Featured Ideas
Hello,
After used the new "Image Recognition Tool" a few days, I think you could improve it :
> by adding the dimensional constraints in front of each of the pre-trained models,
> by adding a true tool to divide the training data correctly (in order to have an equivalent number of images for each of the labels)
> at least, allow the tool to use black & white images (I wanted to test it on the MNIST, but the tool tells me that it necessarily needs RGB images) ?
Question : do you in the future allow the user to choose between CPU or GPU usage ?
In any case, thank you again for this new tool, it is certainly perfectible, but very simple to use, and I sincerely think that it will allow a greater number of people to understand the many use cases made possible thanks to image recognition.
Thank you again
Kévin VANCAPPEL (France ;-))
Thank you again.
Kévin VANCAPPEL
When building join operations in Alteryx, it can be time-consuming to manually scroll through long lists of fields to find the right one to join on, especially when working with large datasets or unfamiliar schemas.
It would be great to have a search-as-you-type filter in the Join tool’s field selection interface. Similar to the existing field selector search, this feature would allow users to start typing a field name and instantly see a filtered list of partial matches. This would significantly speed up the process of identifying and selecting the correct join fields and reduce the risk of selecting incorrect fields due to visual clutter.
- Category Join
- Desktop Experience
- New Request
I would like the parse tools (regex, split to columns...) to by defualt, not point at any column.
The parse tools need to be pointed at a column, however they by defualt configure them selves to point at the first column. Every time I use them, I enter the other configuration options, such as a regular expression, then hit run. After hitting run, my output column will be populated with only null values yet I will recieve no error.
The reason for this, is 100% EBKAC (error between keyboard and chair), as I have forgotton to point the tool to the correct column, and instead its looking at the defualt (first column)
If the defualt option didnt exist, or was blank, the tool would then error telling me to think about what im doing and point the tool to the correct column.
I believe this change in the tools defualt behaviour would save hours of debug time, wondering why my regex statment isnt working, when in actual fact im just looking at the wrong column.
- Category Parse
- Desktop Experience
- Enhancement
When working within the Table Tool, there are many options to help users format the width of their columns (i.e. Automatic, Fixed, or Percentage).
It would be nice to see an option added to disable word-wrapping. Meaning, expand to encompass the header or data within the field so that each row is of uniform height regardless of the option:
Fixed: The rest of the data would just be masked like in excel:

Percentage: Same as fixed (above), but relative to the variable width...

Automatic: Resizing to the required width, regardless.
- It would also be nice to have options under automatic, akin to constraints
- Automatic, but with a maximum width of...
- Automatic, but with a minimum width of....
- But regardless without word-wrapping
Why this matters: When producing automation, especially for finalized outputs such as reports and tables; having maximum control over the output format is vital to ensuring downstream users don't have to continue to manipulate the output to suit their needs. Maybe this isn't best practice, but when has customer demands ever taken a backseat to best practices! 😉
- Category Reporting
- Desktop Experience
- Enhancement
In the Table tool, is there a way to edit the bar graph's max and min values using a formula based on table values, rather than a fixed value?
For Example, the automatic selection may choose bounds of 0 and 3324539 to include all values. Still, realistically, 100% needs to be a specific value from the table, with batch reports making this amount dynamic.
- Category Reporting
- Desktop Experience
- Enhancement
The current update notification in Alteryx Designer can feel overly persistent and disruptive — especially for enterprise users whose Designer must stay compatible with an Alteryx Server version. Users often see repeated prompts to upgrade Designer to the newest version, even when doing so would break compatibility with their organization’s Server, which can cause errors, confusion, or rework.
Proposed Solution:
Server Version Awareness:
When Designer is connected to Alteryx Server, automatically check the Server version and suppress any upgrade prompt that would lead to a version mismatch.
Flexible Dismissal:
Allow users to snooze or permanently dismiss the update notification for the current version cycle - or dismisal longer than 30 days which is the current max - rather than re-seeing the prompt each launch.
Impact:
Prevents accidental incompatibility between Designer and Server
Reduces user frustration with repetitive prompts
Why This Matters:
Many organizations cannot upgrade Designer independently of Server, and compatibility mismatches lead to support tickets and lost productivity. A smarter, quieter update experience respects these realities and makes version management more reliable for everyone.
- Admin Settings
- Desktop Experience
- Enhancement
In complex Alteryx workflows, it can be hard to navigate between different tool containers - especially when there are dozens spread across in a large canvas.
I would love a feature where users could create a 'table of contents' using clickable text or bookmarks at the top of the workflow. For example, Clicking on a text label named 'Output Calculation' would automatically scroll to view to the Tool Container named 'Output Calculation'.
Suggested Implementation ideas :
- Text boxes or Comment Tools support clickable links that scroll the canvas to a specific container or tool.
- Add a new 'Bookmark' or 'Jump To' action tied to container names or Tool IDs.
- Right click on a text label or container and choose 'Link to' or 'Scroll to this container'.
- Use CTRL + Click or ALT + Click behavior on a text comment to jump.
This would massively improve usability and workflow navigation, especially for large teams or workflows that are shared across departments.
Inspiration :
Tools like POWER BI and TABLEAU allow similar dashboard or bookmark style navigation . Implementing this in Alteryx designer would be a game changer.
- Category Interface
- Desktop Experience
- Enhancement
- New Request
Hello,
The Data source window allow severla kind of connections like quick connect, ODBC, etc. But the order is not the same and this is confusing :

