Alteryx Designer Desktop Ideas
Share your Designer Desktop product ideas - we're listening!Submitting an Idea?
Be sure to review our Idea Submission Guidelines for more information!
Submission Guidelines- Community
- :
- Community
- :
- Participate
- :
- Ideas
- :
- Designer Desktop: New Ideas
Featured Ideas
Hello,
After used the new "Image Recognition Tool" a few days, I think you could improve it :
> by adding the dimensional constraints in front of each of the pre-trained models,
> by adding a true tool to divide the training data correctly (in order to have an equivalent number of images for each of the labels)
> at least, allow the tool to use black & white images (I wanted to test it on the MNIST, but the tool tells me that it necessarily needs RGB images) ?
Question : do you in the future allow the user to choose between CPU or GPU usage ?
In any case, thank you again for this new tool, it is certainly perfectible, but very simple to use, and I sincerely think that it will allow a greater number of people to understand the many use cases made possible thanks to image recognition.
Thank you again
Kévin VANCAPPEL (France ;-))
Thank you again.
Kévin VANCAPPEL
Currently the simulation sampling tool doesn't accept model objects from time series tools as a model input. It would be beneficial if it could so one could run simulations from Time series output (or a new tool is built to offer this functionality)
The global constants, specifically the user-defined ones (within the Workflow configuration) are a great tool for making quick changes. I would love to be able to include the value of these constants directly within a comment: the Comment tool, the captions for Tool & Control Containers, or the Annotation of individual tools. My immediate use-case would be to clearly show what the constants are set to, directly on the canvas, though there are certainly a lot of other uses as well.
-
Category Documentation
-
Desktop Experience
-
Enhancement
It would be great for the Run Until Selected Tool to be able to used on Browse tools. In complex workflows, it is useful for testing certain parts and investigating all records in the Browse component instead of the subset previewed in the previous tool leading up to the Browse tool.
-
Desktop Experience
-
Enhancement
Hello,
Could there be a way to explore the details of the results window by double-clicking on a value of the Browser profile?
Basically if the profile of a field in the Browser tells me that there are x records meeting that value, could they be selected by double-clicking on that value in the profile? A bit like when you explore the underpinning rows in a pivot table in Excel; if you want to see which records meet the criteria, you double-click on the value.

For example clicking twice either on the label or the count and the specific records would show.
-
Category Input Output
-
Data Connectors
-
Desktop Experience
-
Enhancement
As part of the options of the select tool, it would be really helpful if the 'Change Field type of Highlighted Fields' included the Forced type which would detect for each highlight field, the current type, and change it to the forced version of that type. Currently we need to go through each column to achieve this, and with a lot of columns (that are not consistent across different sheets, so a .yxft is not suitable) this is a massive pain. It seems fairly straight forward to add this as an option called 'forced' or something alongside the other data types
-
Category Preparation
-
Desktop Experience
-
Enhancement

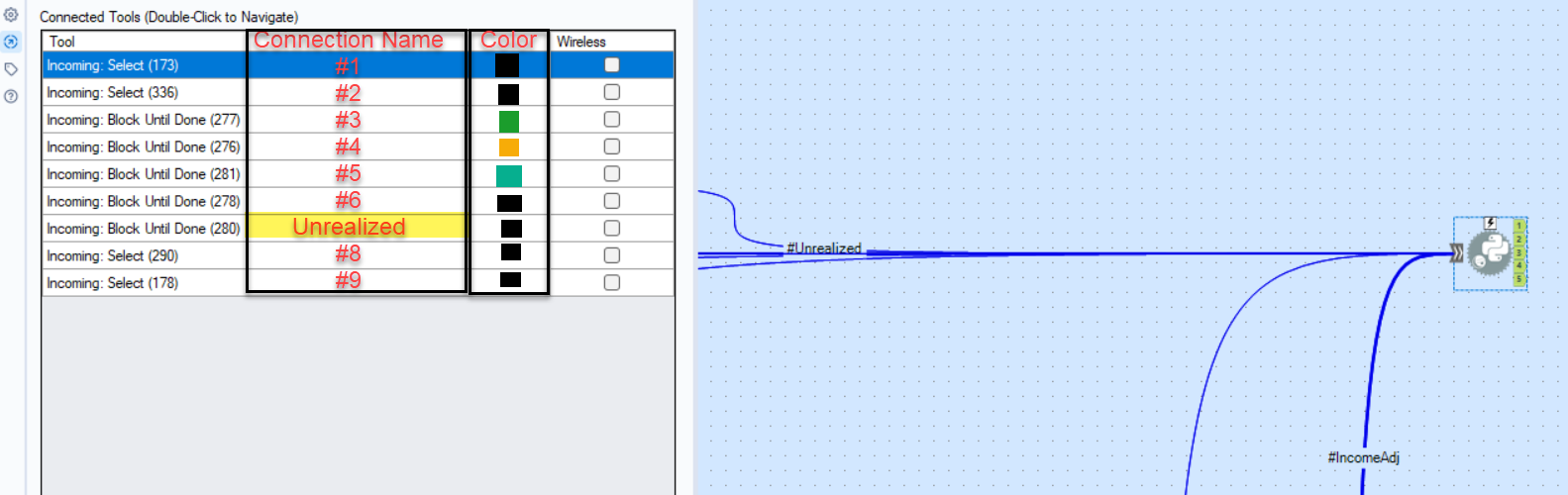
I only have 2023.2, hoping to get 24.2 soon, so I haven't been able to try the newest color feature, but my idea is additional columns in the Navigation panel of a tool to update multiple connection features in one place (names and color at the moment). I'm using Python, and I have a variety of data inputs I would like to be able to easily reference in my code. Currently default names are #1, #2, based on order of connection. Similarly, I know for tools that accept multiple inputs, like Union and Join Multiple, this could also be useful if needing to reorder based on the connection names. I'm also not sure how this ties in to the color feature as described in Connection Configuration, but this could also be a good place to change colors of multiple connections at once instead of clicking into each connection. This would also require this list to allow for multiple selection at the same time, as right now you can't hold shift and select multiple lines.
-
Desktop Experience
-
Enhancement
-
UX
Currently, the Marketplace Add-ons interface when opened within Designer only contains the more significant, Alteryx made tools:

Which is a very useful feature, however if the tool I want to download is not on this limited list (or, I want a particular version), I still need to go through the Marketplace to download this.
It would be great if this functionality had all tools on the Marketplace included - potentially with the option to filter to Alteryx made tools only.
Cheers!
-
Desktop Experience
-
Enhancement
-
Installation
In the 20 years of my career I have built many automations using many tools. Alteryx is one of the best but lacks a key function that many others have. The File Browse Tool and the Folder Browse tool should be able to be configured with default values.
There should be an option under the File Specification that says "Default Location". When the user clicks browse button in the Analytical Interface it should default to opening that location ( eg.. \\ShareDrive\Reports\Finance\ ). If this location in inaccessible by the user or Account running the job then either an error should be thrown and the flow stopped or a default location open as in 2024.2
Users have requested this as when you have a large network browsing to the file you need can be slow and cumbersome. Ideally we should be able set the default location in the Designer to the folder where the file they want "most likely" is. Saving the user time and effort. This same concept applies to Folder Browse.

The funny part about this is when you ask Alteryx Co-Pilot (or ChatGPT, or Microsoft Co-Pilot) how to do this. Even it figures this was a option that exists.

-
Category Interface
-
Desktop Experience
-
Enhancement
Given that the current Iterative type Macro will hold each iteration output in memory, to merge it all at the end of the iterations, wouldn't it make sense to have a checkbox for "Large Data Sets" where each iteration's output is stored to a tmp file, to be merged after the iterations stop?
As it is, holding multiple iterations in memory may often be too much data for a PC, no matter how hefty. By off-loading the memory objects to a tmp file and only holding the currently working iteration in memory, speed and efficiency would be gained.
This is especially critical when using Iterative Macros to cycle through APIs (pagination) and while each individual data pull may be small enough, they quickly grow in memory as each data pull is added to the in-memory object.
-
Category Macros
-
Desktop Experience
-
Enhancement
In CrossTab tool, it have Total Row and Total Column as option.
For Total Row, it work all the sum, count, and avg etc.
but for "Total Column", it only sum (even i not select the sum)
To solved this I suggest to add Total Column for Count, Avg and etc.
version 2024.2


