Alteryx Designer Desktop Ideas
Share your Designer Desktop product ideas - we're listening!Submitting an Idea?
Be sure to review our Idea Submission Guidelines for more information!
Submission Guidelines- Community
- :
- Community
- :
- Participate
- :
- Ideas
- :
- Designer Desktop: Hot Ideas
Featured Ideas
Hello,
After used the new "Image Recognition Tool" a few days, I think you could improve it :
> by adding the dimensional constraints in front of each of the pre-trained models,
> by adding a true tool to divide the training data correctly (in order to have an equivalent number of images for each of the labels)
> at least, allow the tool to use black & white images (I wanted to test it on the MNIST, but the tool tells me that it necessarily needs RGB images) ?
Question : do you in the future allow the user to choose between CPU or GPU usage ?
In any case, thank you again for this new tool, it is certainly perfectible, but very simple to use, and I sincerely think that it will allow a greater number of people to understand the many use cases made possible thanks to image recognition.
Thank you again
Kévin VANCAPPEL (France ;-))
Thank you again.
Kévin VANCAPPEL
It would be nice to have a visual cue for a detour tool's configuration. This is especially the case when testing with several detour tools in a workflow - see the cleanse.yxmc screenshot below. I added an annotation to one of the detour tools as a possible solution.
Any of these options that would save the additional click would be appreciated.
- Default annotation shows "Detour left" or "Detour right"
- Detour outgoing wire highlighted (mentioned in Detour dashing)
- Detour direction outgoing anchor that is NOT used is grayed out
- Detour direction outgoing wire that in NOT used is grayed out
- Detour tool has a left/right toggle
- Detour tool changes color when set to detour right
Personally, I prefer that the outgoing anchor and outgoing wire not in use be grayed out. But even the default annotation stating the direction would be helpful.
Does anyone else have a preference or other ideas on the visual cues?

-
API SDK
-
Category Developer
My company does installs through a machine with admin rights, but the end user does not actually have admin rights to the laptop. Therefore, when attempting to add modules into the Developer tool for python - pip install fails. The failure is due to the install being in program files where a non-admin is unable to write, the normal workaround is also not possible since the version used is admin and not non-admi designer.
Can the tool be more flexible from the get go. As the only way out of this is to go through articles regarding SDK and creating custom requirements txt files. My goal was just to be able to use Python with Alteryx and add on modules as I need. Very cool updates in 3.5 I'm using but thought this conundrum might happen to others in same situation. Admin install with non-admin rights. Thanks.
-
API SDK
-
Category Developer
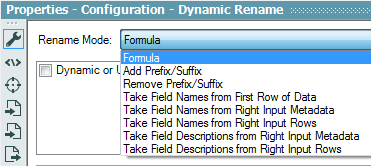
I would add:
Take Field Metadata from Right Input Metadata
Take Field Metadata from Right Input Rows
These would allow mass changes in data type, size and scale based on either an existing data table's metadata or an external metadata table.
-
API SDK
-
Category Developer
I recently cam across a limitation in Alteryx, where we can't download non-CSV files using Amazon S3 download tool. There is currently support only for CSV, and couple of other formats but we are using JSON files (.jl) extensively and not having the tool download the files into the workflow is disapointing as now i have to build a custom code outside Alteryx to do that before I can start my workflow.
Can this be please given prompt attention and prioritized accordingly.
-
API SDK
-
Category Developer
This wasn't pretty (actually, it was challenging and pretty when I was done with it)!
My client receives files that include a static and dated name portion (e.g. Data for 2018 July.xlsx) within the file there are multiple sheets. One sheet contains a keyword (e.g. Reported Data) but the sheet name also includes a variable component (e.g. July Reported Data). I needed to first read a directory to find the most recent file, then when I wanted to supply the dynamic input with the sheet name I wasn't able to use a pattern.
The solution was to use a dynamic input tool just to read sheet names and append the filtered name to the original Full Path.
[FullPath] + "|||<List of Sheet Names>"
This could then feed a dynamic input.

Given the desire to automate the read of newly received "excel" data and the fluidity of the naming of both files and sheets, more flexibility in the dynamic input is requested.
