Alteryx Designer Desktop Ideas
Share your Designer Desktop product ideas - we're listening!Submitting an Idea?
Be sure to review our Idea Submission Guidelines for more information!
Submission Guidelines- Community
- :
- Community
- :
- Participate
- :
- Ideas
- :
- Designer Desktop: Hot Ideas
Featured Ideas
Hello,
After used the new "Image Recognition Tool" a few days, I think you could improve it :
> by adding the dimensional constraints in front of each of the pre-trained models,
> by adding a true tool to divide the training data correctly (in order to have an equivalent number of images for each of the labels)
> at least, allow the tool to use black & white images (I wanted to test it on the MNIST, but the tool tells me that it necessarily needs RGB images) ?
Question : do you in the future allow the user to choose between CPU or GPU usage ?
In any case, thank you again for this new tool, it is certainly perfectible, but very simple to use, and I sincerely think that it will allow a greater number of people to understand the many use cases made possible thanks to image recognition.
Thank you again
Kévin VANCAPPEL (France ;-))
Thank you again.
Kévin VANCAPPEL
Currently if one wants to compare different alteryx files or different versions of the same file - one needs to compare the XML files. If you are not very familiar with navigating XML, this poses a risk as one may not be able to identify all changes.
It would be a great addition to Alteryx to integrate Alteryx with Git, Subversion, CVS, Mercurial, and GitHub as this tool is becoming the go-to tool for data processing for data analysts and even programmers.
This additional functionality to compare previous versions (diff) and also to merge alteryx workflows if two people are working on the same workflow, and also to easily see what changes have been committed/ made by other developers and when would make Alteryx a much more powerful tool and would open doors to other types of users, as essentially you can run anything through Alteryx.
Hi there,
Just got a new 4k UHD monitor, and found that Alteryx Designer doesn't scale well in default settings in Windows. Fonts are blurry but icons are the right size.
If instead you change compatabilty mode to allow the application to force scaling, then the fonts and icons end up all different sizes.
Could you change the fonts and icons to scale gracefully in Windows 10 to full 4k UHD HDR - especially on the large size monitors (30 inch plus)?
Shot 1: default mode - blurry text - badly scaled by Windows 10. It's not easy to see here because the image is small - but all the text is blurry like a badly blown up BMP file.

Shot 2: Override Windows 10 DPI scaling and set to "Application" mode
You can see in the picture below that text is now super-sharp but the the play button; save button are all tiny; the fonts are different sizes (look in the properties tab on the left) etc.

The expression editor in the RegEx tool is only a single line, which makes it really hard to edit long regular expressions. See attached photo comparing the expression editor in the RegEx tool compared to the formula tool for the same expression. Please make the RegEx editor box either wrap to multiple lines, have a pop-out expression editor, or something so we can see long expressions.

Similar to the thoughts in this idea, it would be great if the parenthesis matching functionality could be added to the formula tool as well.
A few suggestions that I think can improve the Sharepoint Files Output Tool:
- Maybe I'm missing it, but I cannot see how you can delete a file from the output list once you've added it:
- Have the write headers output checkbox ticked by default as I expect this is the more common expectation:
- Take the file extension by default based on the users selection in the Options tab as I shouldn't have to write .xlsx for the extension:




