Alteryx Designer Desktop Ideas
Share your Designer Desktop product ideas - we're listening!Submitting an Idea?
Be sure to review our Idea Submission Guidelines for more information!
Submission Guidelines- Community
- :
- Community
- :
- Participate
- :
- Ideas
- :
- Designer Desktop: Hot Ideas
Featured Ideas
Hello,
After used the new "Image Recognition Tool" a few days, I think you could improve it :
> by adding the dimensional constraints in front of each of the pre-trained models,
> by adding a true tool to divide the training data correctly (in order to have an equivalent number of images for each of the labels)
> at least, allow the tool to use black & white images (I wanted to test it on the MNIST, but the tool tells me that it necessarily needs RGB images) ?
Question : do you in the future allow the user to choose between CPU or GPU usage ?
In any case, thank you again for this new tool, it is certainly perfectible, but very simple to use, and I sincerely think that it will allow a greater number of people to understand the many use cases made possible thanks to image recognition.
Thank you again
Kévin VANCAPPEL (France ;-))
Thank you again.
Kévin VANCAPPEL
in our organization people are moving away from network drives to BOX for file repository and they needs to use to connect to BOX using Alteryx as an Input and Output platform where they should be able to access files to read and write.
Currently few of the users are able to use the BOX as a repository using BOX Sync tool (Map BOX as a network drive) but that is not at all useful when they try to save into a gallery and run or schedule on the gallery. A connector for BOX will be of great help.
Hello all,
We all have experienced these last years the now famous concept of hide/unhide password :
Here a few examples of it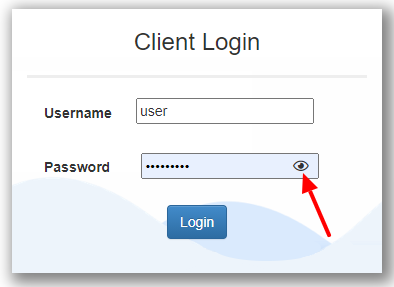
I would like this exact principle everywhere we have a password on Alteryx.
Best regards,
Simon

Hello all,
So, right now, we have two very separated products : Alteryx Designer and Alteryx Designer Cloud. But what if you want to go from Alteryx Designer on your desktop to the cloud ?
well, you will have to rewrite every single workflow because you can't publish or import your current workflow on Alteryx Designer Cloud. You cannot export Designer Cloud workflow to Alteryx Designer on Desktop either.
This is a huge limitation on cloud implementation and sells and the ONLY product I know that's not compatible between on-premise and cloud.
Please Alteryx, this is a no-brainer situation if you want to convince your customers !
Best regards,
Simon
Hello all,
ADBC is a database connection standard (like ODBC or JDBC) but specifically designed for columnar storage (so database like DuckDB, Clickhouse, MonetDB, Vertica...). This is typically the kind of stuff that can make Alteryx way faster.
more info in https://arrow.apache.org/blog/2023/01/05/introducing-arrow-adbc/
Here a benchmark made by the guys at DuckDB : 38x improvement
https://duckdb.org/2023/08/04/adbc.html

Best regards,
Simon
Today, there is an checkbox to "Disable All Tools that Write Output" within the Runtime settings for a workflow. Setting this option requires at least 3 clicks:
- Click on the canvas
- Click the "Runtime" tab in the Configuration pane
- Click the checkbox
Could a keyboard shortcut be added for this? I've spoken to several users who leverage this feature and, while it is already a time saver, it seems helpful enough where a keyboard shortcut is warranted.
Today, I am able to take an excel file from a folder and drag it onto the canvas, which automatically creates an Input Data tool.
I would like to be able to drag an excel file right from outlook to do the same!
Hello,
It's nice to have this OpenAI Connector but it seems it must be the default OpenAI URL. In my company, we use OpenAI on an Azure instance and I'm unable to connect to it.
(by the way, I know pre-sales teams have developed lot of connectors for fireworks, mistral, etc.. it would be very cool to have it available).
Best regards,
Simon
I can't even count how often I looked at an Excel, CSV or even YXDB file, where I KNEW that it was generated by Alteryx, but I couldn't remember the workflow. Currently, I have to simply go through all workflows I ever build and see if I can find it.
Theoretically, I could use a text-search across all workflows and see if I can find the output names - problem here: Most of my output filenames are generated dynamically on the run.
It would be amazing if Alteryx could simply write the Workflow name (maybe even path) into the metadata of a file.

