Alteryx Designer Desktop Ideas
Share your Designer Desktop product ideas - we're listening!Submitting an Idea?
Be sure to review our Idea Submission Guidelines for more information!
Submission Guidelines- Community
- :
- Community
- :
- Participate
- :
- Ideas
- :
- Designer Desktop: New Ideas
Featured Ideas
Hello,
After used the new "Image Recognition Tool" a few days, I think you could improve it :
> by adding the dimensional constraints in front of each of the pre-trained models,
> by adding a true tool to divide the training data correctly (in order to have an equivalent number of images for each of the labels)
> at least, allow the tool to use black & white images (I wanted to test it on the MNIST, but the tool tells me that it necessarily needs RGB images) ?
Question : do you in the future allow the user to choose between CPU or GPU usage ?
In any case, thank you again for this new tool, it is certainly perfectible, but very simple to use, and I sincerely think that it will allow a greater number of people to understand the many use cases made possible thanks to image recognition.
Thank you again
Kévin VANCAPPEL (France ;-))
Thank you again.
Kévin VANCAPPEL
In some cases, the information about incoming columns to tools are (temporarily) forgotten, e.g. if Autoconfig is switched off, if the incoming connection is temporarily missing, or if column names are generated dynamically and the workflow has not been executed, yet.
Many tools deal with that situation well, e.g. Selection, Formula, or Summarize. In these cases, the tools tell the user that they cannot find incoming columns, but they preserve the configuration so that the user still can (at least partially) work on these tools and important information on the configuration is not lost:
Example Select Tool
- First step: Connections present, configuration typed in:
- Second step: Connection cut, confguration opened. The configuration looks screwed up but implicitly contains all settings:
- Third step: Connection re-connected. The configuration is as before:



Other tools behave the opposite, for example Unique or Macro Input (an for sure many other tools). If the incoming columns are currently unknown to the Designer and you click once on the symbol, the entire configuration of this tool is lost. You might try to get the configuration back by pressing undo. This, in most cases does not work. Or, even worse, you find out what happened later when it's too late for undo. In this case, you either have an old version of that workflow to look up the configuration or you have to re-develop it. In any case, this is unnecessary and time-consuming software behaviour.
Example Unique Tool
- Step 1: Connections present, configuration typed in:
- Step 2: Connection cut, confguration opened. The configuration is empty:
- Step 3: Connection re-connected: The entire configuration is permanently lost:



I wasn't sure whether I should report this as a bug or a feature enhancement. It is somehow in between. Two aspects tell me that this should be changed:
- Inconsistent behaviour of different tools for now reason,
- Easy loss of programming work, resulting in time-consuming bug fixing.
Please make sure that all tools preserve their configuration also if information on incoming columns is temporarily lost.
-
Enhancement
-
UX
Containers are a great feature. They allow us to create larger workflows in smaller canvases, and manage the flow and appearance of our work. However the design whether intentional or flawed that allows the container window to interact with the layers behind it is annoying. Connection wires should not redirect within a container because of things on the canvas behind the container. Likewise if I have a container open, I should not be able to grab a tool or container behind the open container through the container canvas. Please fix this flaw.
-
Enhancement
-
UX
Hello, I believe this feature will be useful for many people.
The idea is to select multiple instances of the same tool and the configuration that we set will be applied to all the selected tools. Furthermore, it will be useful to be an easy way to select all instances of the same tool across a workflow with a shortcut in order to edit them more easily.
-
Enhancement
-
UX
I am suggesting an addition to the Auto Field Tool. Create an option that allows only auto sizing of the fields and does not change the field type. A check box that says Auto Size Only. The tool would recognize any fields that can be resized based on their incoming data field type and will not change the data type. The resizing function is very helpful to maximize workflow performance, but I currently do not use it much because it guesses wrong on the data types. This causes problems also when data inputs change. Whereas setting to auto size only, it can streamline the data but let the user be confident the data types would not change.
Thank You
-
Category Preparation
-
Enhancement
To embed the "Not ok" filter option in the browse tool

-
Category Input Output
-
Enhancement
-
UX
As of version 2023.1 once a workflow is locked, it cannot be unlocked. If Alteryx can unlock it, can it be made into a user option?
My idea has two parts. See the images for examples.
1. Add an option on the lock screen so the user can get an unlock passkey.
Passkey is either generated by Alteryx or set by user
2. Change the behavior when trying to open a locked file by giving the user an option to enter the unlock passkey.
Same behavior if there is no passkey
Dialog box with passkey input and cancel button if a passkey exists
This would be useful as a way to revise or edit a workflow or update the expiration date on the existing workflow without having to reload or resave a new file.


