Alteryx Designer Desktop Ideas
Share your Designer Desktop product ideas - we're listening!Submitting an Idea?
Be sure to review our Idea Submission Guidelines for more information!
Submission Guidelines- Community
- :
- Community
- :
- Participate
- :
- Ideas
- :
- Designer Desktop: Top Ideas
Featured Ideas
Hello,
After used the new "Image Recognition Tool" a few days, I think you could improve it :
> by adding the dimensional constraints in front of each of the pre-trained models,
> by adding a true tool to divide the training data correctly (in order to have an equivalent number of images for each of the labels)
> at least, allow the tool to use black & white images (I wanted to test it on the MNIST, but the tool tells me that it necessarily needs RGB images) ?
Question : do you in the future allow the user to choose between CPU or GPU usage ?
In any case, thank you again for this new tool, it is certainly perfectible, but very simple to use, and I sincerely think that it will allow a greater number of people to understand the many use cases made possible thanks to image recognition.
Thank you again
Kévin VANCAPPEL (France ;-))
Thank you again.
Kévin VANCAPPEL
Our company deals a lot in .dif, .kat, and .px7 files for importing into our softwares. Would it be possible to add these additional output types since it would save the additional step of re-saving the Excel file as a .dif.
I'm curently creating an app using interface tools to control multiple worklflows. It would be nice if I didnt have to physically drag the interface tool to the recceiving node. For example, right now I can click on the Left node of a join tool and it gives me the option to make connections to that tool or out of that tool wireless. It would be nice if I could right click and have an option to select from a list of interface tool incoming connections.
Need to allow Aliases to work with the Google Sheets Input / Output tools, so that I can input API keys in one place to service multiple tools. I know I can do this via Macros, but I also know it's best practice to avoid nesting macros.
I have a large dataset (~200k) of routers with the utilisation figures per month over 36 months. What I have been doing till now is using the TS Model Factory to config and TS Forecast Factory to generate the forecast for the next 6 months grouping by router. Great! Except the values returned per device are exactly the same for the next 6 months. Obviously by not using the ETS / ARIMA macros I lose the ability to configure in more detail.
What I would like is be able to set the parameters of the ETS/ARIMA model in advance then run the batch macro for the number of routers and return a 6 month forecast that takes into account all the parameters.
Happy to supply data if required!
Thanks in advance
Mark
It's been a while since I was last on these forums, and I can't find the suggestions subforum, only one massive 'Designer' forum. Hopefully I'm posting this in the correct place.
Anyway, the font colour on my Basic filter dialog dropdowns is for some reason bizarrely light and difficult to read. How do I fix this? It used to be a black font, so I'm trying to figure out what I've done wrong. It needs to be darker. Thanks

We are enjoying the new functionality of pointing to a .zip file in the input data tool and reading in .csv files without having to manually unzip the file. We process a lot of SQlite files so having that as an option would be great. We also have several clients that supply .zip flat fixed lenght files with 100+ fields that we have mapped and having the functionality to use the Flat File Layout tool and Import the mapping file that has already been completed would be very helpful also. The current workaround is to read in as a csv with \0 as the delimiter but we then have to substring to parse each field and rename.
Hello Alteryx Community,
I've recently started using Alteryx and one option on the Output Data tool I think that could be useful to others and myself is the option to choose: Append to an extract file (Create if does not exist). This is similar to the already existing Overwrite existing extract file (Create if does not exist) option.
My case for this is... I'm in the situation where I'm setting up a flow that I know from the offset is going to be a repeatable flow that is designed to build up data over time and so I will be running the Output Data tools in append mode. Except for the first run, I can't append to an extract that doesn't exist! The flow in question has over around 20 Output Data tools and while it wouldn't take terribly long to reconfigure after the initial run, it is a bit tedious. I think there is scope for my proposed option for being implemented either as a standalone option or to replace the current append option.
Example of my current flow:

I find that when I'm using Alteryx, I'm constantly renaming the tool connectors. Here's my logic, most of the time:
I have something like a Join and 3 browses.
- I name the L join something like "L: on product/location join"
- I then copy that descriptor, and past it in the Annotation field
- I then copy that descriptor, select the wired connector, and paste that in the connection configuration
MY VISION:
Have a setting where I could select the following options:
- Automatically annotate based on tool rename
- Automatically rename incoming connector based on tool rename

