Alteryx Designer Desktop Ideas
Share your Designer Desktop product ideas - we're listening!Submitting an Idea?
Be sure to review our Idea Submission Guidelines for more information!
Submission Guidelines- Community
- :
- Community
- :
- Participate
- :
- Ideas
- :
- Designer Desktop: Top Ideas
Featured Ideas
Hello,
After used the new "Image Recognition Tool" a few days, I think you could improve it :
> by adding the dimensional constraints in front of each of the pre-trained models,
> by adding a true tool to divide the training data correctly (in order to have an equivalent number of images for each of the labels)
> at least, allow the tool to use black & white images (I wanted to test it on the MNIST, but the tool tells me that it necessarily needs RGB images) ?
Question : do you in the future allow the user to choose between CPU or GPU usage ?
In any case, thank you again for this new tool, it is certainly perfectible, but very simple to use, and I sincerely think that it will allow a greater number of people to understand the many use cases made possible thanks to image recognition.
Thank you again
Kévin VANCAPPEL (France ;-))
Thank you again.
Kévin VANCAPPEL
I have some fairly long running analytic apps on my private gallery. We have many different users who will run these apps and I would like to send them an email when the app is complete so that they don't have to keep checking back for results.
I came across a few different posts that explained how to use a text input named __cloud:UserId to determine the user id of the person running the app and then to query the MongoDB for that user to retrieve their email address. These posts were very helpful, as I do have it working in my analytic app. However, I tried putting all of this into a macro so that I didn't have to copy/paste every time I needed the current user's email address. Unfortunately, the __cloud:UserId text box does not seem to work if it is in a macro.
Can we set our own Comment tool default preferences? - For me I want to set the text alignment to be "Center" by default, currently it's always "TopCenter" when I open it.

Not sure if any of you have a similar issue - but we often end up bringing in some data (either from a website or a table) to profile it - and then an hour in, you realise that the data will probably take 6 weeks to completely ingest, but it's taken in enough rows already to give us a useful sense.
Right now, the only option is to stop (in which case all the profiling tools at the end of the flow will all give you nothing) and then restart with a row-limiter - or let it run to completion. The tragedy of the first option is that you've already invested an hour or 2 in the data extract, but you cannot make use of this.
It feels like there's a third option - a option to "Stop bringing in new data - but just finish the data that you currently have", which terminates any input or download tools in their current state, and let's the remainder of the data flush through the full workflow.
Hopefully I'm not alone in this need 🙂
Experts -
During development it would be helpful to be able to do the following in both Formula and Filter tools (and perhaps any other tool that uses custom code):
1) Highlight a line or block of code
2) Right click
3) Comment/Uncomment
Easier than manually typing or deleting "//" at every line.
Thanks in advance!
While I strongly support the S3 upload and download connectors, the development of AWS Athena has changed the game for us. Please consider opening up an official support of Athena compute on S3 like support already show for Teradata, Hadoop Hive, MS SQL, and other database types.
Alteryx is brilliant at handling dates and understands them natively. Very often businesses want to analyse money, and in all sorts of ways. In Alteryx if a column contains $123.45 Alteryx thinks it is a string, and one then has to mess around converting it to a number. Alteryx should recognise that anything like $123.45 or €123 or £1,234,567 is actually money and is a number not a string. This could be achieved either by having a money datatype (like MS Access) or if that is too hard, a function that converts a string version of money into a number irrespective of padding, commas or decimal points.
Regards
Mark
It would be extremely useful to quickly find which of my many workflows feed other workflows or reports.
A quick and easy way to do this would be to export the dependencies of a list of workflows in a spreadsheet format. That way users could create their own mapping by linking outputs of one workflow, to inputs of another.
Looking at the simple example below, the Customers workflow would feed the Market workflow.
| Workflow | Dependency | Type |
| Customers | SQL Table 1 | Input |
| Customers | SQL Table 2 | Input |
| Customers | Excel File 1 | Input |
| Customers | Excel File 2 | Input |
| Customers | Excel File 3 | Output |
| Market | Excel File 3 | Input |
| Market | SQL Table 3 | Output |
It would be CRAZY AWESOME if we could get a report like this for all scheduled workflows in the scheduler.
In an enterprise environment, or a reasonably sized BI team - you want a degree of consistency on how workflows look and feel. This increases maintainability; portability; and also increases the safety (because like well structured source-code - it's easier to read, so it's easier to peer-review)
Looking at all the samples provided by Alteryx, they all have a similar template, which makes them very easy to use.
Could we add the capability for larger BI teams to create a default canvas template (or a set of templates) which enforce the company / team's style-guide; layout; and required look-and-feel?
Thank you
Sean
Within the select tool when you have hilighted a set of rows it would be NICE to be able to RIGHT-CLICK for OPTIONS rather than have to move the cursor up to the options to get to choices.
