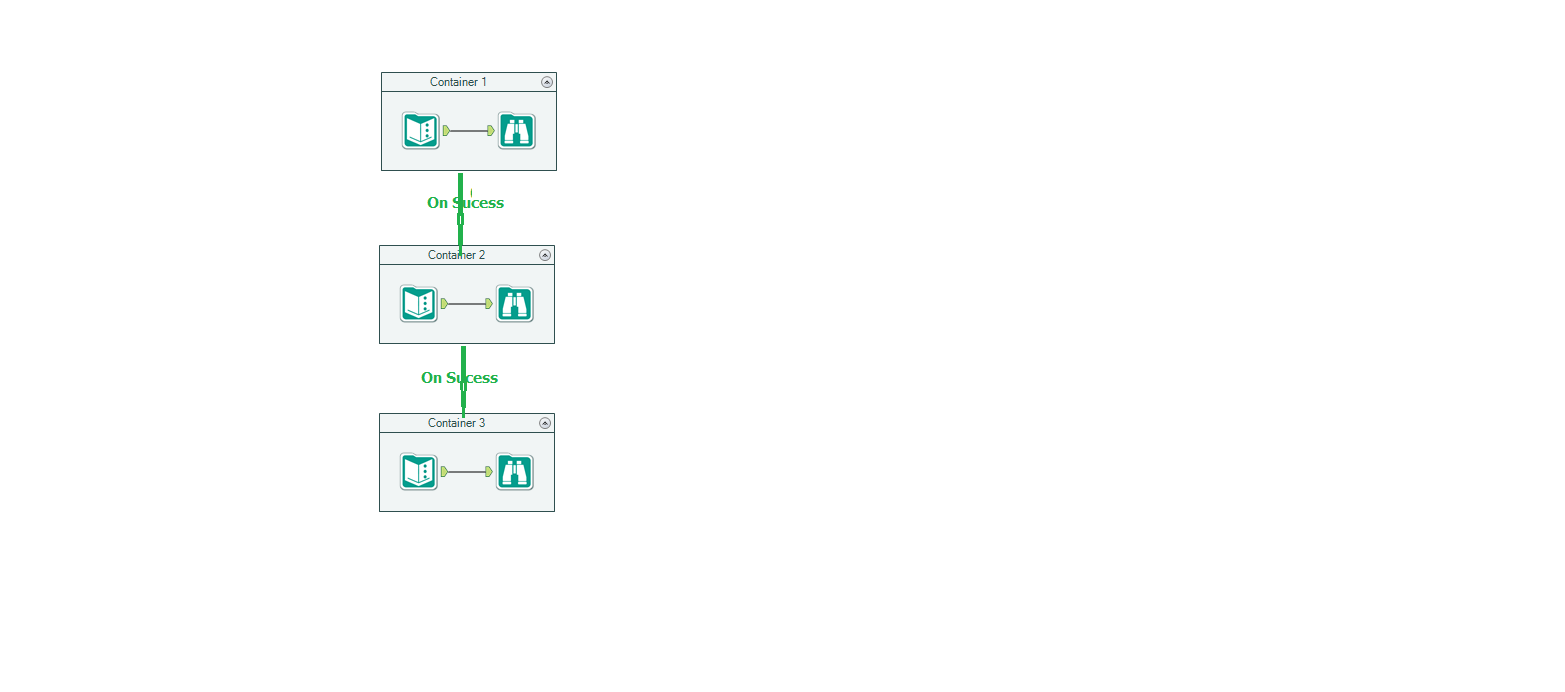
Wanted to control the order of execution of objects in Alteryx WF but right now we have ONLY block until done which is not right choice for so many cases
Can we have a container (say Sequence Container) and put piece of logic in each container and have control by connecting each container?
Hope this way we can control the execution order
It may be something looks like below
Hello all,
According to wikipedia https://en.wikipedia.org/wiki/Materialized_view
In computing, a materialized view is a database object that contains the results of a query. For example, it may be a local copy of data located remotely, or may be a subset of the rows and/or columns of a table or join result, or may be a summary using an aggregate function.
The process of setting up a materialized view is sometimes called materialization.[1] This is a form of caching the results of a query, similar to memoization of the value of a function in functional languages, and it is sometimes described as a form of precomputation.[2][3] As with other forms of precomputation, database users typically use materialized views for performance reasons, i.e. as a form of optimization.
So, I would like to create that in Alteryx, for obvious performance reasons in some use cases.
This is not a duplicate of https://community.alteryx.com/t5/Alteryx-Designer-Desktop-Ideas/In-DB-Create-View/idi-p/157886
Best regards,
Simon
Hello all,
According to wikipedia :
https://en.wikipedia.org/wiki/Embedded_database
An embedded database system is a database management system (DBMS) which is tightly integrated with an application software; it is embedded in the application.
It's often like a single file/dll that you can use inside an application without the user having to connect (or at least to configure it) to it (it's all done inside the application). So, it's widely portable.
Why it does matter ?
As of today, there is not a single example of in database workflow because all the supported databases need the user to:
1/install an odbc driver (most of time, he won't have the rights to do so)
2/configure an odbc connection (sometimes, he doesn't have the rights to)
3/configure a connection on Alteryx (ok, he can)
So it requires IT action, which can be pretty long (in ùany organization, it requires several weeks !!). And even with all of that,the users must be granted privilege to access database and the customer need to develop its own examples and write its own specific documentation.
Well, this is not efficient.
What I suggest is Alteryx to use one of embedded database for training support/one tool examples. SQLlite seems good, maybe a more analytics oriented (like DuckDB ) would be more efficient.
The requirement are, I think, the following :
-OpenSource and free
-Fast
-SQL compliant
-With a bulk load ability
Best regards,
Simon
Similar to this idea, I think it would be really helpful to be able to search for fields in the dropdowns when using the Sort tool. Having to scroll through all of the possible field names can be a chore if you have 50+