-
Category Transform
-
Desktop Experience
-
Enhancement
Is there a way to update workflow constants in analytic apps using an interface tool?
-
Category Interface
-
Desktop Experience
-
Enhancement
Whenever we upload a workflow in the Gallery, we have to manually unselect, one by one, all the workflow assets in order to avoid them being packaged, because we use absolute UNC paths everywhere: if an asset is packaged, there might be errors due to relative paths
It would save time to have the option to either "Select all" or "Unselect all" in the interface shown in the attachment (Capture.png)
-
Desktop Experience
-
Enhancement
-
User Settings
Additional Dynamic Select Mode for All Native (Non-Macro) Tools with Select Functionality (with or without Data Type Selection)
This is the updated version of an idea I posted a while ago (which only included Multi-Field Formula), and after the release of Alteryx Designer 2025.1, which I found to be very successful from a new tool and functionality perspective, I decided to post about it.
My proposition is to add the Dynamic Select functionality* (at least the Select via a Formula mode) to all native (non-macro) tools in all tool categories that include a Select functionality (as an alternative, where the user would be OK with not being able to also change the field types of the selected fields, such as Join and Append tools, the opposite would apply to Multi-Field Formula, where the user would be able to dynamically select which fields the Multi-Field Formula would be applied to, in addition to changing the data type), including but not limited to (to account for any new tool with a Select functionality that might be added in the future):
Preparation Category
- Auto Field
- Data Cleanse Pro (added in 2025.1)
- Multi-Field Formula
- Multi-Row Formula (for Group By option)
- Rank (for Group By option)
- Record ID (for Group By option)
- Sample (for Group By option)
- Tile (for Group By option)
- Unique
Join Category
- Append Fields
- Find Replace
- Join
- Join Multiple
Transform Category
- Arrange
- Cross Tab
- Make Columns (for Grouping Fields (Optional) option)
- Running Total (for both Group By (Optional) and Create Running Total options)
- Transpose (for both Key Columns and Data Columns options, the tool would generate an error if the Dynamic Select formula written for both options are selecting the same field(s), as the Transpose tool is not supposed to allow it)
- Weighted Average (for Grouping Fields (Optional) option)
In-Database Category
- Select In-DB
Reporting Category
- Layout (for Group By and Per Column Configuration options)
- Table (for Group By and Per Column Configuration options)
Machine Learning Category
- Transformation (for Select Features mode only, as the other two modes with Select functionality (Clean Up Missing Values and One Hot Encoding) require Method and Missing Category Action specification)
Developer Category
- Download (for And values from these fields option present in Headers and Payload tabs)
- Dynamic Rename (for the Select functionality present in Formula mode)
Spatial Category
- Find Nearest
- Spatial Info
- Spatial Match
Data Investigation Category
- Pearson Correlation
Skipping Address and Demographic Analysis categories as they have tools that seem to be using a static input, therefore not requiring a Dynamic Select functionality.
Laboratory Category
- JSON Build (for Grouping Fields (Optional) option)
- Transpose In-DB (with a similar logic to the regular Transpose tool found in Transform category)
*The Dynamic Select functionality added tools that have more than one input anchor (such as Join and Join Multiple) could have new additional fields the users can utilize, such as:
- [Origin] (can have the values "L" or "R" for Join and Append tools)
- [Connection_ID] (can have the values 1, 2, 3 etc. for Join Multiple tool)
- [Unknown] (can have the values "True" or "False" for the Data Columns option of the Transpose tool, or any other tools such as Join that would have the Dynamic or Unknown Columns option as a part of their Select functionality)
-
Desktop Experience
-
Engine
-
Enhancement
-
UX
Hi,
I was wondering if would be great to have something like TEST RUN. Where it would check all settings of the tools.
Example - I have workflows that pull a lot of data, do some calculation and at the end they post to Tableau. It happens from time to time that my Table Token has expired so after running for like 3 hours I am getting error for the Tableau Tool. Or similar situation with output to excel to discovered that I have choose to Create not overwrite the sheet and have to re-run the workflow.
It would save me a lot of time when I could just do a Test Run for all the tools to make sure that everything is set correct and I am good to run the workflow and start pulling down all the data.
Not sure if this is possible but I am pretty sure that I am not the only one with this issue :)
-
Engine
-
Enhancement
Hello,
As of now, you can't choose the DCM connections to synchronize. It's either all or none.

