Alteryx Designer Desktop Ideas
Share your Designer Desktop product ideas - we're listening!Submitting an Idea?
Be sure to review our Idea Submission Guidelines for more information!
Submission Guidelines- Community
- :
- Community
- :
- Participate
- :
- Ideas
- :
- Designer Desktop
Featured Ideas
Hello,
After used the new "Image Recognition Tool" a few days, I think you could improve it :
> by adding the dimensional constraints in front of each of the pre-trained models,
> by adding a true tool to divide the training data correctly (in order to have an equivalent number of images for each of the labels)
> at least, allow the tool to use black & white images (I wanted to test it on the MNIST, but the tool tells me that it necessarily needs RGB images) ?
Question : do you in the future allow the user to choose between CPU or GPU usage ?
In any case, thank you again for this new tool, it is certainly perfectible, but very simple to use, and I sincerely think that it will allow a greater number of people to understand the many use cases made possible thanks to image recognition.
Thank you again
Kévin VANCAPPEL (France ;-))
Thank you again.
Kévin VANCAPPEL
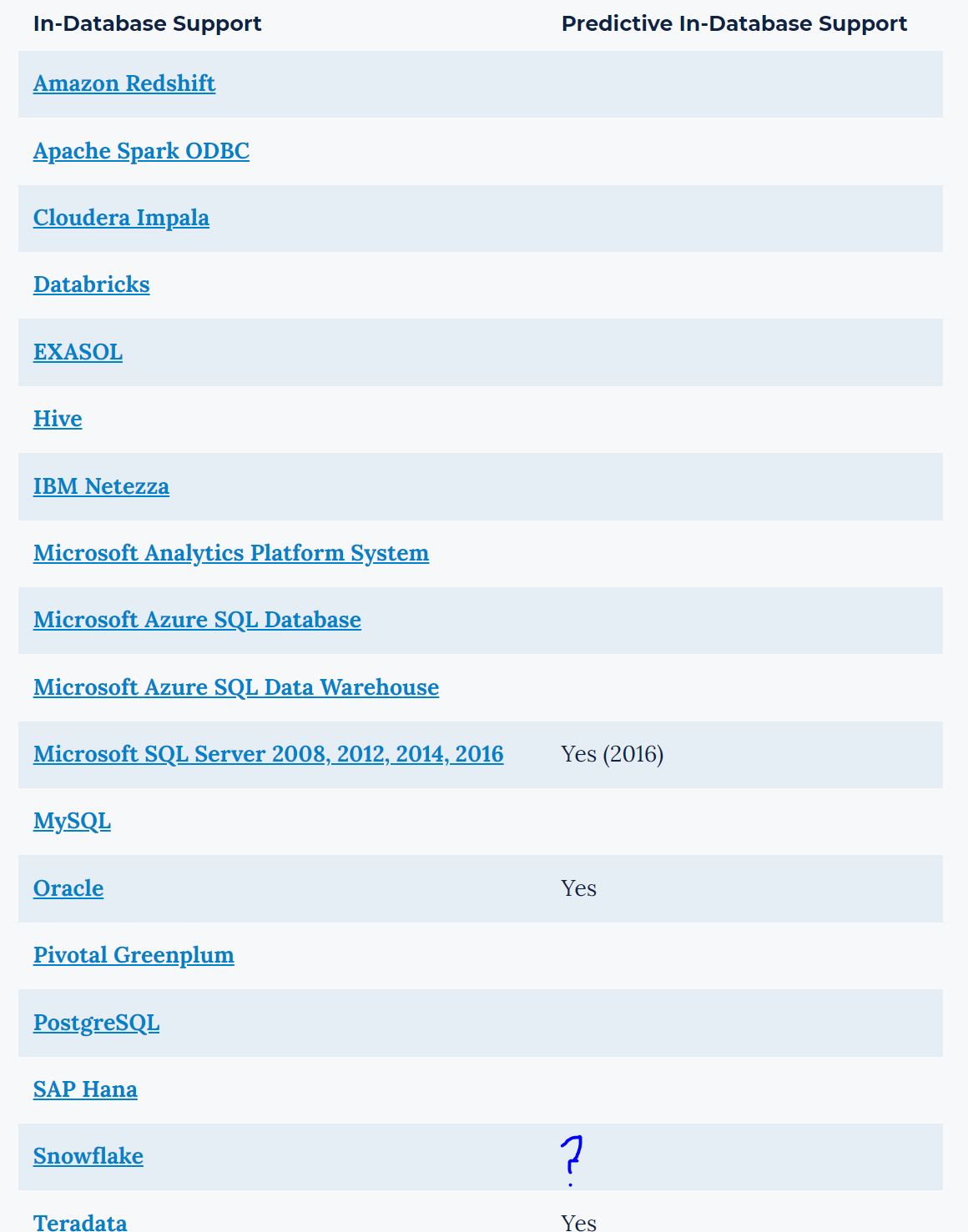
Hi Alteryx,
Can we get the R tools/models to work in database for SNOWFLAKE.
In-Database Overview | Alteryx Help
I understand that Snowflake currently doesn't support R through their UDFs yet; therefore, you might be waiting for them to add it.
I hear Python is coming soon, which is good & Java already available..
However, what about the ‘DPLYR’ package? https://db.rstudio.com/r-packages/dplyr/
My understanding is that this can translate the R code into SQL, so it can run in-DB?
Could this R code package be appended to the Alteryx R models? (maybe this isn’t possible, but wanted ask).
Many Thanks,
Chris
Alternative data sources namely #altdata are key for enriching data. One source is social media.
I believe Alteryx lacks in social media analytics.
- I would like to propose a Instagram connector...
- Crawl comments, tags(useful for text analytics)
- Impression and likes... (time-series data)
If you are into #media, #advertising, #marketing analytics, #influencer analytics please support the idea by seconding...
https://www.instagram.com/developer/authorization/ is the link for the graph API updated after the latest acebook scandal... now fixed...