Best regards,
Simon
- Category Input Output
- Desktop Experience
- Enhancement
- User Settings
Currently the simulation sampling tool doesn't accept model objects from time series tools as a model input. It would be beneficial if it could so one could run simulations from Time series output (or a new tool is built to offer this functionality)
- Category Prescriptive
- Category Time Series
- Desktop Experience
- Enhancement
The global constants, specifically the user-defined ones (within the Workflow configuration) are a great tool for making quick changes. I would love to be able to include the value of these constants directly within a comment: the Comment tool, the captions for Tool & Control Containers, or the Annotation of individual tools. My immediate use-case would be to clearly show what the constants are set to, directly on the canvas, though there are certainly a lot of other uses as well.
- Category Documentation
- Desktop Experience
- Enhancement
It would be great for the Run Until Selected Tool to be able to used on Browse tools. In complex workflows, it is useful for testing certain parts and investigating all records in the Browse component instead of the subset previewed in the previous tool leading up to the Browse tool.
- Desktop Experience
- Enhancement
Hello,
Could there be a way to explore the details of the results window by double-clicking on a value of the Browser profile?
Basically if the profile of a field in the Browser tells me that there are x records meeting that value, could they be selected by double-clicking on that value in the profile? A bit like when you explore the underpinning rows in a pivot table in Excel; if you want to see which records meet the criteria, you double-click on the value.

For example clicking twice either on the label or the count and the specific records would show.
- Category Input Output
- Data Connectors
- Desktop Experience
- Enhancement
I would like a function to be added that pulls the weekending date of an entered date.
For example, the week ending date for today, 2025-06-10 would be 2025-06-14.
It could be called DateTimeWeekEnd and look like DateTimeWeekEnd("2025-06-10","Saturday")
The value entered first would be a date or field with an optional parameter to choose Saturday or Sunday for the week ending date. I would think Saturday would be the default week ending date but I am not sure.
- Category Time Series
- Desktop Experience
- New Request
As part of the options of the select tool, it would be really helpful if the 'Change Field type of Highlighted Fields' included the Forced type which would detect for each highlight field, the current type, and change it to the forced version of that type. Currently we need to go through each column to achieve this, and with a lot of columns (that are not consistent across different sheets, so a .yxft is not suitable) this is a massive pain. It seems fairly straight forward to add this as an option called 'forced' or something alongside the other data types
- Category Preparation
- Desktop Experience
- Enhancement
I've seen a few older threads on this but wanted to bring it up again.
I have numerous workflows in which I have built in "fail safes" to prevent passing bad data out to downstream databases/reports. I have Message tools that provide a specific message on whether the fail safe was triggered or the new/refreshed data was passed through. The problem with the Message tool is that it is very easy for the message to get lost in the myriad log results so you don't automatically see it. The same is true for using the Browse tool to view a dynamic and more easy-to-read message/result, you still have to make the overt decision to click the Browse tool to review the result/message.
Admittingly, on their own, these "issues" seem minor. However, when running multiple workflows as part of a group or on a regular basis, some of which can be very large and complex, its easy for these "minor issues" to become major inconveniences to utilize as they are intended or they just get lost in the static of everything that happens when a workflow runs.
Having something similar to a Report Text tool that can render an image and formula-driven text/conditions (font and background color controls) directly and conspicuously on the canvas would be AWESOME and go a long way to providing immediate/easy-to-see information regarding the results of the workflow.
I ask/encourage the Alteryx team to explore providing this capability.
- Desktop Experience
- New Request