(1) I would like to have more text formatting options available in the Comment Tool, such as:
- set different format for selected words (color, bold, underline, size..)
- indenting
- bullet list or numbered list
(2) Option to remove or recolor the blue outline of the comment box. (Especially when I have a comment in a color-filled comment box, I would prefer a comment box without a dark outline.)
(3) UX - Add an arrow cursor to indicate resizing functionality
Please include IBM DB2 as an in-Database option. Currently, my primary use of Alteryx is for copying DB2 tables into Teradata for use on that server. Copying large tables and particularly joining several tables and copying the results to Teradata is too slow in Alteryx.
Alteryx hosting CRAN
Installing R packages in Alteryx has been a tricky issue with many posts over the years and it fundamentally boils down to the way the install.packages() function is used; I've made a detailed post on the subject. There is a way that Alteryx can help remedy the compatibility challenge between their updates of Predictive Tools and the ever-changing landscape that is open-source development. That way is for Alteryx to host their own CRAN!
The current version of Alteryx runs R 4.1.3, which is considered an 'old release', and there are over 18,000 packages on CRAN for this version of R. By the time you read this post, there is likely a newer version of one of these packages that the package author has submitted to the R Foundation's CRAN. There is also a good chance that package isn't compatible with any Alteryx tool that uses R. What if you need that package for a macro you've downloaded? How do you get the old version, the one that is compatible? This is where Alteryx hosting CRAN comes into full fruition.
Alteryx can host their own CRAN, one that is not updated by one of many package authors throughout its history, and the packages will remain unchanged and compatible with the version of Predictive Tools that is released. All we need to do as Alteryx users is direct install.packages() to the Alteryx CRAN to get our new packages, like so,
install.packages(pkg_name, repo = "https://cran.alteryx.com")
There is a R package to create a CRAN directory, so Alteryx can get R to do the legwork for them. Here is a way of using the miniCRAN package,
library(miniCRAN)
library(tools)
path2CRAN <- "/local/path/to/CRAN"
ver <- paste(R.version$major, strsplit(R.version$minor, "\\.")[[1]][1], sep = ".") # ver = 4.1
repo <- "https://cran.r-project.org" # R Foundation's CRAN
m <- available.packages() # a matrix of all packages and their meta data from repo
pkgs4CRAN <- m[,"Package"] # character vector of all packages from repo
makeRepo(pkgs = pkgs4CRAN, path = path2CRAN, type = c("win.binary", "source"), repos = repo) # makes the local repo
write_PACKAGES(paste(path2CRAN, "bin/windows/contrib", ver, sep = "/"), type = "win.binary") # creates the PACKAGES file for package binaries
write_PACKAGES(paste(path2CRAN, "src/contrib", sep = "/"), type = "source") # creates the PACKAGES files for package sources
It will create a directory structure that replicates R Foundation's CRAN, but just for the version that Alteryx uses, 4.1/.
Alteryx can create the CRAN, host it to somewhere meaningful (like https://cran.alteryx.com), update Predictive Tools to use the packages downloaded with the script above and then release the new version of Predictive Tools and announce the CRAN. Users like me and you just need to tell the R Tool (for example) to install from the Alteryx repo rather than any others, which may have package dependency conflicts.
This is future-proof too. Let's say Alteryx decide to release a new version of Designer and Predictive Tools based on R 4.2.2. What do they do? Download R 4.2.2, run the above script, it'll create a new directory called 4.2/, update Predictive Tools to work with R 4.2.2 and the packages in their CRAN, host the 4.2/ directory to their CRAN and then release the new version of Designer and Predictive Tools.
Simple!
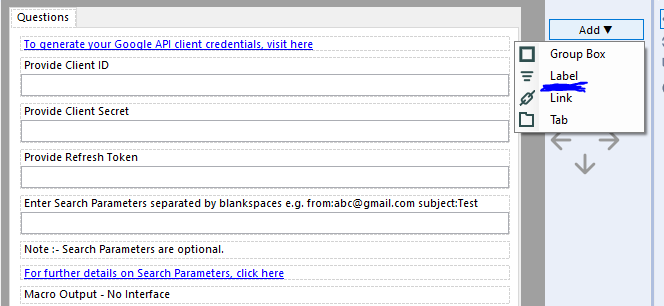
Hi all,
Is it possible to add an option to 'Add an Image' in the settings option of Interface Designer while building Apps or macros?
Currently, we can add Group box, Link, Tab, and Label. It would be really helpful if we can add static images as well!!
This would enable a developer to add an explanatory image just as a link or label is used to communicate to end user.
I am attaching a screenshot for the reference.

Thanks in advance!!
Regards,
Shreyansh Rathod
In the community and in mixed teams - it's very common for people to be caught on the error that "This document was created in a more recent version". Although there are several workarounds (e.g. this one from @WayneWooldridge here https://community.alteryx.com/t5/Alteryx-Knowledge-Base/Adjusting-Alteryx-Files-for-Different-Versio...), this seems like it may be an easy problem to solve more permanently.
Could we add an option to Alteryx to save the file with the lowest compatible version number?
So - for example - if i'm only using components that shipped with version 10, then please mark the file as version 10. If I've used a tool that shipped in 11.0.6 then that needs to be the version number.
This way - files will be back-compatible as far as is possible by default unless using newer components.
Many thanks
Sean
When using the unknown field in a select, you can either select or deselect the fields which will appear afterwards.
I would love to have an option or different to specify elements for fields to appear for instance having :
- *unknown text where you could set the metadata type (for instance vwstring) and maximal length
- *unknown numeric where you could set the type, double or fixed decimal
and for dates too
it would set a default behaviour for incoming text fields or numeric fields allowing for more precise deselction too.
Could you expose a link to the Keyboard Shortcuts (which is here: https://help.alteryx.com/2019.4/HotKeys_Shortcuts.htm?Highlight=keyboard%20shortcuts) on the primary help menu (screenshot below)
This will allow people to get quicker in Alteryx by exposing these shortcuts to more users.

It will be really great if we add Single sign-on (SSO) in download tool. Many users are facing this issue when they're trying to download data from weburl. In some case the url will verfiy the sign-on and then redirect to link from where we can download data. Currently download tool fails to verfiy SSO or siteminder authentication.
When using the formula tool -- one of the nice features is that when you start typing in a function or variable -- the tool will show formulas/variables that begin with that letter and keep changing as you type in more letters. I believe this is called predictive typing.

However, this does not happen in tools like multi-row or multi-field where a user would have to search for functions and variables if they weren't sure what they are.

Can predictive typing be added to the multi-row and multi-field tools? If I want to take it further, any tool that allows a user to use the formula functionality should be able to see predictive typing.
Thanks,
Seth Moskowitz
I really like that I can scroll -- using my mouse -- between the tool groups in Alteryx. Can this UX be added to scroll through my workflows? I usually have a bunch open, and this functionality would be awesome to have there, too! 🙂
PS: Yes, I know I can do Ctrl+Tab...but mouse scrolling is more efficient.

