Alteryx Designer Desktop Ideas
Share your Designer Desktop product ideas - we're listening!Submitting an Idea?
Be sure to review our Idea Submission Guidelines for more information!
Submission Guidelines- Community
- :
- Community
- :
- Participate
- :
- Ideas
- :
- Designer Desktop: Top Ideas
Featured Ideas
Hello,
After used the new "Image Recognition Tool" a few days, I think you could improve it :
> by adding the dimensional constraints in front of each of the pre-trained models,
> by adding a true tool to divide the training data correctly (in order to have an equivalent number of images for each of the labels)
> at least, allow the tool to use black & white images (I wanted to test it on the MNIST, but the tool tells me that it necessarily needs RGB images) ?
Question : do you in the future allow the user to choose between CPU or GPU usage ?
In any case, thank you again for this new tool, it is certainly perfectible, but very simple to use, and I sincerely think that it will allow a greater number of people to understand the many use cases made possible thanks to image recognition.
Thank you again
Kévin VANCAPPEL (France ;-))
Thank you again.
Kévin VANCAPPEL
Hello all,
I'm currently learning Pythin language and there is this cool feature : you can multiply a string

Pretty cool, no? I would like the same syntax to work for Tableau.
Best regards,
Simon
Hello,
Enhancement of 'IN' functionality (ie. in Filter tool), so using range instead of citing particular values for example:
instead [ID] IN (1,2,3,52,53,54,100,101,102) something like that [ID] IN (1-3,52-54,100-102).
Hello,
In Datascience, Levenshtein and Jaro Winkler distances are used to quanitify a similarity between two strings.
Here the wikipedia pages
https://en.wikipedia.org/wiki/Levenshtein_distance
https://en.wikipedia.org/wiki/Jaro%E2%80%93Winkler_distance
Note 1 : the Levenshtein and Jaro Distances are already used in Fuzzy Matching tool, so that shouldn't be a huge work to include it in formula
Note 2 : there is a useful macro on the galley https://gallery.alteryx.com/#!app/LevenshteinDistance/5c54701f826fd30988f02779
Note 3 : some product already have it implemented such as Apache Hive or Qlik Sense
Best regards,
Simon
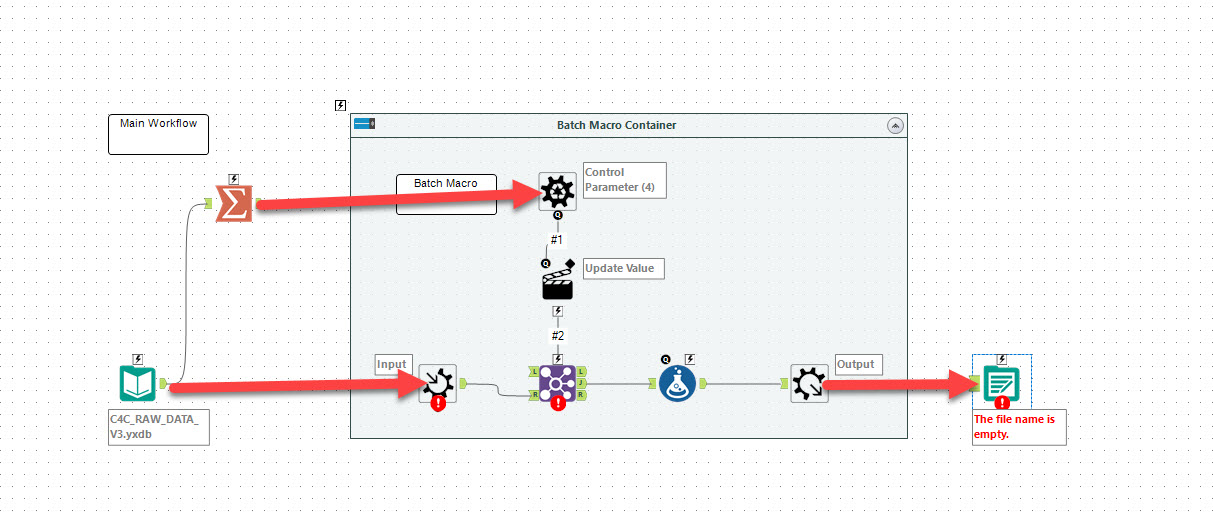
I like to suggest having a Batch Macro Container (besides the existing Container) which acts as a Batch Macro within a Workflow and is stored within the Workflow.