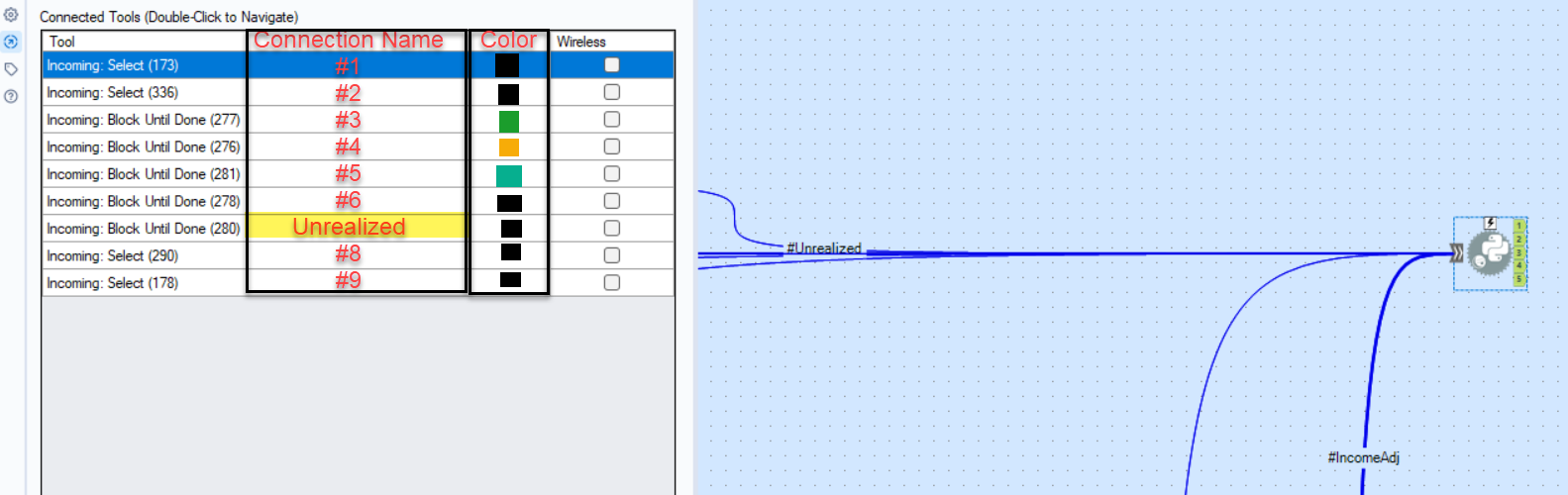
I only have 2023.2, hoping to get 24.2 soon, so I haven't been able to try the newest color feature, but my idea is additional columns in the Navigation panel of a tool to update multiple connection features in one place (names and color at the moment). I'm using Python, and I have a variety of data inputs I would like to be able to easily reference in my code. Currently default names are #1, #2, based on order of connection. Similarly, I know for tools that accept multiple inputs, like Union and Join Multiple, this could also be useful if needing to reorder based on the connection names. I'm also not sure how this ties in to the color feature as described in Connection Configuration, but this could also be a good place to change colors of multiple connections at once instead of clicking into each connection. This would also require this list to allow for multiple selection at the same time, as right now you can't hold shift and select multiple lines.
- Desktop Experience
- Enhancement
- UX
Currently, the Marketplace Add-ons interface when opened within Designer only contains the more significant, Alteryx made tools:

Which is a very useful feature, however if the tool I want to download is not on this limited list (or, I want a particular version), I still need to go through the Marketplace to download this.
It would be great if this functionality had all tools on the Marketplace included - potentially with the option to filter to Alteryx made tools only.
Cheers!
- Desktop Experience
- Enhancement
- Installation
In the 20 years of my career I have built many automations using many tools. Alteryx is one of the best but lacks a key function that many others have. The File Browse Tool and the Folder Browse tool should be able to be configured with default values.
There should be an option under the File Specification that says "Default Location". When the user clicks browse button in the Analytical Interface it should default to opening that location ( eg.. \\ShareDrive\Reports\Finance\ ). If this location in inaccessible by the user or Account running the job then either an error should be thrown and the flow stopped or a default location open as in 2024.2
Users have requested this as when you have a large network browsing to the file you need can be slow and cumbersome. Ideally we should be able set the default location in the Designer to the folder where the file they want "most likely" is. Saving the user time and effort. This same concept applies to Folder Browse.

The funny part about this is when you ask Alteryx Co-Pilot (or ChatGPT, or Microsoft Co-Pilot) how to do this. Even it figures this was a option that exists.

- Category Interface
- Desktop Experience
- Enhancement
Given that the current Iterative type Macro will hold each iteration output in memory, to merge it all at the end of the iterations, wouldn't it make sense to have a checkbox for "Large Data Sets" where each iteration's output is stored to a tmp file, to be merged after the iterations stop?
As it is, holding multiple iterations in memory may often be too much data for a PC, no matter how hefty. By off-loading the memory objects to a tmp file and only holding the currently working iteration in memory, speed and efficiency would be gained.
This is especially critical when using Iterative Macros to cycle through APIs (pagination) and while each individual data pull may be small enough, they quickly grow in memory as each data pull is added to the in-memory object.
- Category Macros
- Desktop Experience
- Enhancement
In CrossTab tool, it have Total Row and Total Column as option.
For Total Row, it work all the sum, count, and avg etc.
but for "Total Column", it only sum (even i not select the sum)
To solved this I suggest to add Total Column for Count, Avg and etc.
version 2024.2


{kind=link}
{kind=link}
- Category Transform
- Desktop Experience
- Enhancement
Is there a way to update workflow constants in analytic apps using an interface tool?
- Category Interface
- Desktop Experience
- Enhancement