{kind=link}
We have Alteryx running in AWS which seems to be a common setup.Our AWS instances are set-up with IAM roles which has been one of the security measures applied in order to finally allow our enterprise company to allow some development in the cloud. IT will not allow the sharing of Access keys to connect to S3.
- Would like to use the AWS S3 Tools from the connectors palette as the AWS CLI has limited ability to handle/report exceptions or issues with any detail. At the moment, we are limited on what goes into production as we are using CLI for what we can.
- Ideally, an option would be to add to the S3 Tools allowing the user to select IAM Roles rather than Key Access. Refer the screen attached.
The introduction fo a rank tool would be hugely beneficial. Whilst there are currently means to rank using a combination of other tools formula/running total/multirow etc... a specific "Rank Tool" would be provide a seemless and smoother way to rank your data either for further analysis or purely to output this field.
This tool should include a sort by and group by functionaility as well as options for ranking (such as dense ranking or unique ranking) and in addition multi levels of ranking (ie. Rank by "Field A" Then By "Field B" etc...).
Hi,
Currently loading large files to Postgres SQL(over 100 MB) takes an extremely long time. For example writing a 1GB file to Postgres SQL takes 27 minutes! This is serious impacting our ability to use Alteryx as an ETL tool for loading our target Postgres Data Warehouse. We would really like to see the bulk load capacity to Postgres supported by Alteryx to help alleviate the performance issues.
Thanks,
Vijaya
Similar to how the Join tool allows to "Select all Left" or "Select all Right" I'd like to see the Append Fields tool have an option to select all source or select all target. Same for deselect.
We build some pretty robust maps with multiple connections and it would be great to copy the map tool and paste it with all of the connections when we want to tweak the map slightly but keep our original map. It is a regular occurrence for us to have a very detailed map grouping by trade area name and then may want to have an overview map with all of the same connections but slightly different layout. Tracking down the connections, reconnecting them and naming them accordingly takes a substantial amount of time even in the most organized of workflows. This function would be a huge time-saver. It would also be of value with joins and unions - anywhere you have multiple streams coming in.
- New Idea 377
- Accepting Votes 1,784
- Comments Requested 21
- Under Review 178
- Accepted 47
- Ongoing 7
- Coming Soon 13
- Implemented 550
- Not Planned 107
- Revisit 56
- Partner Dependent 3
- Inactive 674
-
Admin Settings
22 -
AMP Engine
27 -
API
11 -
API SDK
228 -
Category Address
13 -
Category Apps
114 -
Category Behavior Analysis
5 -
Category Calgary
21 -
Category Connectors
252 -
Category Data Investigation
79 -
Category Demographic Analysis
3 -
Category Developer
217 -
Category Documentation
82 -
Category In Database
215 -
Category Input Output
655 -
Category Interface
246 -
Category Join
108 -
Category Machine Learning
3 -
Category Macros
155 -
Category Parse
78 -
Category Predictive
79 -
Category Preparation
402 -
Category Prescriptive
2 -
Category Reporting
204 -
Category Spatial
83 -
Category Text Mining
23 -
Category Time Series
24 -
Category Transform
92 -
Configuration
1 -
Content
2 -
Data Connectors
982 -
Data Products
4 -
Desktop Experience
1,605 -
Documentation
64 -
Engine
134 -
Enhancement
407 -
Event
1 -
Feature Request
218 -
General
307 -
General Suggestion
8 -
Insights Dataset
2 -
Installation
26 -
Licenses and Activation
15 -
Licensing
15 -
Localization
8 -
Location Intelligence
82 -
Machine Learning
13 -
My Alteryx
1 -
New Request
226 -
New Tool
32 -
Permissions
1 -
Runtime
28 -
Scheduler
26 -
SDK
10 -
Setup & Configuration
58 -
Tool Improvement
210 -
User Experience Design
165 -
User Settings
86 -
UX
227 -
XML
7
- « Previous
- Next »
- abacon on: DateTimeNow and Data Cleansing tools to be conside...
-
 TonyaS
on:
Alteryx Needs to Test Shared Server Inputs/Timeout...
TonyaS
on:
Alteryx Needs to Test Shared Server Inputs/Timeout...
-
 TheOC
on:
Date time now input (date/date time output field t...
TheOC
on:
Date time now input (date/date time output field t...
- EKasminsky on: Limit Number of Columns for Excel Inputs
- Linas on: Search feature on join tool
-
MikeA
on:
Smarter & Less Intrusive Update Notifications — Re...
- GMG0241 on: Select Tool - Bulk change type to forced
-
Carlithian
on:
Allow a default location when using the File and F...
- jmgross72 on: Interface Tool to Update Workflow Constants
-
pilsworth-bulie
n-com on: Select/Unselect all for Manage workflow assets
| User | Likes Count |
|---|---|
| 32 | |
| 5 | |
| 4 | |
| 3 | |
| 2 |