Alteryx Designer Desktop Ideas
Share your Designer Desktop product ideas - we're listening!Submitting an Idea?
Be sure to review our Idea Submission Guidelines for more information!
Submission Guidelines- Community
- :
- Community
- :
- Participate
- :
- Ideas
- :
- Designer Desktop: Hot Ideas
Featured Ideas
Hello,
After used the new "Image Recognition Tool" a few days, I think you could improve it :
> by adding the dimensional constraints in front of each of the pre-trained models,
> by adding a true tool to divide the training data correctly (in order to have an equivalent number of images for each of the labels)
> at least, allow the tool to use black & white images (I wanted to test it on the MNIST, but the tool tells me that it necessarily needs RGB images) ?
Question : do you in the future allow the user to choose between CPU or GPU usage ?
In any case, thank you again for this new tool, it is certainly perfectible, but very simple to use, and I sincerely think that it will allow a greater number of people to understand the many use cases made possible thanks to image recognition.
Thank you again
Kévin VANCAPPEL (France ;-))
Thank you again.
Kévin VANCAPPEL
Directory Tool retrieves today a lot of information about a file. I must say I appreciate getting easily the size and the last write time.
But why not the owner? I have developped a macro with a powershell to do that but what a nightmare for a so little piece of information.
Hi all,
When debugging an error, we need to verify tool by tool in a sequence to better understand what is really going on.
Sometimes the tools are miles away from each other. Imagine a gigantic workflow with a lot of connections going back and forth and wireless connections everywhere to help the workflow organization. Here is an example with more than 1300 tools:

My idea is to have a shortcut showing all the previous/next tools and by selecting the previous/next one you go directly to them.
Something like this:

What do you guys think about that?
Best,
Fernando Vizcaino
When you start using DCM - you may have existing canvasses which use regular old connection strings which you want to migrate to DCM.
Currently (in 2023.1.1.123) - when you select "Use Data Connection Manager" - it shreds the configuration of your input tool which makes it difficult to just convert these from an existing connection to a DCM connection

The only way to then make sure that you don't lose any configuration on the tool then is to use the XML editing functionality of the tools and copy across your old configuration.
Could you please add the capability to keep my current tool configuration, but just change from using a regular old connection string to using DCM?
Many thanks
Sean
cc: @wesley-siu @_PavelP
Hello,
More and more databases have complex data types such as array, struct or map. This would be nice if we could use it on Alteryx as input, as internal and as output, with calculations available on it.
https://cwiki.apache.org/confluence/display/hive/languagemanual+types#LanguageManualTypes-ComplexTyp...
Best regards,
Simon
I would like to propose three feature enhancements for the Cross Tab tool under the Transform tool category.
1. Bringing Concat Unique functionality, which is an idea that is currently in Coming Soon status.
2. Adding Start and End in addition to Separator, similar to the Concatenate Properties found in the Summarize tool.
3. Changing the Default Size from 2048 to 1073741823 (max V_WString size). It is common for especially new users to ignore the truncation errors and potentially miss important data that may need to be processed downstream.
Currently, when one uses the Google BigQuery Output tool, the only options are to create a table, or append data to an existing table. It would be more useful if there was a process to replace all data in the table rather than appending. Having the option to overwrite an existing table in Google BigQuery would be optimal.
The only thing I have ever found that Excel can do that Alteryx can't is creating a pivot table that allows the user to drill up and down levels of aggregation by collapsing or expanding levels in the data hierarchy. (like this).
Can you add an interactive table to the new interactive charting tool that can provide this level of functionality? It's embarrassing to have to tell Excel users they can't do this in Alteyrx, and likely leads many of them to stick to Excel--and miss out on all the other great things Alteryx can do.
Thank you!
I like the new cache option in 2018.3, but I would like it to function a little bit different. Let's say you cache at a certain point and then continue to build after that. If I reach another checkpoint and want to cache, it currently re-runs the entire workflow (ie it ignores my cache upstream and just goes back to the beginning of the workflow); instead, I would rather have it utilize the upstream cache. Personally, caching is usually an iterative effort during development where I keep caching along the way. The current functionality of the cache is not conducive to this. Thanks!
Hello,
It would be very helpful to have a search box for field names in the summary tool, I think it would help decrease errors by selecting fields by mistake with similar names and will help gain a couple of seconds while looking around for a specific field, particularly with datasets with a lots of them.
Like this:

When email body gets imported using latest version of the Outlook 365 tool, this tool removes the new line separators from the message body, which makes it difficult to parse relevant information out of the message body. New line separators are there prior to message being imported into Alteryx as can be verified when importing same message using different tools (for example, Python or Power Automate). Without new line separators it is not possible to accurately parse message body using Alteryx. Please add the enhancement to the Outlook 365 tool so that it doesn't remove new line separators from the message body.
This limitation of the Outlook 365 tool has been discussed in the community
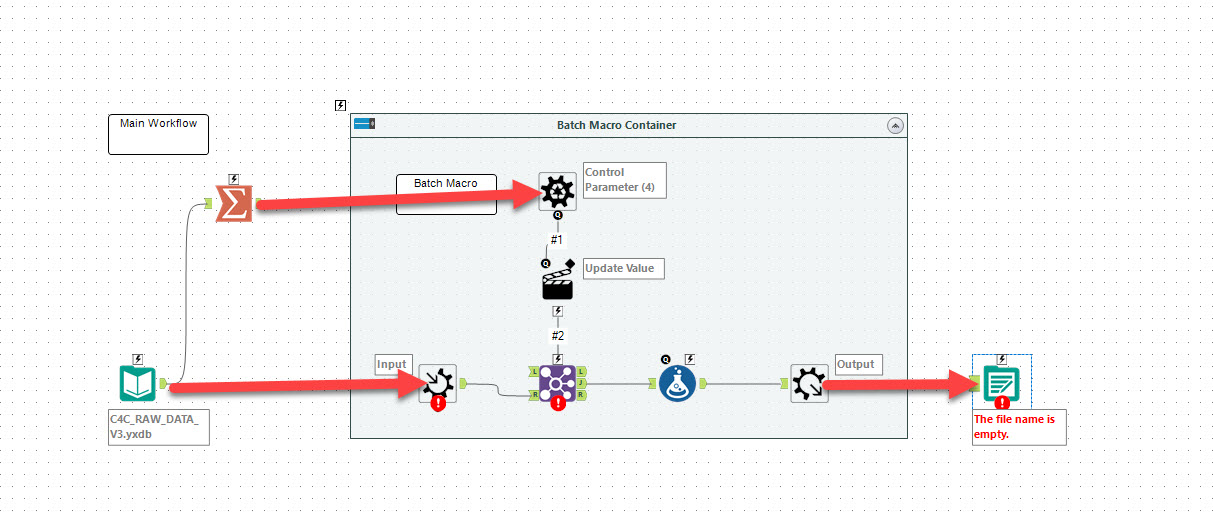
I like to suggest having a Batch Macro Container (besides the existing Container) which acts as a Batch Macro within a Workflow and is stored within the Workflow.
I understand that having a batch macro available as a separate tool can be very powerful and reduces redundant work. However, very often Batch Macros are set up for a specific workflow only and are of no use for other workflows. The Creation of a Batch Macro in a container will significantly reduce the time to deploy a batch macro and keeps the Macro folder clean of one-time Batch Macros.
Attached a picture of how this could look like
Thanks
Manuel
Hello all, just another little QoL suggestion!
There have been a few occasions recently where I've been adding some Report Text to a Rendered output and have needed to reference the current date. However, when building a quick formula to do this, I've first needed to add a dummy field within a Text Input tool so that the Formula tool doesn't error due to no incoming connection.



I know I can create a branch off from the main dataset and just use that, but for something simple like this, I find it cleaner to isolate and generate it in this way and so it'd be great if - for situations like this - the Formula tool's input anchor was optional (obviously only when using it to create new fields).
There are likely many other examples where you may want to build a simple workflow (or branch of one), starting with a quick field generated within the Formula tool itself. However, just thought I'd raise this with a scenario I've encountered a couple of times recently.
Cheers!
DearAlteryx team and community,
all the best for 2021!
Thank you very much for enhancing the output option from Alteryx Designer to Excel keeping the format.
For a lot of my use cases this is very helpful!
Still, there are some use cases left. In case I want to overwrite a calculated/linked number (e.g. calculated prediction) with the Actual number, it would be very helpful to feed into those cells as well. At the moment Alteryx is doing the job but I receive a lot of Excel Errors (xml errors) and a corupt Excel file when overwriting calculated fields/linked fields.
Is there a chance to extend the current setup for all of those cases?
Thanks and best regards
Chhristoph
I would love to see an option to run only one container without having to disable all others (and tools not in containers).
I've got workflows with MANY different queries/tools each in their own containers and some tools outside of containers. Occasionally I need to run or re-run just one of the containers (usually several times when the datastream contains Crosstab or Transpose tools where some fields/options will not populate until the workflow has previously run). Normally I'd either have to disable all other containers and/or select EVERYTHING that I do not wish to run an add them all to another container that I could then disable. An option to disable everything outside of a specific container would be most welcome and save a lot of time!
- moving or renaming a file after importing it
- deleting a file after importing it
- moving or copying a file after successfully exporting it
- writing a temporary file (i.e. batch file for RunCommand tool), then deleting it when finished
...and now for probably the most trivial request in a long time, but also one of the most annoying things (for me anyway)..........
When viewing a browse window, it's so darn awesome to be able to sort and search. However, it would be even awesomeer (yes, I just made up a word) if when you actually conducted a sort or search, you could make your selection (for sorts) or type in your criteria (for searches) and simply press the "Enter" button on the keyboard and have it do the same thing that selecting "Apply" with the mouse does. This is common Windows functionality and I think should be easy to implement.
When writing an expression in a Formula tool, I love that you can just type an open bracket and suggestions pop up that allow you to auto-fill the rest of the variable name. What I find frustrating, however, is that once you type the open bracket, the highlighted field automatically moves to the one where your mouse is pointing, regardless of if you have moved your mouse or not. I think it makes more sense to always highlight the first field in the list and only take mouse position into account once it has actually moved.
It is hard to describe in just a picture as opposed to a video but essentially I had my mouse below where I was typing in the screenshot below then when I typed the open bracket, the 3rd field listed automatically got selected even though I never moved my mouse.