I understand that having a batch macro available as a separate tool can be very powerful and reduces redundant work. However, very often Batch Macros are set up for a specific workflow only and are of no use for other workflows. The Creation of a Batch Macro in a container will significantly reduce the time to deploy a batch macro and keeps the Macro folder clean of one-time Batch Macros.
Attached a picture of how this could look like
Thanks
Manuel
When developing and/or troubleshooting workflows, I frequently disable the outputs using the checkbox in the Runtime configuration settings to speed up the workflow and prevent sending emails and/or overwriting data in the output sources... however, 9/10 times I forget to turn off this checkbox when I save my workflow back up to the Gallery. This results in countless emails from users to the tune of "I ran the workflow successfully, but there was no output?" 🙂
Would love love love to see some sort of warning notification (similar to the ones that already shown for data sources etc.) when saving to the Gallery if the "Disable All Tools that Write Output" option is selected in the Runtime settings.
Thank you!!
NJ
Idea:
A tool for encryption/decription of a column with multiple encrypiton options is the idea.
Both one way and two way encription should be possible.
Rationale:
Clients are in need of encrypting customers' personal identification data
before sharing it with a third party like consultants and analytics service providers etc.
When insights are provided back the data owner needs to quickly decrypt the ID field and get results or decide actions.
Clients:
This is especially an important case for banks, non bank financial institutions and telecom companies in EU countries and similar (Turkey has similar strict rules)
Best
The Source field of the field metadata is very useful, but has some problems.
- It is repetitious. A long connection string repeated for many fields from the same source can bloat the size of the workflow above 10 MB, and when removed is around 0.5 MB.
- It exposes sensitive information about a company's infrastructure, such as server names, ports, user ids, and proprietary data structures.
I first started paying attention when we found a user's password in the metadata because they had passed it as a string to the Dynamic Input Tool (separate Idea submitted for that - LINK). Then when I had to share an App with the Alteryx Support team for support with an issue, I thought to check the metadata, and I noticed that the file was too big and was exposing information that I would not normally share with another company.
I'm not sure how you want to handle this, but here's some thoughts:
- Default the Source field to 'off' and provide users the option to turn it 'on' in the workflow/app settings.
- Provide a mechanism to strip the 'Source' field at time of saving or exporting the workflow.
- If nothing else, provide education to users on the implications of including this information in the file.
Thanks for listening!
Cameron
I feel like I must be missing something, but saw a similar suggestion for TDE outputs, so maybe this really doesn't currently exist. We sometimes add descriptions to fields we create, and some inputs come with descriptions, but we can't seem to get them into the final database using the Output tool. Can there be a checkbox to persist the metadata along with the data when writing to a database?
We now have the ability to output to an ESRI File Geodatabase, which is great, but it only allows you to output it to the WGS84 coordinate system. I would like to have the same functionality to export it to other projections or coordinate systems similar to the ESRI Shapefile or ESRI Personal Geodatabase output tools (we specifically need NAD83 but I'm sure others would like other options as well).
It would be great if the "fields from connected tool" option pulled fresh data at runtime when used in the gallery and pulling data from non-interface tools. The external source option doesn't have many settings (i.e. I can just point to one file), whereas the possibilities would be endless if I could use the full suite of tools to create a data set, at runtime, to pass to the list box/dropdown.
There would be great usefulness in having event triggers in 2 different places:
- Similar to Informatica - it would be useful to have event triggers for workflow - specifically "trigger when file arrives" or "trigger when value exceeds X"
- It would be also useful to have an event trigger component with an input so that we can use semaphore type flags to control sequencing in complex sets of flows. For example:
- When the ETL is done - mark the "Completed" flag as true
- The reporting job is running, waiting for a completed flag to complete
Overall, it would be useful for Alteryx to have event-driven triggers.
Would love to see a tool that allows you to find the Top N or Bottom N% etc. using a single tool, rather than the current common practices of using 2-3 tools to accomplish this simple task. It's possible some/all of this functionality could be added by simply expanding the current Sample tool to include more options, or at least mirroring the configuration of the Sample Tool in the creation of a new "Top/Bottom Tool."
For example, let's say I wanted to find the top 5 student grades, and then compare all scores to those top 5 grades. I would currently need to do something along the lines of Sort descending (and/or Summarize Tool, if grouping is needed) + Sample Tool (First N Records) + Join the results back to the data. That's anywhere from 3-4 tools to accomplish a simple task that could potentially be done with 1-2.