(Screenshot from Google, as my os is set to German)
How about, we write "This file was created with by "Create Controlling Reports.yxmd on 2023-02-06 with Alteryx Designer 2021.4.298434" in the field 'Comments'?
This would make it extremely easy to find what workflow the file generated. I think it would be an option to talk about "filepath" instead of filename, but the filepath could include the local machine name, which might include GDPR information.
@Community: Is there any additional information that you'd like to see in the metadata?
Best
Alex
I think I'm liking the new UI, but I think it's necessary to bring back save, undo and re-do buttons....
1. Frequent saving of workflows is crucial and not everyone uses keyboard shortcuts
2. The ability to undo (lots) of changes is a key part of iterating and rapidly building workflows in Alteryx and again not everyone uses keyboard shortcuts to do this.
Looks like there's potentially space to add this to the right of 'help' (I suspect this might be technically quiet difficult) or to the left of 'run', 'schedule' and 'active documents' as seen in the image below.
Out of interest, where has the 'documents' terminology come from?

Hello,
Just like Monetdb or Vertica, Clickhouse is a column-store database, claiming to be the fastest in the world. It's available on Cloud (like Snowflake), linux and macos (and here for free, it's open-source). it's also very well ranked in analytics database https://db-engines.com/en/system/ClickHouse and it would be a good differenciator with competitors.
https://clickhouse.com/
it has became more popular than Greenplum that is supported : (black snowflake, red greenplum, orange clickhouse)


Best regards,
Simon
Hello all,
As you may know, Alteryx use the Active Query Builder component. However this component itself evolves with cool new features :
https://www.activequerybuilder.com/blog/2018-04-28-much-faster-visual-sql-query-building-in-the-new-...
You can also try the online demo
https://www.activequerybuilder.com/

Best regards,
Simon
Hello,
As of today, DCM is great to store credentials. But once we want to dive deeper in technicity, like using macros or Applications, it's really bad. One of the things I hate is that we can't retrieve any informations from the DCM connection, just the id. Not good for logs, really bad for understanding and have some conditional logic related to connection type or name.
Here an example


Nice, I managed to retrieve an id but I have no idea of what it means : what kind of connection? what's name?
Best regards,
Simon

I’ve been using the Regex tool more and more now. I have a use case which can parse text if the text inside matches a certain pattern. Sometimes it returns no results and that is by design.
Having the warnings pop up so many times is not helpful when it is a genuine miss and a fine one at that.
Just like the Union tool having the ability to ignore warnings, like Dynamic Rename as well, can we have the ignore function for all parse tools?
That’s the idea in a nutshell.
Hello,
Here is the proposal about an issue that I face frequently at work.
Problem Statement -
Frequent failure of workflows that have either been scheduled or run manually on server because the excel input file is sometimes open by another user or someone forgot to close the file before going out of office or some other reason.
Proposed Solution -
The Input/Dynamic Input tools to have the ability to read excel files even when it is open so that the workflows do not fail which will have a huge impact in terms of time savings and will avoid regular monitoring of the scheduled workflows.
The Join Tool tells you which records did not match (Left and Right) but it does not tell you what fields it did not match on. This could quickly help the analyst determine which fields they need to look into to determine why there are unmatched records. When joining on 5+ fields it becomes difficult to determine why some records did not match without manually inspecting each record which is time consuming. The column title could be: Unmatched Field(s) and the values should be concatenated separated by commas.
I've seen this question before and have run into it myself. I'd like to see a new tool that would allow a developer (of a workflow) to choose a path of logic based upon criteria known only during the execution of a module.
If LEFT INPUT Count of records < 10,000 THEN Path1 (e.g. use a calgary join)
ELSE Path 2 (e.g. use a standard join)
endif
Thanks,
Mark
As per a recent discussion (https://community.alteryx.com/t5/Alteryx-Designer-Discussions/Geopackages-Can-Alteryx-Open-GeoPackag...), please add the GeoPackage datatype to the Input tool.
For reference, the open-source project ogr2ogr has this functionality. (https://gdal.org/programs/ogr2ogr.html)
Thanks!
Hello all,
Here the issue : when you have a lot of tables, the Visual Query Builder can be very slow. On my Hive Database, with hundreds of tables, I have the result after 15 minutes and most of the time, it crashes, which is clearly unusable.
I can change the default interface in the Visual Query Builder tool but for changing this setting, I need to load all the tables in the VQB tool.
I would like to set that in User Settings to set it BEFORE opening the Visual Query Builder.