I would like to see Designer offer me the ability to chain workflows together where once Workflow A completes, Workflow B will automatically start. There are times when linear processing is required in order to avoid dependency issues and/or for making it easier to organize complex processes. It would require outputting results to static files and it would take longer to process than the standard approach, but that is an expected trade-off. Offering a GUI drag-drop "orchestrator" to tell Designer the order of operation would be even better than having to manually open each workflow and tell it which workflow to kick off next.
Hello,
Just like Monetdb or Vertica, Clickhouse is a column-store database, claiming to be the fastest in the world. It's available on Cloud (like Snowflake), linux and macos (and here for free, it's open-source). it's also very well ranked in analytics database https://db-engines.com/en/system/ClickHouse and it would be a good differenciator with competitors.
https://clickhouse.com/
it has became more popular than Greenplum that is supported : (black snowflake, red greenplum, orange clickhouse)


Best regards,
Simon
I can't even count how often I looked at an Excel, CSV or even YXDB file, where I KNEW that it was generated by Alteryx, but I couldn't remember the workflow. Currently, I have to simply go through all workflows I ever build and see if I can find it.
Theoretically, I could use a text-search across all workflows and see if I can find the output names - problem here: Most of my output filenames are generated dynamically on the run.
It would be amazing if Alteryx could simply write the Workflow name (maybe even path) into the metadata of a file.

{kind=link}
{kind=link}
(Screenshot from Google, as my os is set to German)
How about, we write "This file was created with by "Create Controlling Reports.yxmd on 2023-02-06 with Alteryx Designer 2021.4.298434" in the field 'Comments'?
This would make it extremely easy to find what workflow the file generated. I think it would be an option to talk about "filepath" instead of filename, but the filepath could include the local machine name, which might include GDPR information.
@Community: Is there any additional information that you'd like to see in the metadata?
Best
Alex
Hello all,
So, right now, we have two very separated products : Alteryx Designer and Alteryx Designer Cloud. But what if you want to go from Alteryx Designer on your desktop to the cloud ?
well, you will have to rewrite every single workflow because you can't publish or import your current workflow on Alteryx Designer Cloud. You cannot export Designer Cloud workflow to Alteryx Designer on Desktop either.
This is a huge limitation on cloud implementation and sells and the ONLY product I know that's not compatible between on-premise and cloud.
Please Alteryx, this is a no-brainer situation if you want to convince your customers !
Best regards,
Simon
The Find Replace tool has a checkbox to do a case insensitive find. It would be fabulous if the Join and Join Multiple tools had a similar checkbox.
I frequently have to create a new field in each data stream, convert the data I want to join on to upper case, perform the join and remove the extra "helper" fields. Using the helper field is needed in my case in order to preserve unique capitalization (i.e., acronyms within the string, etc.).
- New Idea 301
- Accepting Votes 1,790
- Comments Requested 22
- Under Review 169
- Accepted 54
- Ongoing 8
- Coming Soon 7
- Implemented 539
- Not Planned 110
- Revisit 59
- Partner Dependent 4
- Inactive 674
-
Admin Settings
20 -
AMP Engine
27 -
API
11 -
API SDK
222 -
Category Address
13 -
Category Apps
113 -
Category Behavior Analysis
5 -
Category Calgary
21 -
Category Connectors
247 -
Category Data Investigation
79 -
Category Demographic Analysis
2 -
Category Developer
211 -
Category Documentation
80 -
Category In Database
215 -
Category Input Output
646 -
Category Interface
242 -
Category Join
105 -
Category Machine Learning
3 -
Category Macros
154 -
Category Parse
76 -
Category Predictive
79 -
Category Preparation
395 -
Category Prescriptive
1 -
Category Reporting
199 -
Category Spatial
81 -
Category Text Mining
23 -
Category Time Series
22 -
Category Transform
89 -
Configuration
1 -
Content
1 -
Data Connectors
969 -
Data Products
3 -
Desktop Experience
1,558 -
Documentation
64 -
Engine
127 -
Enhancement
348 -
Feature Request
213 -
General
307 -
General Suggestion
6 -
Insights Dataset
2 -
Installation
24 -
Licenses and Activation
15 -
Licensing
13 -
Localization
8 -
Location Intelligence
80 -
Machine Learning
13 -
My Alteryx
1 -
New Request
209 -
New Tool
32 -
Permissions
1 -
Runtime
28 -
Scheduler
24 -
SDK
10 -
Setup & Configuration
58 -
Tool Improvement
210 -
User Experience Design
165 -
User Settings
81 -
UX
223 -
XML
7
- « Previous
- Next »
- asmith19 on: Auto rename fields
- Shifty on: Copy Tool Configuration
- simonaubert_bd on: A formula to get DCM connection name and type (and...
-
 NicoleJ
on:
Disable mouse wheel interactions for unexpanded dr...
NicoleJ
on:
Disable mouse wheel interactions for unexpanded dr...
- haraldharders on: Improve Text Input tool
- simonaubert_bd on: Unique key detector tool
- TUSHAR050392 on: Read an Open Excel file through Input/Dynamic Inpu...
- jackchoy on: Enhancing Data Cleaning
- NeoInfiniTech on: Extended Concatenate Functionality for Cross Tab T...
- AudreyMcPfe on: Overhaul Management of Server Connections