Alteryx Designer Desktop Ideas
Share your Designer Desktop product ideas - we're listening!Submitting an Idea?
Be sure to review our Idea Submission Guidelines for more information!
Submission Guidelines- Community
- :
- Community
- :
- Participate
- :
- Ideas
- :
- Designer Desktop
Featured Ideas
Hello,
After used the new "Image Recognition Tool" a few days, I think you could improve it :
> by adding the dimensional constraints in front of each of the pre-trained models,
> by adding a true tool to divide the training data correctly (in order to have an equivalent number of images for each of the labels)
> at least, allow the tool to use black & white images (I wanted to test it on the MNIST, but the tool tells me that it necessarily needs RGB images) ?
Question : do you in the future allow the user to choose between CPU or GPU usage ?
In any case, thank you again for this new tool, it is certainly perfectible, but very simple to use, and I sincerely think that it will allow a greater number of people to understand the many use cases made possible thanks to image recognition.
Thank you again
Kévin VANCAPPEL (France ;-))
Thank you again.
Kévin VANCAPPEL
use case : much of our users copy paste a formatted query to the Alteryx tools such as Connect in Db or Input Data (especially to reduce the data).
However, some of the formatting such a Carrier Return does not work
select * from `re7_kerberos_za_e_*******_ee01pub_edd`.`v_*******_flux_20170511`


-
Category In Database
-
Category Input Output
-
Category Preparation
-
Data Connectors
The "Browse HDFS" for the Spark Direct connection does not allow to specify a File Format at "ORC". Could you please add these feature?

-
Category In Database
-
Category Input Output
-
Data Connectors
So it takes while to download data from in-db (say oracle table) and load it to another...
Why not build an additional in-db tool to migrate data without downloading to local...
Oracle has this capability and here is the Syntax;
COPY Command Syntax
COPY {FROM database | TO database | FROM database TO database} {APPEND|CREATE|INSERT|REPLACE} destination_table [(column, column, column, ...)]
USING query
where database has the following syntax:
username[/password]@connect_identifier
Copies data from a query to a table in a local or remote database. COPY supports the following datatypes:
CHAR DATE LONG NUMBER VARCHAR2
Example;
COPY FROM HR/your_password@BOSTONDB - TO TODD/your_password@CHICAGODB - CREATE NEWDEPT (DEPARTMENT_ID, DEPARTMENT_NAME, CITY) - USING SELECT * FROM EMP_DETAILS_VIEW
-
Category In Database
-
Data Connectors
Hi there,
When you connect to a SQL server in 11, using the native SQL connection (thank you for adding this, by the way - very very helpful) - the database list is unsorted. This makes it difficult to find the right database on servers containing dozens (or hundreds) of discrete databases.
Could you sort this list alphabetically?

-
Category In Database
-
Data Connectors
There is a known error when using the Write Data In-DB Tool. When writing to a table in MS SQL database that has a "identity" column you get the following error: Error: Write Data In-DB (X): Error running PreSQL on "NoTable": [DB Connection]An explicit value for the identity column in table [table_name] can only be specified when a column list is used and IDENTITY_INSERT is ON.
Essential this error happens when the table you are trying to write to has a column with the following configuration or similar: IDENTITY(1, 1) NOT NULL
I am suggesting that the Write Data In-DB Tool should be configurable insert only to specified columns as identified by the user. Similar to the functionality of this SQL statement:
INSERT INTO [table_name]
(column1, column2, column 3, etc...)
VALUES (new_value1, new_value2, new_value3, etc...)
This would 1) solve the above issue (for which there is no viable workaround), and 2) allow users more flexibility in how they write their data.
The following community posts are related:
-
Category In Database
-
Data Connectors
We're not too happy with the Gallery Data Connections not being available for the IN-DB data input tool but that will hopefully be a feature to be looked at in future product improvements; Let us know if there are reasons not having this feature already.
Thank you.
-
Category In Database
-
Data Connectors
Hi Team,
Can we use IN DB to connect to Sybase IQ to optimize data extraction and transformation.
-
Category In Database
-
Data Connectors
Alteryx creates a Livy Session when connecting to Spark Direct

I just want to identify easily the session.