{kind=link}
Best regards,
Simon
Hello all,
According to wikipedia https://en.wikipedia.org/wiki/Materialized_view
In computing, a materialized view is a database object that contains the results of a query. For example, it may be a local copy of data located remotely, or may be a subset of the rows and/or columns of a table or join result, or may be a summary using an aggregate function.
The process of setting up a materialized view is sometimes called materialization.[1] This is a form of caching the results of a query, similar to memoization of the value of a function in functional languages, and it is sometimes described as a form of precomputation.[2][3] As with other forms of precomputation, database users typically use materialized views for performance reasons, i.e. as a form of optimization.
So, I would like to create that in Alteryx, for obvious performance reasons in some use cases.
This is not a duplicate of https://community.alteryx.com/t5/Alteryx-Designer-Desktop-Ideas/In-DB-Create-View/idi-p/157886
Best regards,
Simon
Hello all,
According to wikipedia :
https://en.wikipedia.org/wiki/Embedded_database
An embedded database system is a database management system (DBMS) which is tightly integrated with an application software; it is embedded in the application.
It's often like a single file/dll that you can use inside an application without the user having to connect (or at least to configure it) to it (it's all done inside the application). So, it's widely portable.
Why it does matter ?
As of today, there is not a single example of in database workflow because all the supported databases need the user to:
1/install an odbc driver (most of time, he won't have the rights to do so)
2/configure an odbc connection (sometimes, he doesn't have the rights to)
3/configure a connection on Alteryx (ok, he can)
So it requires IT action, which can be pretty long (in ùany organization, it requires several weeks !!). And even with all of that,the users must be granted privilege to access database and the customer need to develop its own examples and write its own specific documentation.
Well, this is not efficient.
What I suggest is Alteryx to use one of embedded database for training support/one tool examples. SQLlite seems good, maybe a more analytics oriented (like DuckDB ) would be more efficient.
The requirement are, I think, the following :
-OpenSource and free
-Fast
-SQL compliant
-With a bulk load ability
Best regards,
Simon
- New Idea 367
- Accepting Votes 1,784
- Comments Requested 21
- Under Review 178
- Accepted 47
- Ongoing 7
- Coming Soon 13
- Implemented 550
- Not Planned 107
- Revisit 56
- Partner Dependent 3
- Inactive 674
-
Admin Settings
22 -
AMP Engine
27 -
API
11 -
API SDK
226 -
Category Address
13 -
Category Apps
113 -
Category Behavior Analysis
5 -
Category Calgary
21 -
Category Connectors
251 -
Category Data Investigation
79 -
Category Demographic Analysis
3 -
Category Developer
215 -
Category Documentation
82 -
Category In Database
215 -
Category Input Output
654 -
Category Interface
245 -
Category Join
107 -
Category Machine Learning
3 -
Category Macros
155 -
Category Parse
77 -
Category Predictive
79 -
Category Preparation
401 -
Category Prescriptive
2 -
Category Reporting
202 -
Category Spatial
83 -
Category Text Mining
23 -
Category Time Series
24 -
Category Transform
92 -
Configuration
1 -
Content
2 -
Data Connectors
981 -
Data Products
3 -
Desktop Experience
1,598 -
Documentation
64 -
Engine
134 -
Enhancement
400 -
Event
1 -
Feature Request
218 -
General
307 -
General Suggestion
8 -
Insights Dataset
2 -
Installation
26 -
Licenses and Activation
15 -
Licensing
14 -
Localization
8 -
Location Intelligence
82 -
Machine Learning
13 -
My Alteryx
1 -
New Request
223 -
New Tool
32 -
Permissions
1 -
Runtime
28 -
Scheduler
26 -
SDK
10 -
Setup & Configuration
58 -
Tool Improvement
210 -
User Experience Design
165 -
User Settings
85 -
UX
227 -
XML
7
- « Previous
- Next »
-
 TonyaS
on:
Alteryx Needs to Test Shared Server Inputs/Timeout...
TonyaS
on:
Alteryx Needs to Test Shared Server Inputs/Timeout...
-
 TheOC
on:
Date time now input (date/date time output field t...
TheOC
on:
Date time now input (date/date time output field t...
- EKasminsky on: Limit Number of Columns for Excel Inputs
- Linas on: Search feature on join tool
-
MikeA
on:
Smarter & Less Intrusive Update Notifications — Re...
- GMG0241 on: Select Tool - Bulk change type to forced
-
Carlithian
on:
Allow a default location when using the File and F...
- jmgross72 on: Interface Tool to Update Workflow Constants
- Pilsner on: Select/Unselect all for Manage workflow assets
-
TheOC
on:
Dynamic Select Everywhere
| User | Likes Count |
|---|---|
| 24 | |
| 9 | |
| 5 | |
| 4 | |
| 4 |