If I rename a tool, and "Automatically annotate based on tool rename" is enacted, it will insert that renaming at the top of the annotation field. If there is already data in that field, it will be shifted down. If I rename a tool and "Automatically rename incoming connector..." is on, then the connection coming into it gets [name string]+' connection' put into its name field. I included a picture of the end game of my request.
Thanks for your ear!
It would be nice if when Alteryx crashes there is an autosave capability that when you re-open Alteryx it shows you the list of workflows that were autosaved and give you the immediate option to select which ones you want to save. SImilar to what Excel does.
I know about the current autosave feature, but I would still like to have it pop up or the option to have it pop up for me to select which to keep and which to discard.
The new insight tool offers some great charting abilities but it does not integrate with other reporting tools. The tool doesn't support pictures,tables or any way to pull text from the data in the workflow in. This really prevents it from being a solution to any of the my reporting needs.
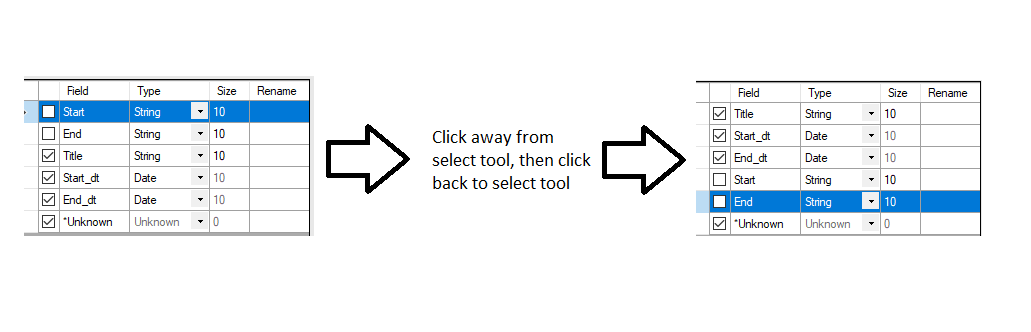
When using the 'Select' tool, often many columns are deselected, making it difficult to locate the remaining selected columns. It would save time to move deselected columns to the bottom of the ‘Select’ tool configuration after leaving the tool. Both selected and de-selected columns should retain their incoming field order within the group.

{kind=link}
After developing complicated workflows (using over 200 tools and over 30 inputs and outputs) in my DEV or QA environment, I need to switch over to Production to deploy it, but it's incredibly annoying to have to change 30 data inputs individually from QA to Prod, DEV to QA, etc. If I need to go back to QA to change something and re-test, I have to do it all again. etc.etc.
I need a way to be able to change mass amounts of data sources at once or at least make the process a lot more streamlined to make it bearable. Otherwise it is incredibly difficult to work within multiple environments.
Curl currently doesn't have Secure protocols supported. Please find below screen-shot. We are currently using Alteryx 11.7.6