-
Category In Database
-
Data Connectors
We've been researching snowflake and are eager to try this new cloud database tool but are holding off till Alteryx supports in-database tools for that environment. I know it's a fairly new service and there probably aren't tons of users, but it seems like a perfect fit since it's fully SQL complaint and is a truely native clouad, SAAS tool. It's built from scratch for AWS, and claims to be faster and cheaper.
Snowflake for data storage, Alteryx for loading and processing, Tableau for visualization - the perfect trio, no?
Has anyone had experience/feedback with snowflake? I know it supports ODBC so we could do basic connections with Alteryx, but the real key would obviously be enabling in-database functionality so we could take advantage of the computation power of the snowflake.
Anyway, I just wanted to mention the topic and find out if it's in the plans or not.
Thanks,
Daniel
-
Category Connectors
-
Category In Database
-
Data Connectors
I would like the ability to take custom geographies and write them to a table in Exasol. We visualize our data with Tableau and rely on live connections to Exasol tables rather than Tableau extracts. One shortcoming with spatial is that we have to output our custom geographies as a .shp file then make a Tableau Extract. This would save us a few steps in sharing this data with our users.
Thanks!
-
Category In Database
-
Category Spatial
-
Data Connectors
-
Location Intelligence
Hi Alteryx,
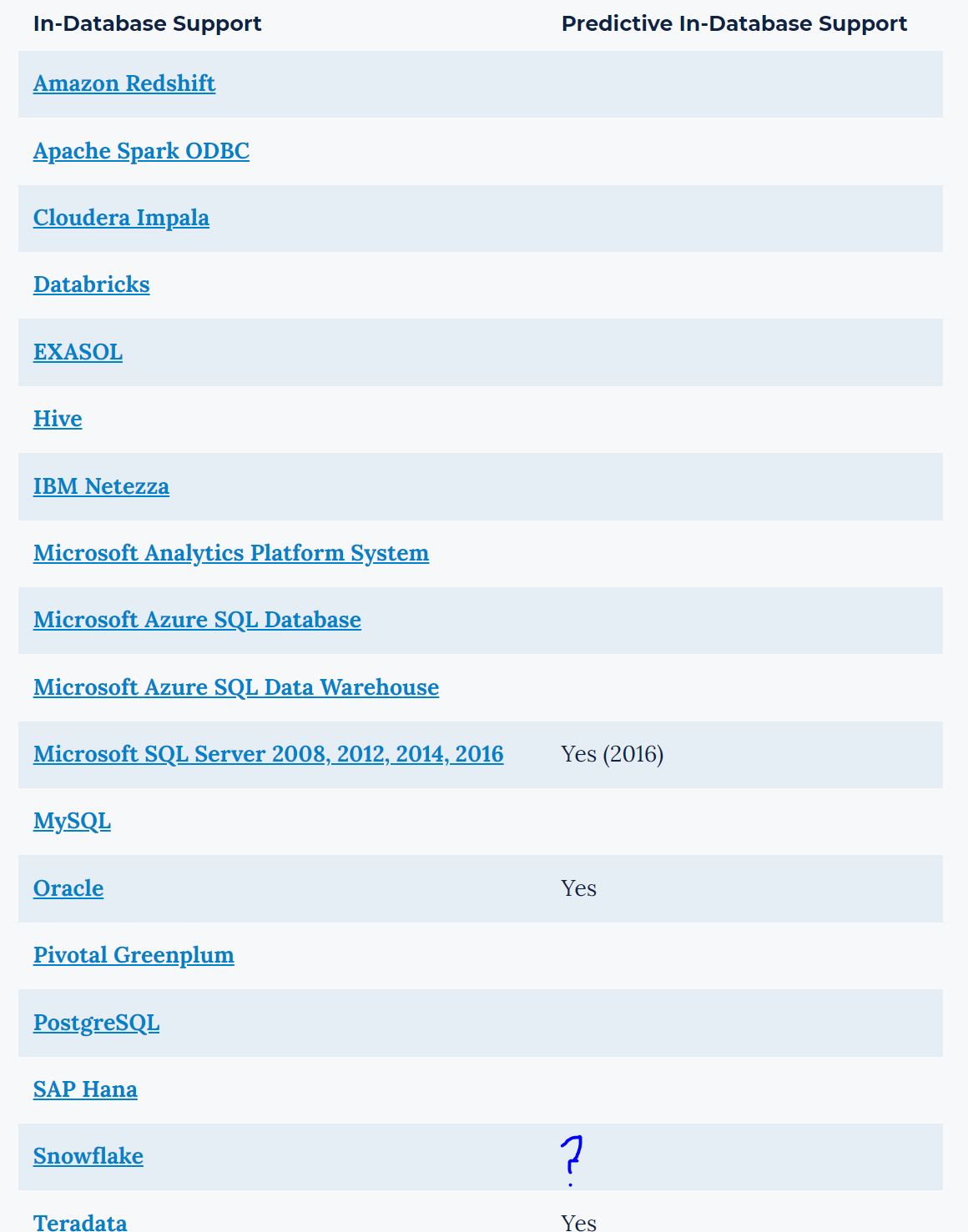
Can we get the R tools/models to work in database for SNOWFLAKE.