{kind=link}
{kind=link}
However, I have one designer and two servers (Sandbox/Production). Most connections must be common, but not all.
Best regards,
Simon
-
Data Connectors
-
Engine
-
Enhancement
I have to switch to using alternate software anytime I need to input a file where the spatial projection is not recognized by the input tool for a spatial object field.
I would really like to see an option added to the input tool that allows custom designation of a spatial projection. Allowing manually choosing the projection and being able to open a ".prj" (or something similar) for Alteryx to use when ingesting the data.
-
Category Input Output
-
Data Connectors
-
Enhancement
In the regex tool, there is a checkbox called "copy unmatched text to output".
Unfortunately, if you are using regex from within the formula tool, this is not an option. It would be helpful if this could be added as an optional parameter in the regex formula i.e:
REGEX_Replace(String, pattern, replace, icase=1, unmatched=1)
Without this, regex outputs can sometimes be confusing, as string characters not specified by the pattern (unmatched) appear in the output. This confusion would be alleviated with the optional parameter.
-
Category Preparation
-
Desktop Experience
-
Enhancement
As many Alteryx Designer users are already aware, there is an option to connect a tool to multiple tools at once by right clicking on it and selecting View Possible Connections.
I would like to suggest an enhancement for this feature, which I think will make it even easier to connect multiple tools.
Scenario 1
Suppose you drag & dropped many Append tools to existing connections as you realized you needed to add an extra information to your data. For example, a year input from a Text Input tool that is modified by the interface tool. If there were 30 Append tools, you would have to select all those available "ID - Append Fields S" checkboxes one by one.
Scenario 2
You added multiple Input Data tools to canvas but don't want to select them individually to connect them to a single Union tool.
Idea
If there were a group checkbox for each tool category on each side (Output Connections and Input Connections), creating multiple connections would be as easy as clicking on the group checkbox on the Append Fields category on the Input Connections side (for Scenario 1) or clicking on the group checkbox for Input Data category on the Output Connections side (for Scenario 2).
-
Desktop Experience
-
Enhancement
-
UX
Hello,
A very simple idea :
as of today, there are dedicated connectors to Sharepoint, OneDrive and Azure Data Lake.
For all these connectors, the files we can read are limited, very limited : xlsx, csv, yxdb
The location of the storage is not relevant, we should be able to read any already supported file on these locations (like parquet or shp or whatever).
Best regards,
Simon
-
Category Connectors
-
Data Connectors
-
Enhancement
For the Output Tool it would be very beneficial to be able to pass a password in order to populate a password protected Excel spreadsheet. It appears there is a decent amount of interest based on the Community feedback pertaining to the subject.
-
Category Input Output
-
Data Connectors
-
Enhancement
- New Idea 377
- Accepting Votes 1,784
- Comments Requested 21
- Under Review 178
- Accepted 47
- Ongoing 7
- Coming Soon 13
- Implemented 550
- Not Planned 107
- Revisit 56
- Partner Dependent 3
- Inactive 674
-
Admin Settings
22 -
AMP Engine
27 -
API
11 -
API SDK
228 -
Category Address
13 -
Category Apps
114 -
Category Behavior Analysis
5 -
Category Calgary
21 -
Category Connectors
252 -
Category Data Investigation
79 -
Category Demographic Analysis
3 -
Category Developer
217 -
Category Documentation
82 -
Category In Database
215 -
Category Input Output
655 -
Category Interface
246 -
Category Join
108 -
Category Machine Learning
3 -
Category Macros
155 -
Category Parse
78 -
Category Predictive
79 -
Category Preparation
402 -
Category Prescriptive
2 -
Category Reporting
204 -
Category Spatial
83 -
Category Text Mining
23 -
Category Time Series
24 -
Category Transform
92 -
Configuration
1 -
Content
2 -
Data Connectors
982 -
Data Products
4 -
Desktop Experience
1,605 -
Documentation
64 -
Engine
134 -
Enhancement
407 -
Event
1 -
Feature Request
218 -
General
307 -
General Suggestion
8 -
Insights Dataset
2 -
Installation
26 -
Licenses and Activation
15 -
Licensing
15 -
Localization
8 -
Location Intelligence
82 -
Machine Learning
13 -
My Alteryx
1 -
New Request
226 -
New Tool
32 -
Permissions
1 -
Runtime
28 -
Scheduler
26 -
SDK
10 -
Setup & Configuration
58 -
Tool Improvement
210 -
User Experience Design
165 -
User Settings
86 -
UX
227 -
XML
7
- « Previous
- Next »
- abacon on: DateTimeNow and Data Cleansing tools to be conside...
-
 TonyaS
on:
Alteryx Needs to Test Shared Server Inputs/Timeout...
TonyaS
on:
Alteryx Needs to Test Shared Server Inputs/Timeout...
-
 TheOC
on:
Date time now input (date/date time output field t...
TheOC
on:
Date time now input (date/date time output field t...
- EKasminsky on: Limit Number of Columns for Excel Inputs
- Linas on: Search feature on join tool
-
MikeA
on:
Smarter & Less Intrusive Update Notifications — Re...
- GMG0241 on: Select Tool - Bulk change type to forced
-
Carlithian
on:
Allow a default location when using the File and F...
- jmgross72 on: Interface Tool to Update Workflow Constants
-
pilsworth-bulie
n-com on: Select/Unselect all for Manage workflow assets
| User | Likes Count |
|---|---|
| 32 | |
| 5 | |
| 4 | |
| 3 | |
| 2 |