-
Enhancement
-
User Settings
Dynamic macros that fetch the current version at every run time vs storing a static copy of the macro with the workflow at publish time are challenging to pull off using shared drives.
This suggestion is to store dynamic macros in the gallery and secure their use with collections.
-
Category Macros
-
Enhancement
Changing the Macro Input tool in an existing macro is dangerous and can result in unmapped fields or lost connections in workflows using the macro. For example, we have a widely used macro for which we'd like to change the name of an input field, change it's default type from Date to DateTime, make it optional while keeping other fields mandatory. Currently, we cannot find a solution which would not require us to fix each workflow using the macro after changing it. We should be able to change the field names, field types (e.g. String to V_WString, Date to DateTime), select optional fields and do other modifications to Macro Input without having to update each workflow using the macro. The new Macro Input UI could be enhanced with a window similar to that of Select tool's. Technically, the Macro Input fields could have a unique ID by which they would be recognised in workflows, so the field names would just be aliases that could be changed without losing the mapping. In summary, we are restricted to our initial setup of Macro Input and it is very complicated to change it afterwards, especially if the macro is used widely.
-
Category Interface
-
Enhancement
Right click + "Insert After" and Right click + "Paste After" should behave the same. In the picture below I show the two cases. Currently, the "Insert After" option inserts a tool between the selected tool and the tools after it. The "Paste After" creates a new branch with the pasted tool. I think the "Paste After" should behave the same as the "Insert After": paste the tool on the existing branches. In case we want to create a new branch, we will paste the tool and connect a new branch to it.

-
Enhancement
-
UX
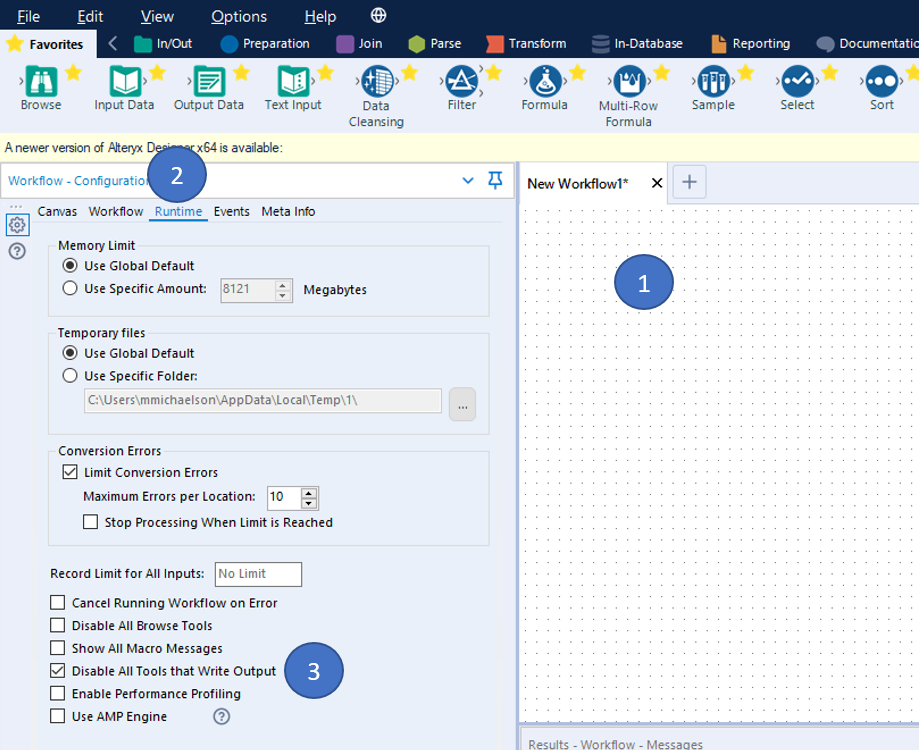
Today, there is an checkbox to "Disable All Tools that Write Output" within the Runtime settings for a workflow. Setting this option requires at least 3 clicks:
- Click on the canvas
- Click the "Runtime" tab in the Configuration pane
- Click the checkbox
Could a keyboard shortcut be added for this? I've spoken to several users who leverage this feature and, while it is already a time saver, it seems helpful enough where a keyboard shortcut is warranted.
-
Enhancement
-
UX
Quite often, I would love to be able to use Browse tools already while the workflow is still running, if that specific Browse tool has completed (green box around). This would help to debug and save a lot of time.

In this case, the lower Browse tool would be enabled already now.
-
Engine
-
Enhancement
In the RecordID tool, provide additional options for the creation of the ID, specifically allow for the ID to 'Intervals'.
For example, Record ID every 10, meaning instead of creating an ID of 1, 2, 3, 4, 5 .... you could create an interval of your choosing, the most obvious would by 10 or 100 thus your ID's would then be 10, 20, 30, 40 .... or 100, 200, 300, 400, 500 ... etc.
-
Category Preparation
-
Enhancement
After closing the Table or Query option on an Input Data tool, the table layout in the Visual Query Builder view gets reset to stacking the tables/views on top of each other. It would be great if the layout stayed the way I left it the last time I closed it.