Can Alteryx take this as feature request and add the secure libraries to existing cURL tool so that it can support the secure SFTP protocol.
In the Alteryx SharePoint list tool, Alteryx fails to authenticate using to connect to SharePoint list that is protected by ADFS. There Sharepoint sites outside of our company's firewall that use ADFS for authentication. We would like to connect to those sites via the Sharepoint List tool.
Was thinking with my peers at work that it might be good to have join module expanded both for desktop and in-database joins.
As for desktop join: left and right join shows only these records that are exclusive to that side of operation. Would it be possible to have also addition of data that is in common?
As for in-db join: db join acts like classic join (left with matching, right with matching data). Would it be possible to get as well only-left, only-right join module?
{kind=link}
{kind=link}
Please have the Calgary Tools put the file names in the annotation automatically like all other input/output tools.
NOTE: There are other Idea posts for improvement of the Browse Profiling functionality, but I did not find anything specific to this and feel these ideas should be segregated anyway.
I just discovered that the plot in the Browse tool profiling section when plotting numeric values has differing behavior.
According to the documentation, "Once more than 10,000 unique values are profiled, binning is applied to increase performance and to represent data in a a more meaningful way."
What this means is that for numeric data, a scatterplot is shown if there are less than 10,000 unique values, and a frequency plot (bar chart) is shown if more than 10,000 unique values. There is then an indication that "Only the top 20 unique values are shown".
I can see where with some situations (e.g., an integer value), a frequency plot that shows the more predominant values would be a good thing to see.
However I would argue that a frequency plot of numeric data that is basically a “double” data type can be pretty meaningless…since out of 10,001 values, you might have 10,001 UNIQUE values…so you end up with a frequency plot that is not of much value (where as the scatterplot would still allow a user to see the dispersion of the ENTIRE data set).
I’ve attached an example to easily show this.
It would be great if the user could choose the plot he wants for a specific set of data…similar to the choices that occur when a date field is present in the data.
I came across the Find Replace Tool when I needed to find values from a column in one table in a column in another table. My first instance to solve the problem was to write a batch macro with a contains function in a formula followed by a not null filter (see attachment). This worked perfectly besides the fact that it was slow. Then I got excited when I discovered the Find Replace Tool accomplishes the same thing WAY faster, but I was wrong.
What I would love is the equivalent of an SQL query like this:
SELECT
A.1
B.1
FROM A
INNER JOIN
B
ON A.1 LIKE "%" || B.2 || "%"
which is a legal query in SQLite and is equal to the output of the attached macro. This is what I wish the Find Replace tool could do (Or a different tool), but it only finds one instance per "Find Within Field" value. The tools decision making doesn't line up with the decision-making that I need, for example it doesn't return the longest values found, instead the one with the first key to appear in the field. One way I've found to configure it better is to string a number of these together, that will give me a better result but still won't find every instance and uses 90 or so tools when I feel I should only need 1-3 to accomplish the same thing.
Instead of an Inner Join, the Find Replace is more like of Left Outer Join followed by a Unique() on A.1. Is there a way to accomplish this out-of-database in Alteryx?
As I'm sure many users do, we schedule our workflows to run during non-business hours -- overnight and over the weekend. Our primary datasource (input tool) is a remotely hosted database that our organization doesn't maintain (and hence cannot monitor the status of). If the database were to timeout or if our query were to overload it's resources, our scheduled Alteryx workflow would (attempt to) continue to run for an unknown amout of time. We would like the ability to cancel a scheduled workflow if it has been running for a certain amount of time in order to prevent this.
I was trying to check the correctness of multiple URLs with the help of download tool connected to parsing tool that way I check the download status and filter the records to good and bad based on the HTTP status codes. To my suprise it allows 2 errors at the maximum ans stops checking next records which is not at all useful for me. I wondered if someone can help me. As @JordanB say it is the default behavior of the tool and can't be handled as of now. Hope you guys have the error handling feature in your next release.
- New Idea 274
- Accepting Votes 1,815
- Comments Requested 23
- Under Review 173
- Accepted 58
- Ongoing 6
- Coming Soon 19
- Implemented 483
- Not Planned 115
- Revisit 61
- Partner Dependent 4
- Inactive 672
-
Admin Settings
20 -
AMP Engine
27 -
API
11 -
API SDK
218 -
Category Address
13 -
Category Apps
113 -
Category Behavior Analysis
5 -
Category Calgary
21 -
Category Connectors
247 -
Category Data Investigation
77 -
Category Demographic Analysis
2 -
Category Developer
208 -
Category Documentation
80 -
Category In Database
214 -
Category Input Output
640 -
Category Interface
239 -
Category Join
103 -
Category Machine Learning
3 -
Category Macros
153 -
Category Parse
76 -
Category Predictive
77 -
Category Preparation
394 -
Category Prescriptive
1 -
Category Reporting
198 -
Category Spatial
81 -
Category Text Mining
23 -
Category Time Series
22 -
Category Transform
89 -
Configuration
1 -
Content
1 -
Data Connectors
963 -
Data Products
2 -
Desktop Experience
1,537 -
Documentation
64 -
Engine
126 -
Enhancement
330 -
Feature Request
213 -
General
307 -
General Suggestion
6 -
Insights Dataset
2 -
Installation
24 -
Licenses and Activation
15 -
Licensing
12 -
Localization
8 -
Location Intelligence
80 -
Machine Learning
13 -
My Alteryx
1 -
New Request
194 -
New Tool
32 -
Permissions
1 -
Runtime
28 -
Scheduler
23 -
SDK
10 -
Setup & Configuration
58 -
Tool Improvement
210 -
User Experience Design
165 -
User Settings
80 -
UX
223 -
XML
7
- « Previous
- Next »
-
 NicoleJ
on:
Disable mouse wheel interactions for unexpanded dr...
NicoleJ
on:
Disable mouse wheel interactions for unexpanded dr...
- TUSHAR050392 on: Read an Open Excel file through Input/Dynamic Inpu...
- NeoInfiniTech on: Extended Concatenate Functionality for Cross Tab T...
- AudreyMcPfe on: Overhaul Management of Server Connections
-
AlteryxIdeasTea
m on: Expression Editors: Quality of life update - StarTrader on: Allow for the ability to turn off annotations on a...
- simonaubert_bd on: Download tool : load a request from postman/bruno ...
- rpeswar98 on: Alternative approach to Chained Apps : Ability to ...
-
 caltang
on:
Identify Indent Level
caltang
on:
Identify Indent Level
- simonaubert_bd on: OpenAI connector : ability to choose a non-default...