In-Database Overview | Alteryx Help
I understand that Snowflake currently doesn't support R through their UDFs yet; therefore, you might be waiting for them to add it.
I hear Python is coming soon, which is good & Java already available..
However, what about the ‘DPLYR’ package? https://db.rstudio.com/r-packages/dplyr/
My understanding is that this can translate the R code into SQL, so it can run in-DB?
Could this R code package be appended to the Alteryx R models? (maybe this isn’t possible, but wanted ask).
Many Thanks,
Chris
-
Category In Database
-
Category Predictive
-
Data Connectors
-
Desktop Experience
Spark ODBC is really faster than Hive, at least for GUI.
However, two things are missing :
1/ Append existing for the write date (exists his way on Hive)
2/ability to put "overwrite" even if the table does not exist (it works this way on Hive)

These two drawbacks limit severly th
-
Category In Database
-
Data Connectors
When dealing with very large tables (100M rows plus), it's not always practical to bring the entire table back to the designer to profile and understand the data.
It would be very useful if the power of the field summary tool (frequency analysis; evaluating % nulls; min & max values; length of strings; evaluating if the type is appropriate or could be compressed; whether there is whitespace before or after) could be brought to large DB tables without having to bring the whole table back to the client.
Given that each of these profiling tasks can be done as a discrete SQL query; I would think that this would be MASSIVELY faster than doing this client-side; but it would be a bit of a pain to write this tool.
If there is interest in this - I'm more than happy to work with the Alteryx team to look at putting together an initial mockup.
Cheers
Sean
-
API SDK
-
Category Developer
-
Category In Database
-
Data Connectors
Hi all,
In the formula tool and the SQL editors, it would be great to have a simple bracket matcher (like in some of the good SQL tools or software IDEs) where if you higlight a particular open bracket, it highlights the accompanying close bracket for you. That way, I don't have to take my shoes and socks off to count all the brackets open and brackets closed if I've dropped one 🙂
It would also be great if we could have a right-click capability to format formulae nicely. Aqua Data Studio does a tremendous job of this today, and I often bring my query out of Atlteryx, into Aqua to format, and then pop it back.
Change:
if X then if a then b else c endif else Z
To:
if X
Then
if A
then B
Else C
else Z
Endif
or Change from
Select A,B from table c inner join d on c.ID = D.ID where C.A>10
to
Select
A
,B
From
Table C
Inner Join D
on C.ID = D.ID
Where
C.A>10
Finally - intellitext in all formulae and SQL editing tools - could we allow the user to bring up intellitext (hints about parameters, with click-through to guidance) like it works in Visual Studio?
Thank you
Sean
-
Category In Database
-
Category Preparation
-
Data Connectors
-
Desktop Experience
Hi,
we use a lot the in-db tools to join our database and filter before extracting (seems logic), but to do it dynamically we have to use the dynamic input in db, which allows to input a kind of parameter for the dates, calculated locally and easily or even based on a parameter table in excel or whatever, it would be great to be able to dynamically plug a not in db tools to be able to have some parameters for filters or for the connect in-db. The thing is when yu use dynamic input in-db, you loose the code-free part and it can be harder to maintain for non sql users who are just used to do simple queries.
You could say that an analytic application could do the trick or even developp a macro to do so, but it would be complicated to do so with hundreds of tables.
Hope it will be interesting for others!
-
Category In Database
-
Data Connectors
We really need a block until done to process multiple calculations inDB without causing errors. I have heard that there is a Control Container potentially on the road map. That needs to happen ASAP!!!!