Cheers,
Mark
-
API SDK
-
Category Developer
I need support for outbound data streams to be gzip compressed. Ideally, this would be done by a new tool that can be inserted into a workflow (maybe similar to the Base 64 Encoding tool). Just including it in the Output Tool will not address my needs as I will be sending gzip payloads to a cloud API. There are two main reasons why this is necessary (and without it, quite possibly a roadblock for our enterprise's use of Alteryx):
- Some APIs enforce gzip encoding, therefore Alteryx cannot currently be used to interact with such APIs
- When transmitting large volumes of data across the Internet, gzip compression will significantly decrease transmission times
-
API SDK
-
Category Developer
Per my initial community posting, it seems that in environments where the firewall blocks pip the YXI installation process takes longer than it needs. My experience was 9:15 minutes for a 'simple' custom tool (one dependency wheel included in the YXI).
Given the helpful explanation of the YXI installation process, it seems the --upgrade pip and setuptools is causing the delay. Disconnecting from the internet entirely causes the custom YXI to install in 1:29 minutes.
My 'Idea' is to provide a configuration option to install the YXI files 'offline'. That is, to skip the pip install --upgrade steps, and perhaps specify the --find-links and --no-index options with the pip install -r requirements.txt command. The --no-index option would assume that the developer has included the dependency wheel files in the YXI package. If possible, a second config option to add the path to the dependencies for the --find-links option would help companies that have a central location for storing their dependencies.
-
API SDK
-
Category Developer
It would be nice to add a date in there, maybe %Date% or %DateTime% or something like that which would display the computer system time.
-
API SDK
-
Category Developer
Providing access to the Oracle Cloud for OTM would allow users to connect to the API's to deliver data sets from the Cloud and use it for workflow and other data management activities.
-
API SDK
-
New Request
It is important to be able to test for heteroscedasticity, so a tool for this test would be much appreciated.
In addition, I strongly believe the ability to calculate robust standard errors should be included as an option in existing regression tools, where applicable. This is a standard feature in most statistical analysis software packages.
Many thanks!
Can we have some support monitoring information added to the summary of each tool during/after a workflows run so we can determine how much memory is being used per component and per workflow run. Not just what is the default minimum. This will help to identify where in our workflow we can improve and/or help us by adjusting the default memory usage for sort/join tools on a workflow basis.
-
API SDK
-
Category Developer
File has a different Schema than the first file in the set- This is error received in Dynamic Input Tool, when there is change in data type any column in the file. My File has a column Which comes in " V String" Data type but suddenly it comes in " Double" then this error will come.
Tool should ignore this error and consider incoming data in a data type defined while in configuration, so request to provide feature to configure data type in Dynamic Input Tool.
-
API SDK
-
Category Developer
-
Enhancement
It would be nice to improve upon the 'Block Until Done' tool.
Additional Features I could see for this tool:
1: Allow Any tool (even output) to be linked as an incoming connection to a 'Block Until Done' tool.
2: Allow Multiple Tools to be linked to a 'Block Until Done' tool. (similar to the 'Union' tool)
The functionality I see for this is to enable Alteryx set the Order of Operation for workflows and Allowing people to automate processes in the same way that people used to do them. I understand there's a work around using Crew Macros (Runner/Conditional Runner) that can essentially accomplish this; howerver (and I may be wrong). But it feels like a work around, instead of the tool working the way one would expect; and I'm loosing the ability to track/log/troubleshoot my workflow as it progresses (or if it has an issue)
Happy to hear if something like that exists. Just looking for ways to ensure order of operation is followed for a particular workflow I am managing.
Thanks,
Randy
-
API SDK
-
Category Developer
The C API for e1 is included in the Designer Desktop installation. The new AMP engine must have a C API as well, but it has not been released publicly.
Let tool and SDK makers create custom tools that plug into the AMP engine by releasing the specifications of the AMP C API.
-
API SDK
-
Enhancement
-
API SDK
-
Category Developer
Currently the R predictive tools are single thread, which means to utilise multi-threading we need to download separately a third party R package such as Microsoft R Client.
Given this is a better option, should this not be used as the default package upon installation?
Hi team,
There are some things that we would like to do with the download tool that currently are not possible:
1. use client side certificates to sign requests. This is a requirement for us in a project where we are interacting with the API of our customer's financial system. They provide us with a certificate and it is used to sign our requests, along with other authentication.Currently we have to use the external command tool to execute a powershell script using invoke-restmethod to do this interaction. I would much prefer to not have more tools in the chain.
Client certificates are described in the TLS 1.0 specification: https://tools.ietf.org/html/rfc2246 (page 43), and I believe them to be supported by cURL.