Thanks,
Mark
Many software & hardware companies take a very quantitative approach to driving their product innovation so that they can show an improvement over time on a standard baseline of how the product is used today; and then compare this to the way it can solve the problem in the new version and measure the improvement.
For example:
- Database vendors have been doing this for years using TPC benchmarks (http://www.tpc.org/) where a FIXED set of tasks is agreed as a benchmark and the database vendors then they iterate year over year to improve performance based on these benchmarks
- Graphics card companies or GPU companies have used benchmarks for years (e.g. TimeSpy; Cinebench etc).
How could this translate for Alteryx?
- Every year at Inspire - we hear the stats that say that 90-95% of the time taken is data preparation
- We also know that the reason for buying Alteryx is to reduce the time & skill level required to achieve these outcomes - again, as reenforced by the message that we're driving towards self-service analytics & Citizen-data-analytics.
The dream:
Wouldn't it be great if Alteryx could say: "In the 2019.3 release - we have taken 10% off the benchmark of common tasks as measured by time taken to complete" - and show a 25% reduction year over year in the time to complete this battery of data preparation tasks?
One proposed method:
- Take an agreed benchmark set of tasks / data / problems / outcomes, based on a standard data set - these should include all of the common data preparation problems that people face like date normalization; joining; filtering; table sync (incremental sync as well as dump-and-load); etc.
- Measure the time it takes users to complete these data-prep/ data movement/ data cleanup tasks on the benchmark data & problem set using the latest innovations and tools
- This time then becomes the measure - if it takes an average user 20 mins to complete these data prep tasks today; and in the 2019.3 release it takes 18 mins, then we've taken 10% off the cost of the largest piece of the data analytics pipeline.
What would this give Alteryx?
This could be very simple to administer; and if done well it could give Alteryx:
- A clear and unambiguous marketing message that they are super-focussed on solving for the 90-95% of your time that is NOT being spent on analytics, but rather on data prep
- It would also provide focus to drive the platform in the direction of the biggest pain points - all the teams across the platform can then rally around a really deep focus on the user and accelerating their "time from raw data to analytics".
- A competitive differentiation - invite your competitors to take part too just like TPC.org or any of the other benchmarks
What this is / is NOT:
- This is not a run-time measure - i.e. this is not measuring transactions or rows per second
- This should be focussed on "Given this problem; and raw data - what is the time it takes you, and the number of clicks and mouse moves etc - to get to the point where you can take raw data, and get it prepped and clean enough to do the analysis".
- This should NOT be a test of "Once you've got clean data - how quickly can you do machine learning; or decision trees; or predictive analytics" - as we have said above, that is not the big problem - the big problem is the 90-95% of the time which is spent on data prep / transport / and cleanup.
Loads of ways that this could be administered - starting point is to agree to drive this quantitatively on a fixed benchmark of tasks and data
@LDuane ; @SteveA ; @jpoz ; @AshleyK ; @AJacobson ; @DerekK ; @Cimmel ; @TuvyL ; @KatieH ; @TomSt ; @AdamR_AYX ; @apolly
I love the dynamic rename tool because quite often my headers are in the first row of data in a text file (or sometimes, Excel!).
However, whenever I open a workflow, I have to run the workflow first in order to make the rest of the workflow aware of the field names that I've mapped in the dynamic rename tool, and to clear out missing fields from downstream tools. When a workflow takes a while to run, this is a cumbersome step.
Alteryx Designer should be aware of the field names downstream from the dynamic rename tool, and make them available in the workflow for use downstream as soon as they are added (or when the workflow is initially opened without having been run first).
With more and more enterprises moving to cloud infrastructures and Azure being one of the most used one, there should be support for its authentication service Azure Active Directory (AAD).
Currently if you are using cloud services like Azure SQL Servers the only way to connect is with SQL login, which in a corporate environment is insecure and administrative overhead to manage.
The only work around I found so far is creating an ODBC 17 connection that supports AAD authentication and connect to it in Alteryx.
Please see the post below covering that topic:
Bring back the Cache checkbox for Input tools. It's cool that we can cache individual tools in 2018.4.
The catch is that for every cache point I have to run the entire workflow. With large workflows that can take a considerable amount of time and hinders development. Because I have to run the workflow over and over just to cache all my data.
Add the cache checkbox back for input tools to make the software more user friendly.
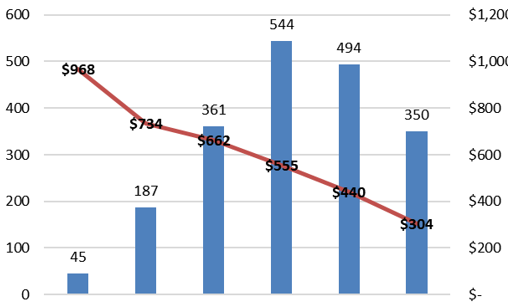{kind=link}
A problem I'm currently trying to solve and feel like I'm spending way too much time on it..
