Alteryx Designer Desktop Ideas
Share your Designer Desktop product ideas - we're listening!Submitting an Idea?
Be sure to review our Idea Submission Guidelines for more information!
Submission Guidelines- Community
- :
- Community
- :
- Participate
- :
- Ideas
- :
- Designer Desktop: Hot Ideas
Featured Ideas
Hello,
After used the new "Image Recognition Tool" a few days, I think you could improve it :
> by adding the dimensional constraints in front of each of the pre-trained models,
> by adding a true tool to divide the training data correctly (in order to have an equivalent number of images for each of the labels)
> at least, allow the tool to use black & white images (I wanted to test it on the MNIST, but the tool tells me that it necessarily needs RGB images) ?
Question : do you in the future allow the user to choose between CPU or GPU usage ?
In any case, thank you again for this new tool, it is certainly perfectible, but very simple to use, and I sincerely think that it will allow a greater number of people to understand the many use cases made possible thanks to image recognition.
Thank you again
Kévin VANCAPPEL (France ;-))
Thank you again.
Kévin VANCAPPEL
Hello all,
Like many softwares in the market, Alteryx uses third-party components developed by other teams/providers/entities. This is a good thing since it means standard features for a very low price. However, these components are very regurarly upgraded (usually several times a year) while Alteryx doesn't upgrade it... this leads to lack of features, performance issues, bugs let uncorrected or worse, safety failures.
Among these third-party components :
- CURL (behind Download tool for API) : on Alteryx 7.15 (2006) while the current release is 8.0 (2023)
- Active Query Builder (behind Visual Query Builder) : several years behind
- R : on Alteryx 4.1.3 (march 2022) while the next is 4.3 (april 2023)
- Python : on Alteryx 3.8.5 (2020) whil the current is 3.10 (april 2023)
-etc, etc....
-
of course, you can't upgrade each time but once a year seems a minimum...
Best regards,
Simon
When working on a complex, branching workflow I sometimes go down paths that do not give the correct result, but I want to keep them as they are helpful for determining the correct path. I do not want these branches to run as they slow down the workflow or may produce errors/warnings that muddy debugging the workflow. These paths can be several tools long and are not easily put in a container and disabled. Similar to the Cache and Run Workflow feature that prevents upstream tools from refreshing i am suggesting a Disable all Downstream Tools feature. In the workflow below the tools in the container could be all disabled by a right click on the first sample tool in the container.

Hello --
Many times, I want to summarize data by grouping it, but to really reduce the number of rows, some data needs to be concatenated.
The problem is that some data that is group is repeated and concatenating the data will double, triple, or give a large field of concatenated data.
As an example:
Name State
| A | New York |
| A | New York |
| A | New Jersey |
| B | Florida |
| B | Florida |
| B | Florida |
The above, if we concatenate by State would look like:
| A | New York, New York, New Jersey |
| B | Florida, Florida, Florida |
What I propose is a new option called Concatenate Unique so I would get:
| A | New York, New Jersey |
| B | Florida |
This would prevent us from having to use a Regex formula to make the column unique.
Thanks,
Seth
Hello,
A lot of tools that use R Macro (and not only preductive) are clearly outdated in several terms :
1/the R package
2/the presentation of the macro
3/the tools used
E.g. : the MB_Inspect
Ugly but wait there is more :

Also ; the UI doesn't help that much with field types.
Best regards,
Simon

I am aware that an Auto-Documenter tool is available in the Gallery, but that has not been maintained since 2020.
It would be great if Alteryx could have that as an added feature to the Designer as an option for end-users to utilize.
The breakdown of it can be done via XML parsing as such:
<Nodes>: Configuration of tools
<Connections>: The tools used
<Properties>: Workflow properties
Right now, the current workaround is for users to export their XML, and the internal Alteryx development team has to build another workflow that reads the XML accordingly + parses it to fit what is needed.
It would be better for Alteryx to build something more robust, and perhaps even include some elements of AiDIN which they are promoting now.
Hello!
I am just making a quick suggestion, specifically for the Formula tool within Alteryx.
Often when I am working on a larger workflow - I will end up optimising the workflow towards the end. I typically end up removing unnecessary tools, fields, and rethinking my logic.
Much of this optimisation, is also merging formula tools where possible. For instance, if I have 3 formulas - its much cleaner (and I would suspect faster) to have these all within one tool. For instance, a scaled down example:

to this:

This requires a lot of copy and paste - especially if the formulas/column names are long - this can be two copy and pastes, and waiting for tools to load between them, per formula (i do appreciate, this sounds an incredibly small problem to have, but on what I would consider a large workflow, a tool loading can actually take a couple of seconds - and this could burn some time. Additionally, there's always potential problems when it comes to copy/pasting or retyping with errors).
My proposed solution to this, is the ability to drag a formula onto another - very similar to dragging a tool onto a connection. This integration would look like:

Drag to the first formula:

Release:

Formula has been appended to the formula tool:

I think this will help people visually optimise their workflows!
Cheers,
TheOC
Sounds simple :

Best regards,
Simon
Dear Alteryx,
One day, when I pass from this life to the next I'll get to see and know everything! Loving data, one of my first forays into the infinite knowledge pool will be to quantify the time lost/mistakes made because excel defaults big numbers like customer identifiers to scientific notation. My second foray will be to discover the time lost/mistakes made due to
Unexpanded Mouse Wheel Drop Down Interaction
Riveting right? What is this? It's super simple, someone (not just Alteryx) had the brilliant idea that the mouse wheel should not just be used to scroll the page, but drop down menus as well. What happens when both the page and the drop down menu exist, sometimes disaster but more often annoyance. Case in point, configuring an input tool.
See the two scenarios below, my input is perfectly configured, I'll just flick my scroll wheel to see what row I decided to start loading from
Happy Path, cursor not over drop down = I'll scroll down for you ↓

Sad Path, cursor happened to hover the dropdown sometimes on the way down from a legit scroll = what you didn't want Microsoft Excel Legacy format?

And you better believe Alteryx LOVES having it's input file format value changed in rapid succession., hold please...

Scroll wheels should scroll, but not for drop down menus unless the dropdown has been expanded.
Oh and +1 for mouse horizontal scrolling support please.
Hello all,
As of today, you can only (officially) connect to a postgresql through ODBC with the SIMBA driver
help page :
https://help.alteryx.com/current/en/designer/data-sources/postgresql.html#postgresql
You have to download the driver from your license page

However there is a perfectly fine official driver for postgresql here https://www.postgresql.org/ftp/odbc/releases/
I would like Alteryx to support it for several obvious reasons :
1/I don't want several drivers for the same database
2/the simba driver is not supported for last releases of postgresql
3/the simba driver is somehow less robust than the official driver
4/well... it's the official driver and this leads to unecessary between Alteryx admin/users and PG db admin.
Best regards,
Simon

We all know and love the Comment tool. It's a staple of every workflow to give users an idea of the workflow in finer details. It's a powerful tool - it helps adds context to tools and containers, and it also serves as an image placeholder for us to style our workflows as aesthetically pleasing as possible.
Now, the gensis of this idea is inspired by this post and subsequent research question here.
The Comment Tool today allows you to:
- Write your text and provide context / documentation to your workflow
- Style its shape
- Style its font, colour, and background colour
- Align the text
- Put an image to your workflow

But it would provide way more functionality if it had the capabilities of another awesome Alteryx tool that is not so frequently mentioned... the Report Text Tool!
What's missing in the Comment tool that the Report Text tool has?
- The ability to add active data records from the workflow to its text
- Its wider range of styles which allows for more functionality such as with its Special Tags functions
- Its ability to hyperlink
- Text mode options!

Now, whilst I understand that the Report Text tool is just that, a tool that needs to be connected to the data to work, so too does the Comment tool (to a lesser extent).
It would be awesome to have the ability to connect the data to the Comment tool as it was a Control Container-like connector. It can also be just like the Report Text tool with an optional input, thereby making it like a normal Comment tool.
To visualize my point:

The benefits of doing so:
- Greater flexibility to the user
- Styles are endgame
- Users can use the comment box as a checksum or even a total count / checker to ensure everything is working as intended
- Makes the comment tool more powerful as a dynamic workflow documentation tool
I think it'll be a killer feature enhancement to the comment tool. Hoping to hear comments on this!
Kindly like, share, and subscribe I mean comment your support. Thanks all! 😁
-caltang
hello,
version 2021.4 does not allow workflows to run if any of their input files are open.... would be great to have an option for the input tool that switches on/off the ability to read from open files. Some of my input files have frequent data changes and i tend to keep them open while testing/simulating results
Thank you,
abdou
Allow users the ability to add a delay on the connection between Control Container tools. I frequently have to rerun workflows that use the control container because the workflow has not registered that the file was properly closed on outputting from one output tool to the next. The network drives haven't resolved and show that the file is still open while its moved on to the next control container. Users should have an option in the Configuration screen to add a delay before a signal is sent for the next container to run.
In the past I was able to use a CReW tool (Wait a Second) in conjunction with the Block Until Done tool to add the delay in manually. But I have since converted all of my workflows over to Control Containers. Since then half of the times the workflow has run I encounter the following errors.


This is a pretty quick suggestion:
I think that there are a lot of formulas that would be easier to write and maintain if a SQL-style BETWEEN operator was available.
Essentially, you could turn this:
ToNumber([Postal Code]) > 1000 AND ToNumber([Postal Code]) < 2500
Into this:
ToNumber([Postal Code]) BETWEEN 1000 AND 2500
That way, if you later had to modify the ToNumber([Postal Code]), you only have to maintain it once. Its both aesthetically pleasing and more maintainable!
Please improve the Excel XLSX output options in the Output tool, or create a new Excel Output tool,
or enhance the Render tool to include an Excel output option, with no focus on margins, paper size, or paper orientation
The problem with the current Basic Table and Render tools are they are geared towards reporting, with a focus on page size and margins.
Many of us use Excel as simply a general output method, with no consideration for fitting the output on a printed page.
The new tool or Render enhancement would handle different formats/different schemas without the need for a batch macro, and would include the options below.
The only current option to export different schemas to different Sheets in one Excel file, without regard to paper formatting, is to use a batch macro and include the CReW macro Wait a Second, to allow Excel to properly shut down before a new Sheet is created, to avoid file-write-contention issues.
Including the Wait a Second macro increased the completion time for one of my workflows by 50%, as shown in the screehshots below.
I have a Powershell script that includes many of the formatting options below, but it would be a great help if a native Output or Reporting tool included these options:
Allow options below for specific selected Sheet names, or for All Sheets
AllColumns_MaxWidth: Maximum width for ALL columns in the spreadsheet. Default value = 50. This value can be changed for specific columns by using option Column_SetWidth.
Column_SetWidth: Set selected columns to an exact width. For the selected columns, this value will override the value in AllColumns_MaxWidth.
Column_Centered: Set selected columns to have text centered horizontally.
Column_WrapText: Set selected columns to Wrap text.
AllCells_WrapText: Checkbox: wrap text in every cell in the entire worksheet. Default value = False.
AllRows_AutoFit: Checkbox: to set the height for every row to autofit. Default value False.
Header_Format: checkbox for Bold, specify header cells background color, Border size: 1pt, 2pt, 3pt, and border color, Enable_Data_Filter: checkbox
Header_freeze_top_row: checkbox, or specify A2:B2 to freeze panes
Sheet_overflow: checkbox: if the number of Sheet rows exceeds Excel limit, automatically create the next sheet with "(2)" appended
Column_format_Currency: Set selected columns to Currency: currency format, with comma separators, and negative numbers colored red.
Column_format_TwoDecimals: Set selected columns to Two decimals: two decimals, with comma separators, and negative numbers colored red.
Note: If the same field name is used in Column_Currency and Column_TwoDecimals, the field will be formatted with two decimals, and not formatted as currency.
Column_format_ShortDate: Set selected columns to Short Date: the Excel default for Short Date is "MM/DD/YYYY".
File_suggest_read_only: checkbox: Set flag to display this message when a user opens the Excel file: "The author would like you to open 'Analytic List.xlsx' as read-only unless you need to make changes. Open as read-only?
vb code: xlWB.ReadOnlyRecommended = True
File_name_include_date_time: checkboxes to add file name Prefix or Suffix with creation Date and/or Time
========
Examples:
My only current option: use a batch macro, plus a Wait a Second macro, to write different formats/schemas to multiple Sheets in one Excel file:

Using the Wait a Second macro, to allow Excel to shut down before writing a new Sheet, to avoid write-contention issues, results in a workflow that runs 50% longer:

{kind=link}
Hello,
As of today, we can't choose exactly the file format for Hadoop when writing/creating a table. There are several file format, each wih its specificity.
Therefore I suggest the ability to choose this file format :
-by default on connection (in-db connection or in-memory alias)
-ability to choose the format for the writing tool itself.
Best regards,
Simon
Hello all,
We all love pretty much the in-memory multi-row formula tool. Easy to use, etc. However, the indb counterpart does not exist.
I see that as a wizard that would generate windowing functions like LEAD or LAG
https://mode.com/sql-tutorial/sql-window-functions/
Best regards,
Simon
Currently there is a function in Alteryx called FindString() that finds the first occurrence of your target in a string. However, sometimes we want to find the nth occurrence of our target in a string.
FindString("Hello World", "o") returns 4 as the 0-indexed count of characters until the first "o" in the string. But what if we want to find the location of the second "o" in the text? This gets messy with nested find statements and unworkable beyond looking for the second or third instance of something.
I would like a function added such that
FindNth("Hello World", "o", 2) Would return 7 as the 0-indexed count of characters until the second instance of "o" in my string.
Hi all,
When preparing reports with formatting for my stakeholders. They want these sent straight to sharepoint and this can be achieved via onedrive shortcuts on a laptop. However when sending the workflow for full automation, the server's C drive is not setup with the appropriate shortcuts and it is not allowed by our admin team.
So my request is to have the sharepoint output tool upgraded to push formatted files to sharepoint.
Thank you!
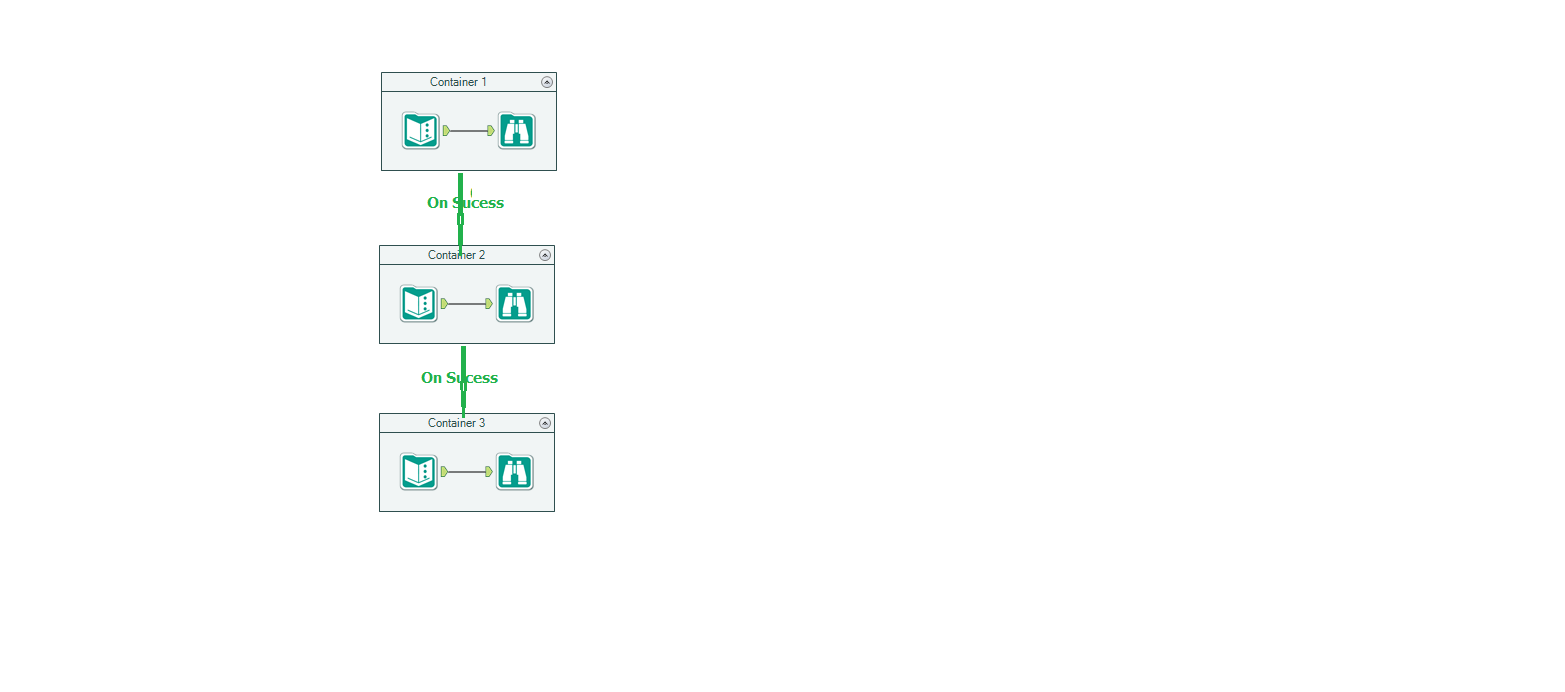
Hi
Wanted to control the order of execution of objects in Alteryx WF but right now we have ONLY block until done which is not right choice for so many cases
Can we have a container (say Sequence Container) and put piece of logic in each container and have control by connecting each container?
Hope this way we can control the execution order