I'm envisioning this working somewhat like the Top/Bottom rules in Excel Conditional Formatting (see below), and similar to some of the existing options in the Sample Tool (also see below). For example, rather than only being able to select the First N Records in the Sample Tool, I could indicate that I want to select the Top N Records, or the Bottom N% Records. This would prevent the additional step of having to group/sort your data before using the Sample Tool, especially in cases where you're then having to put your records back into their original order rather than leaving them in their grouped/sorted state. You'd still want to have the option of choosing grouping fields if desired. You would also need to have a drop-down field to indicate which field to apply the "Top/Bottom rules" to.


A list of potential "Top/Bottom" options that I believe would be great additions include:
- Top N
- Bottom N
- Top N %
- Bottom N %
- Above Average
- Below Average
- Within a Percentile Range (i.e. "Between 20-30%")
- Skip Top N
- Skip Bottom N
The value added with just the options above would be huge in helping to streamline workflows and reduce unnecessary tools on the canvas.
Hi to all,
I have seen one or two posts requesting ability to total up rows and/or columns of numbers, however this idea also requests the ability to subtotal data by a field and also produce an overall total.
This could be an extension to existing tools such as 'Summarise' and 'Cross Tab' or could be a stand alone tool. Desired output of using a tool like this would produce something like this:

This would be incredibly useful for building reports within Alteryx as well as analysing the data, and cut down the amount of tools currently required to produce this. I have seen a third party tool which does some of this but this adds the ability to subtotal.
thanks - Roger
Hi,
With multiple Workflows open, I'd like to be able to grab one of the Workflow tabs and drag it out on to the desktop. This act would then cause a new Alteryx Window to open up with the Workflow that was pulled out. Just like when you have multiple tabs open in I.E. and you drag a tab out and drop it on the desktop - you end up getting another I.E. opened up and the tab you dragged out is in the newly opened I.E.
This would be handy because I'm often wanting to copy/paste tools, formulas, etc. and it would be nice to do that w/o flipping from one tab to another.
I know I can right-click and open another Alteryx but when opening several - they all open in the same one.
Thanks,
Brad
I can't even count how often I looked at an Excel, CSV or even YXDB file, where I KNEW that it was generated by Alteryx, but I couldn't remember the workflow. Currently, I have to simply go through all workflows I ever build and see if I can find it.
Theoretically, I could use a text-search across all workflows and see if I can find the output names - problem here: Most of my output filenames are generated dynamically on the run.
It would be amazing if Alteryx could simply write the Workflow name (maybe even path) into the metadata of a file.

(Screenshot from Google, as my os is set to German)
How about, we write "This file was created with by "Create Controlling Reports.yxmd on 2023-02-06 with Alteryx Designer 2021.4.298434" in the field 'Comments'?
This would make it extremely easy to find what workflow the file generated. I think it would be an option to talk about "filepath" instead of filename, but the filepath could include the local machine name, which might include GDPR information.
@Community: Is there any additional information that you'd like to see in the metadata?
Best
Alex
In a similar vein to the forthcoming enhancement of being able to disable a specific output tool, my idea is to have the inverse where you can globally disable all outputs and then enable specific ones only. This should help reduce the number of clicks required/avoid workarounds using containers to obtain this functionality and allow users to be very specific in which outputs run and don't run as required.
Credit to @pgdelafuente in his post Export Variables from Assisted Modelling Feature I... - Alteryx Community
This came up in a call with a large client - basically there's no easy way to output the feature importance plot, the accuracy metrics of the selected model (i.e. root mean squared error, correlation, max error, etc.). I would assume this is an easy addition into the Assisted Modeling tools, and perhaps useful for some of the Predictive tools!
It would be great to have an option in the Output Data tool to write the workflow name to the Info properties of Excel outputs.
Maybe something like this:

So that whenever you open an Excel file you always have a way of finding the name of the workflow that created the file.

{kind=link}
This would make it so much easier as I often have to share Excel files with colleagues and customers and then need a way of tracking them back to workflows weeks or months later.
This is similar to a prior idea now marked complete "Allow macro metadata to persist until next run". I tried the check box solution and still have the same issue, running V11.
What we NEED is for tools that derive columns like CrossTab to retain metadata from the most recent run and thus pass that metadata downstream for further tools and development.
Use case:
I have several cross tabs and before V11 I could run the flow once to push metadata downstream, then add or modify tools downstream and the derived fields from the cross tab stayed available in those tools to be recognized and referenced as I add more tools and logic. Now in V11 I am finding if I click on a tool or add a tool downstream the metadata for the derived columns disappears.