I have a data set which has some data in it from multiple languages, and I only want English values. I was able to get rid of the words with non English letters with a little regular expression and filtering. However, there's some words that do contain all English letters but aren't English. What I'm trying to do is bring in an English dictionary to compare words and see which rows have non English words according to the dictionary. However, this is proving to be a bit harder than I thought. I think I can do it, but it feels like this should be much simpler than it is.
It would be great to have a tool that would run a "spell check" on fields (almost all dictionaries for all languages are available free online). This could also be useful also just for cleaning up open text types of data where people type stuff in quickly and don't re-read it! 🙂
We frequently report on our data by week. However, the DateTimeTrim function (in the Formula Tool and others) does not support this trim type.
Some workarounds have been posted that involve calculating the day of the week and then subtracting it out:
http://community.alteryx.com/t5/Data-Preparation-Blending/Summarize-data-by-the-week/td-p/6002
It would be very helpful to update DateTimeTrim as follows:
- Add a <trim type> of 'week'
- Add an optional parameter for <start of week>
- Default value: 0 (Week beginning Sunday)
- Other values: 1 (Week beginning Monday), 2 (Week beginning Tuesday), etc.
Here's a twist on the iterative macro. Suppose, like a generate rows tool, you could initialize a container to iterate on it's internal processes without having to construct a macro? The container could include anchors for iterations and for output and allow the user to DoWhile inside of the container.
Just a thought....
It would be great if you could select multiple Data Fields in a single Crosstab
For example. I would like to SUM (Methodology) Pet Food Sales (Data Field 1) & Baby Food Sales (Data Field 2) By Store (Grouping Field) By Day of Week (Header field).
Bulk Load for Vertica (especially with the gzip compressed format) is very powerful, I can upload several dozens of millions of rows in a few minutes. Can we have it please?
- New Idea 291
- Accepting Votes 1,791
- Comments Requested 22
- Under Review 166
- Accepted 55
- Ongoing 8
- Coming Soon 7
- Implemented 539
- Not Planned 111
- Revisit 59
- Partner Dependent 4
- Inactive 674
-
Admin Settings
20 -
AMP Engine
27 -
API
11 -
API SDK
220 -
Category Address
13 -
Category Apps
113 -
Category Behavior Analysis
5 -
Category Calgary
21 -
Category Connectors
247 -
Category Data Investigation
79 -
Category Demographic Analysis
2 -
Category Developer
209 -
Category Documentation
80 -
Category In Database
215 -
Category Input Output
645 -
Category Interface
240 -
Category Join
103 -
Category Machine Learning
3 -
Category Macros
153 -
Category Parse
76 -
Category Predictive
79 -
Category Preparation
395 -
Category Prescriptive
1 -
Category Reporting
199 -
Category Spatial
81 -
Category Text Mining
23 -
Category Time Series
22 -
Category Transform
89 -
Configuration
1 -
Content
1 -
Data Connectors
968 -
Data Products
3 -
Desktop Experience
1,551 -
Documentation
64 -
Engine
127 -
Enhancement
343 -
Feature Request
213 -
General
307 -
General Suggestion
6 -
Insights Dataset
2 -
Installation
24 -
Licenses and Activation
15 -
Licensing
13 -
Localization
8 -
Location Intelligence
80 -
Machine Learning
13 -
My Alteryx
1 -
New Request
204 -
New Tool
32 -
Permissions
1 -
Runtime
28 -
Scheduler
24 -
SDK
10 -
Setup & Configuration
58 -
Tool Improvement
210 -
User Experience Design
165 -
User Settings
81 -
UX
223 -
XML
7
- « Previous
- Next »
- Shifty on: Copy Tool Configuration
- simonaubert_bd on: A formula to get DCM connection name and type (and...
-
 NicoleJ
on:
Disable mouse wheel interactions for unexpanded dr...
NicoleJ
on:
Disable mouse wheel interactions for unexpanded dr...
- haraldharders on: Improve Text Input tool
- simonaubert_bd on: Unique key detector tool
- TUSHAR050392 on: Read an Open Excel file through Input/Dynamic Inpu...
- jackchoy on: Enhancing Data Cleaning
- NeoInfiniTech on: Extended Concatenate Functionality for Cross Tab T...
- AudreyMcPfe on: Overhaul Management of Server Connections
-
AlteryxIdeasTea
m on: Expression Editors: Quality of life update
| User | Likes Count |
|---|---|
| 4 | |
| 3 | |
| 3 | |
| 2 | |
| 2 |