It may be something looks like below
- New Idea 377
- Accepting Votes 1,784
- Comments Requested 21
- Under Review 178
- Accepted 47
- Ongoing 7
- Coming Soon 13
- Implemented 550
- Not Planned 107
- Revisit 56
- Partner Dependent 3
- Inactive 674
-
Admin Settings
22 -
AMP Engine
27 -
API
11 -
API SDK
228 -
Category Address
13 -
Category Apps
114 -
Category Behavior Analysis
5 -
Category Calgary
21 -
Category Connectors
252 -
Category Data Investigation
79 -
Category Demographic Analysis
3 -
Category Developer
217 -
Category Documentation
82 -
Category In Database
215 -
Category Input Output
655 -
Category Interface
246 -
Category Join
108 -
Category Machine Learning
3 -
Category Macros
155 -
Category Parse
78 -
Category Predictive
79 -
Category Preparation
402 -
Category Prescriptive
2 -
Category Reporting
204 -
Category Spatial
83 -
Category Text Mining
23 -
Category Time Series
24 -
Category Transform
92 -
Configuration
1 -
Content
2 -
Data Connectors
982 -
Data Products
4 -
Desktop Experience
1,605 -
Documentation
64 -
Engine
134 -
Enhancement
407 -
Event
1 -
Feature Request
218 -
General
307 -
General Suggestion
8 -
Insights Dataset
2 -
Installation
26 -
Licenses and Activation
15 -
Licensing
15 -
Localization
8 -
Location Intelligence
82 -
Machine Learning
13 -
My Alteryx
1 -
New Request
226 -
New Tool
32 -
Permissions
1 -
Runtime
28 -
Scheduler
26 -
SDK
10 -
Setup & Configuration
58 -
Tool Improvement
210 -
User Experience Design
165 -
User Settings
86 -
UX
227 -
XML
7
- « Previous
- Next »
- abacon on: DateTimeNow and Data Cleansing tools to be conside...
-
 TonyaS
on:
Alteryx Needs to Test Shared Server Inputs/Timeout...
TonyaS
on:
Alteryx Needs to Test Shared Server Inputs/Timeout...
-
 TheOC
on:
Date time now input (date/date time output field t...
TheOC
on:
Date time now input (date/date time output field t...
- EKasminsky on: Limit Number of Columns for Excel Inputs
- Linas on: Search feature on join tool
-
MikeA
on:
Smarter & Less Intrusive Update Notifications — Re...
- GMG0241 on: Select Tool - Bulk change type to forced
-
Carlithian
on:
Allow a default location when using the File and F...
- jmgross72 on: Interface Tool to Update Workflow Constants
-
pilsworth-bulie
n-com on: Select/Unselect all for Manage workflow assets
| User | Likes Count |
|---|---|
| 31 | |
| 7 | |
| 3 | |
| 3 | |
| 3 |