-
Category In Database
-
Data Connectors
A question has been coming up from several users at my workplace about allowing a column description to display in the Visual Query Builder instead of or along with the column name.
The column names in our database are based on an older naming convention, and sometimes the names aren't that easy to understand. We do see that (if a column does have a column description in metadata) it shows when hovering over the particular column; however, the consensus is that we'd like to reverse this and have the column description displayed with the column name shown on hover.
It would be a huge increase to efficiency and workflow development if this could be implemented.
-
Category Connectors
-
Category Data Investigation
-
Category In Database
-
Category Input Output
Please add an append fields component to the IN-Database components. And also allow the adding of fields to the in-db formula component. It seems to be really difficult to add a field into the data stream when using IN-DB components. Would be good to resolve this and try to make the IN-DB components consistent with the standard ones.
-
Category In Database
-
Data Connectors
As of today, we cannot choose the field separator when we read a csv file. In France, the common separator for csv is the semi-colon (;)
It leads to this kind of thing in a filter :

{kind=link}
-
Category In Database
-
Data Connectors
It is very difficult moving from Alteryx functions to SQL In-Database as a business user, I need to learn a whole new language.
In the short term Alteryx should provide a simple function reference, as similar as possible to the Formula tool, for building formula in the in-database tools.
Longer term I'd like there to be a parser from Alteryx Formulae to SQL so I can just write in my favourite Alteryx formula (or a subset thereof) and Alteryx handles the conversion to SQL.
-
Category In Database
-
Data Connectors
- New Idea 376
- Accepting Votes 1,784
- Comments Requested 21
- Under Review 178
- Accepted 47
- Ongoing 7
- Coming Soon 13
- Implemented 550
- Not Planned 107
- Revisit 56
- Partner Dependent 3
- Inactive 674
-
Admin Settings
22 -
AMP Engine
27 -
API
11 -
API SDK
228 -
Category Address
13 -
Category Apps
114 -
Category Behavior Analysis
5 -
Category Calgary
21 -
Category Connectors
252 -
Category Data Investigation
79 -
Category Demographic Analysis
3 -
Category Developer
217 -
Category Documentation
82 -
Category In Database
215 -
Category Input Output
655 -
Category Interface
246 -
Category Join
108 -
Category Machine Learning
3 -
Category Macros
155 -
Category Parse
78 -
Category Predictive
79 -
Category Preparation
402 -
Category Prescriptive
2 -
Category Reporting
204 -
Category Spatial
83 -
Category Text Mining
23 -
Category Time Series
24 -
Category Transform
92 -
Configuration
1 -
Content
2 -
Data Connectors
982 -
Data Products
4 -
Desktop Experience
1,604 -
Documentation
64 -
Engine
134 -
Enhancement
406 -
Event
1 -
Feature Request
218 -
General
307 -
General Suggestion
8 -
Insights Dataset
2 -
Installation
26 -
Licenses and Activation
15 -
Licensing
15 -
Localization
8 -
Location Intelligence
82 -
Machine Learning
13 -
My Alteryx
1 -
New Request
226 -
New Tool
32 -
Permissions
1 -
Runtime
28 -
Scheduler
26 -
SDK
10 -
Setup & Configuration
58 -
Tool Improvement
210 -
User Experience Design
165 -
User Settings
85 -
UX
227 -
XML
7
- « Previous
- Next »
- abacon on: DateTimeNow and Data Cleansing tools to be conside...
-
 TonyaS
on:
Alteryx Needs to Test Shared Server Inputs/Timeout...
TonyaS
on:
Alteryx Needs to Test Shared Server Inputs/Timeout...
-
 TheOC
on:
Date time now input (date/date time output field t...
TheOC
on:
Date time now input (date/date time output field t...
- EKasminsky on: Limit Number of Columns for Excel Inputs
- Linas on: Search feature on join tool
-
MikeA
on:
Smarter & Less Intrusive Update Notifications — Re...
- GMG0241 on: Select Tool - Bulk change type to forced
-
Carlithian
on:
Allow a default location when using the File and F...
- jmgross72 on: Interface Tool to Update Workflow Constants
-
pilsworth-bulie
n-com on: Select/Unselect all for Manage workflow assets
| User | Likes Count |
|---|---|
| 6 | |
| 5 | |
| 3 | |
| 2 | |
| 2 |