2. Multipart form-data. We have a number of workflows where we need to send multipart form data as part of a POST request. As this is not supported by the Download Tool, we have again used the external command tool to execute invoke-restmethod or invoke-webrequest in powershell. I don't know if modification of the Download Tool would be the best thing here, vs having either a dedicated tool for multipart form data, or having an HTTP POST specific tool that was able to handle multipart form data. What I envisage is something like the formula tool, with the ability to add an arbitrary number of cells, where we could use formula to either directly output a value from a column, synthesise a new value, or directly enter a static value). The tool would then compose this with boundaries between the parts, and calculate the content-size to add to the http request.
-
API SDK
-
Category Developer
Dynamic Input is a fantastic tool when it works. Today I tried to use it to bring in 200 Excel files. The files were all of the same report and they all have the same fields. Still, I got back many errors saying that certain files have "a different schema than the 1st file." I got this error because in some of my files, a whole column was filled with null data. So instead of seeing these columns as V_Strings, Alteryx interpreted these blank columns as having a Double datatype.
It would be nice if Alteryx could check that this is the case and simply cast the empty column as a V_String to match the previous files. Maybe make it an option and just have Alteryx give a warning if it has to do this..
An even simpler option would be to add the ability to bring in all columns as strings.
Instead, the current solution (without relying on outside macros) is to tick the checkbox in the Dynamic Input tool that says "First Row Contains Data." This then puts all of the field titles into the data 200 times. This makes it work because all of the columns are now interpreted as strings. Then a Dynamic Rename is used to bring the first row up to rename the columns. A Filter is used to remove the other 199 rows that just contained copies of the field names. Then it's time to clean up all of the fields' datatypes. (And this workaround assumes that all of the field names contain at least one non-numeric character. Otherwise the field gets read as Double and you're back at square one.)
-
API SDK
-
Category Developer
-
Feature Request
-
General
As a security enhancement, the default passwords setting should be encrypt for user. Although this is critical for security my users have overlooked this even with training. They truly aren't culpable if they forgot. If it is the default then they must consciously change the it to an insecure setting.
From a security perspective the current default setting is backwards.
Grant Hansen
- New Idea 376
- Accepting Votes 1,784
- Comments Requested 21
- Under Review 178
- Accepted 47
- Ongoing 7
- Coming Soon 13
- Implemented 550
- Not Planned 107
- Revisit 56
- Partner Dependent 3
- Inactive 674
-
Admin Settings
22 -
AMP Engine
27 -
API
11 -
API SDK
228 -
Category Address
13 -
Category Apps
114 -
Category Behavior Analysis
5 -
Category Calgary
21 -
Category Connectors
252 -
Category Data Investigation
79 -
Category Demographic Analysis
3 -
Category Developer
217 -
Category Documentation
82 -
Category In Database
215 -
Category Input Output
655 -
Category Interface
246 -
Category Join
108 -
Category Machine Learning
3 -
Category Macros
155 -
Category Parse
78 -
Category Predictive
79 -
Category Preparation
402 -
Category Prescriptive
2 -
Category Reporting
204 -
Category Spatial
83 -
Category Text Mining
23 -
Category Time Series
24 -
Category Transform
92 -
Configuration
1 -
Content
2 -
Data Connectors
982 -
Data Products
4 -
Desktop Experience
1,604 -
Documentation
64 -
Engine
134 -
Enhancement
406 -
Event
1 -
Feature Request
218 -
General
307 -
General Suggestion
8 -
Insights Dataset
2 -
Installation
26 -
Licenses and Activation
15 -
Licensing
15 -
Localization
8 -
Location Intelligence
82 -
Machine Learning
13 -
My Alteryx
1 -
New Request
226 -
New Tool
32 -
Permissions
1 -
Runtime
28 -
Scheduler
26 -
SDK
10 -
Setup & Configuration
58 -
Tool Improvement
210 -
User Experience Design
165 -
User Settings
85 -
UX
227 -
XML
7
- « Previous
- Next »
- abacon on: DateTimeNow and Data Cleansing tools to be conside...
-
 TonyaS
on:
Alteryx Needs to Test Shared Server Inputs/Timeout...
TonyaS
on:
Alteryx Needs to Test Shared Server Inputs/Timeout...
-
 TheOC
on:
Date time now input (date/date time output field t...
TheOC
on:
Date time now input (date/date time output field t...
- EKasminsky on: Limit Number of Columns for Excel Inputs
- Linas on: Search feature on join tool
-
MikeA
on:
Smarter & Less Intrusive Update Notifications — Re...
- GMG0241 on: Select Tool - Bulk change type to forced
-
Carlithian
on:
Allow a default location when using the File and F...
- jmgross72 on: Interface Tool to Update Workflow Constants
-
pilsworth-bulie
n-com on: Select/Unselect all for Manage workflow assets