-
Category Input Output
-
Enhancement
As an international organization we deal with clients in multiple-countries.
Name matches for names including Chinese characters generate a unicode conversation warning and are excluded from the fuzzy match.
It would be good if fuzzy match could be enhanced to handle Chinese characters.
-
Category Join
-
Enhancement
Currently, the "SQL editor" window only contain a box for typing text in, we could not see the schema and table on it's side as a reference, we need to jump back and force between "Visual Query Builder" and "SQL Editor" search for table and column names. If we could see the database schema and table in the SQL Editor interface, it will save us a lot of time.
-
Enhancement
-
Scheduler
Hi, I was looking for this but couldn't find a similar idea, so I post a new one. If someone knows about a similar idea, please ask the moderators to mer
CountChars(<String>, <char to count>,<case sensitive>)
Where <char to count> and <case sensitive> are optional parameters.
If <char to count> is not provided, the funtion will return the total character count within the <String>.
If <char to count> is provided, it'll return the number of ocurrences of that character within the <String>.
PS: For those tempted to suggest a workaround, I've been using REGEX_CountMatches() for this. Actually, the focus is to simplify user's experience and workflow performance providing a native function, instead of using REGEX which it's very demmanding on resources.
-
Category Preparation
-
Enhancement
Using File Browse on Excel files first of all is inconsistent between running the Analytical App in the Designer and in the Gallery:
- In the Designer, the user is not being asked which Excel workflow shall be selected.
- In the Gallery, the user is always asked which Excel workflow shall be selected.
Depending on the use case, both behaviours can be the right one:
- To load a specific Excel file worksheet, the dialog for workflow selection is appropriate.
- When working with the entire Excel file (copying, getting the list of worksheets, etc.), the dialog is not helpful.
Thus, my idea is as follows:
- Add a checkbox to the File Browse tool which determines whether the worksheet selection dialog shall be opened (and the output will be <filename>.<ext>|<worksheet>) or not (and the output will be <filename>.<ext>) in case of Excel file selected.
- Make behaviour consistent in Alteryx Designer and Gallery.

{kind=link}
{kind=link}
{kind=link}
-
Category Input Output
-
Enhancement
This is a general request for uniform methods of connecting to data sources. The management of data connections is currently varied, and configurations/updates are completely different across connections.
-
Enhancement
-
User Settings
Enhancement request for the option to Encrypt ODBC credentials instead of just hashing them
-
Category Input Output
-
Enhancement
Hello all,
A few weeks ago Alteryx announced inDB support for GBQ. This is an awesome idea, however to make it run, you should use Oauth2 Authentication means GBQ API should be enabled. As of now, it is possible to use Simba ODBC to connect GBQ. My idea is to enhance the connection/authentication method as we have today with Simba ODBC for Google BigQuery and support inDB. It is not easy to implement by IT considering big organizations, number of GBQ projects and to enable API for each application. By enhancing the functionality with ODBC, this will be an awesome solution.
Thank you for voting
Albert
-
Category In Database
-
Enhancement
- New Idea 257
- Accepting Votes 1,818
- Comments Requested 24
- Under Review 169
- Accepted 56
- Ongoing 5
- Coming Soon 11
- Implemented 481
- Not Planned 118
- Revisit 64
- Partner Dependent 4
- Inactive 674
-
Admin Settings
20 -
AMP Engine
27 -
API
11 -
API SDK
218 -
Category Address
13 -
Category Apps
112 -
Category Behavior Analysis
5 -
Category Calgary
21 -
Category Connectors
245 -
Category Data Investigation
76 -
Category Demographic Analysis
2 -
Category Developer
208 -
Category Documentation
80 -
Category In Database
214 -
Category Input Output
636 -
Category Interface
238 -
Category Join
102 -
Category Machine Learning
3 -
Category Macros
153 -
Category Parse
76 -
Category Predictive
77 -
Category Preparation
391 -
Category Prescriptive
1 -
Category Reporting
198 -
Category Spatial
81 -
Category Text Mining
23 -
Category Time Series
22 -
Category Transform
87 -
Configuration
1 -
Data Connectors
958 -
Data Products
3 -
Desktop Experience
1,524 -
Documentation
64 -
Engine
125 -
Enhancement
315 -
Feature Request
212 -
General
307 -
General Suggestion
4 -
Insights Dataset
2 -
Installation
24 -
Licenses and Activation
15 -
Licensing
12 -
Localization
8 -
Location Intelligence
80 -
Machine Learning
13 -
New Request
188 -
New Tool
32 -
Permissions
1 -
Runtime
28 -
Scheduler
24 -
SDK
10 -
Setup & Configuration
58 -
Tool Improvement
210 -
User Experience Design
165 -
User Settings
78 -
UX
223 -
XML
7
- « Previous
- Next »
- rpeswar98 on: Alternative approach to Chained Apps : Ability to ...
-
 caltang
on:
Identify Indent Level
caltang
on:
Identify Indent Level
- simonaubert_bd on: OpenAI connector : ability to choose a non-default...
- maryjdavies on: Lock & Unlock Workflows with Password
- nzp1 on: Easy button to convert Containers to Control Conta...
-
Qiu
on:
Features to know the version of Alteryx Designer D...
- DataNath on: Update Render to allow Excel Sheet Naming
- aatalai on: Applying a PCA model to new data
- charlieepes on: Multi-Fill Tool
- seven on: Turn Off / Ignore Warnings from Parse Tools