Cc: @Hollingsworth
When I'm organizing my workflow, sometimes I want to move a whole tool container on the canvas. Currently, the only way to do this is to first find the header then select and drag this. When the ends of the container is off screen, it can be hard to know how much I wanted to move my container to get it where I wanted relative to the other tools around it. I feel like it would be nice to be able to select anywhere on the tool container and drag it around (possibly holding right click and dragging so that current tool selection capabilities aren't hindered).
In the (simplified) images below, you'll see that I want my tool container to vertically align just above the browse tool:

I can't currently see the top of the tool container to move it, though, so I must first navigate to that part of the workflow to select the header.

{kind=link}
The DateTime tool is a great way to convert various string arrangements into a Date/Time field type. However, this tool has two simple, but annoying, shortcomings :
- Convert Multiple Fields: Each DateTime tool only lets you convert one field. Many Alteryx tools (MultiField, Auto Field, etc.) allow you to choose what field(s) are affected by the tool. If I have a database with a large number of string fields all with the same format (such as MM/DD/YYYY), I should be able to use one DateTime tool to convert them all!
- Overwrite Existing Field: The DateTime tool always creates a new field that contains your converted date/time. I ALWAYS have to delete the original string field that was converted and rename the newly created date/time field to match the original string field's name. A simple checkbox (like the "output imputed values as a separate field" checkbox in the Imputation tool) could give the flexibility of choosing to have a separate field (like how it is now) or overwrite the string field with the converted date/time field (keeping the name the same).
Alteryx is overall an amazing data blending software. I recognize that both of these shortcomings can be worked around with combinations of other Alteryx tools (or LOTS of DateTime tools), but the simplicity of these missing features demonstrates to me that this data blending tool is not sufficiently developed. These enhancements can greatly improve the efficiency of date handling in Alteryx.
STAR this post if you dislike the inflexibility of the DateTime tool! Thank you!
- New Idea 377
- Accepting Votes 1,784
- Comments Requested 21
- Under Review 178
- Accepted 47
- Ongoing 7
- Coming Soon 13
- Implemented 550
- Not Planned 107
- Revisit 56
- Partner Dependent 3
- Inactive 674
-
Admin Settings
22 -
AMP Engine
27 -
API
11 -
API SDK
228 -
Category Address
13 -
Category Apps
114 -
Category Behavior Analysis
5 -
Category Calgary
21 -
Category Connectors
252 -
Category Data Investigation
79 -
Category Demographic Analysis
3 -
Category Developer
217 -
Category Documentation
82 -
Category In Database
215 -
Category Input Output
655 -
Category Interface
246 -
Category Join
108 -
Category Machine Learning
3 -
Category Macros
155 -
Category Parse
78 -
Category Predictive
79 -
Category Preparation
402 -
Category Prescriptive
2 -
Category Reporting
204 -
Category Spatial
83 -
Category Text Mining
23 -
Category Time Series
24 -
Category Transform
92 -
Configuration
1 -
Content
2 -
Data Connectors
982 -
Data Products
4 -
Desktop Experience
1,605 -
Documentation
64 -
Engine
134 -
Enhancement
407 -
Event
1 -
Feature Request
218 -
General
307 -
General Suggestion
8 -
Insights Dataset
2 -
Installation
26 -
Licenses and Activation
15 -
Licensing
15 -
Localization
8 -
Location Intelligence
82 -
Machine Learning
13 -
My Alteryx
1 -
New Request
226 -
New Tool
32 -
Permissions
1 -
Runtime
28 -
Scheduler
26 -
SDK
10 -
Setup & Configuration
58 -
Tool Improvement
210 -
User Experience Design
165 -
User Settings
86 -
UX
227 -
XML
7
- « Previous
- Next »
- abacon on: DateTimeNow and Data Cleansing tools to be conside...
-
 TonyaS
on:
Alteryx Needs to Test Shared Server Inputs/Timeout...
TonyaS
on:
Alteryx Needs to Test Shared Server Inputs/Timeout...
-
 TheOC
on:
Date time now input (date/date time output field t...
TheOC
on:
Date time now input (date/date time output field t...
- EKasminsky on: Limit Number of Columns for Excel Inputs
- Linas on: Search feature on join tool
-
MikeA
on:
Smarter & Less Intrusive Update Notifications — Re...
- GMG0241 on: Select Tool - Bulk change type to forced
-
Carlithian
on:
Allow a default location when using the File and F...
- jmgross72 on: Interface Tool to Update Workflow Constants
-
pilsworth-bulie
n-com on: Select/Unselect all for Manage workflow assets
| User | Likes Count |
|---|---|
| 32 | |
| 6 | |
| 5 | |
| 3 | |
| 3 |