I attached pics to illustrate where I have 6 CrossTabs and decided I needed to add a summary downstream. I had to run the flow to get metadata populated which is normal and I added the first summary, then inserted another summary and immediately the derived column metadata was lost in all paths after the crosstabs. so ended up having to re-run the flow 5 more times for each summary tool added. then I had to re-run it 5 more times to adjust column names in selects after downstream joins.
I end up wasting a lot of time having to re-run a sufficient test file to feed all the variety of data necessary to generate all columns between most edits or new tool adds. What used to take ~5 minutes to do now takes ~35
I recall seeing and discussing this issue previously and hoped the check box would resolve but It does not fix the issue.
We see similar issue for tools downstream from other tools where the columns are derived or uncertain until that tool runs, such as, transpose, Joins and Unions. I recall some discussion at user groups and in the community but the only reference I found this morning of seeming relevance is the one I mentioned above.
DearAlteryx team and community,
all the best for 2021!
Thank you very much for enhancing the output option from Alteryx Designer to Excel keeping the format.
For a lot of my use cases this is very helpful!
Still, there are some use cases left. In case I want to overwrite a calculated/linked number (e.g. calculated prediction) with the Actual number, it would be very helpful to feed into those cells as well. At the moment Alteryx is doing the job but I receive a lot of Excel Errors (xml errors) and a corupt Excel file when overwriting calculated fields/linked fields.
Is there a chance to extend the current setup for all of those cases?
Thanks and best regards
Chhristoph
- New Idea 376
- Accepting Votes 1,784
- Comments Requested 21
- Under Review 178
- Accepted 47
- Ongoing 7
- Coming Soon 13
- Implemented 550
- Not Planned 107
- Revisit 56
- Partner Dependent 3
- Inactive 674
-
Admin Settings
22 -
AMP Engine
27 -
API
11 -
API SDK
228 -
Category Address
13 -
Category Apps
114 -
Category Behavior Analysis
5 -
Category Calgary
21 -
Category Connectors
252 -
Category Data Investigation
79 -
Category Demographic Analysis
3 -
Category Developer
217 -
Category Documentation
82 -
Category In Database
215 -
Category Input Output
655 -
Category Interface
246 -
Category Join
108 -
Category Machine Learning
3 -
Category Macros
155 -
Category Parse
78 -
Category Predictive
79 -
Category Preparation
402 -
Category Prescriptive
2 -
Category Reporting
204 -
Category Spatial
83 -
Category Text Mining
23 -
Category Time Series
24 -
Category Transform
92 -
Configuration
1 -
Content
2 -
Data Connectors
982 -
Data Products
4 -
Desktop Experience
1,604 -
Documentation
64 -
Engine
134 -
Enhancement
406 -
Event
1 -
Feature Request
218 -
General
307 -
General Suggestion
8 -
Insights Dataset
2 -
Installation
26 -
Licenses and Activation
15 -
Licensing
15 -
Localization
8 -
Location Intelligence
82 -
Machine Learning
13 -
My Alteryx
1 -
New Request
226 -
New Tool
32 -
Permissions
1 -
Runtime
28 -
Scheduler
26 -
SDK
10 -
Setup & Configuration
58 -
Tool Improvement
210 -
User Experience Design
165 -
User Settings
85 -
UX
227 -
XML
7
- « Previous
- Next »
- abacon on: DateTimeNow and Data Cleansing tools to be conside...
-
 TonyaS
on:
Alteryx Needs to Test Shared Server Inputs/Timeout...
TonyaS
on:
Alteryx Needs to Test Shared Server Inputs/Timeout...
-
 TheOC
on:
Date time now input (date/date time output field t...
TheOC
on:
Date time now input (date/date time output field t...
- EKasminsky on: Limit Number of Columns for Excel Inputs
- Linas on: Search feature on join tool
-
MikeA
on:
Smarter & Less Intrusive Update Notifications — Re...
- GMG0241 on: Select Tool - Bulk change type to forced
-
Carlithian
on:
Allow a default location when using the File and F...
- jmgross72 on: Interface Tool to Update Workflow Constants
-
pilsworth-bulie
n-com on: Select/Unselect all for Manage workflow assets
| User | Likes Count |
|---|---|
| 6 | |
| 5 | |
| 4 | |
| 3 | |
| 2 |