It seems that there is good value in a "SuperCleanup" tool that could take commonly used ways of writing information and cleaning this up automatically. This would work well if the tool reviewed the data in the column, and made a recommendation about the cleanup to apply. The tool could cleanup the data; and then pop any non-conforming values into a separate column for you to explictly clean up.
For example:
- 01 Jan 2015: this can be automatically cleaned up into a date
- 11:15 pm: this can be cleaned up into a time
- 40.7128° N, 74.0060° W; or 40° 43' 50.1960'' N and 73° 56' 6.8712'' W: Both could be auto-converted to a centroid
- $ 55.20 or £2,000,000.00 can be automatically converted to currency
- India; United States; Mongolia - can be automatically cleaned up as a country (there are only about 200 or so in the world, so it's a very finite list)
- NY; AZ; MI; can be cleaned up as US states
NOTE: if we make this extensible -then companies can auto cleanup SKUs; or location codes; etc
There are dozens of simple cleanups like this that we could add - which would each relieve BI people from the drudgery of having to clean these up each time themselves.
In working through challenge 77 it became apparent that here are a few useful formulae that would help with work like this:
OffsetFromPosition
Input: Point; Bearing; Distance; Units
Output: New point
Degrees to DMS:
Input: Degrees as floating point
Output: string with Degrees; minutes & Seconds
DMS to Degrees:
Inverse of the above
Support richer copy/paste functionality within the text input tools. Specifically allowing multiple records to be pasted at one time when bringing in lists from an unsupported file sources.
Currently when multiple rows or cells are selected and copied.

Only 1 value is copied into the text input record:

Adding and selecting multiple rows results the same - only 1 record pasted.

Other applications I work in reguarly utilize right-click menus. Sometimes those menus seem annoying, but in working with Alteryx, I realize it’s actually quite smart because it eliminates unnecessary wrist movement. In the screenshot below, I have highlighted a bunch of fields. 
Can we get a more robust read.Alteryx function for mode="data.frame"? If it is reading the stream as a data frame, can we have the option stringsAsFactors = FALSE?
I am getting tripped up a lot because the code will execute in R Studio, but will get mysterious behaviours when it runs within the R Tool. I am manually converting variables to character strings in my R Tool code which I don't have to do in R Studio. However, I'm not a highly detail oriented R developer, so I will miss variable data type conversions and have spent a lot of time going down the wrong path. Also, It makes it difficult to maintain two different scripts for the same routine.
I have started using the glimpse() function in R Tool code, to help catch some data conversions since it writes the output in the message log.
Rob Campanell
The Remove Null Rows feature added to the Data Cleansing tool is really nice, however it doesn't work for a common use case for us where we have key metadata field(s) added to the data stream that make rows not null so we'd like to be able to ignore or exclude one or more fields from the Remove Null Rows output.
Here's a use case starting with an Excel file with multiple tabs where each tab holds the records for a different Province:

Note that the 2nd record in Southern is entirely empty, so this is the record that we'd like to remove using the Data Cleansing tool.
Since the Province name is only in the worksheet name (and not in the data) I'm using a Dynamic Input tool with the "Output File Name as Field" to include the worksheet name so I can parse it out later. So the output of the Dynamic Input looks like this:

With the FileName field populated the entire row is not Null and therefore the Remove Null Rows feature of the Data Cleansing tool fails to remove that record:

Therefore what we'd like is when we're using the Remove null rows feature in the Data Cleansing tool to be able to choose field(s) to ignore or exclude from that evaluation. For example in the above use case we might tick the "FileName" checkbox to exclude it and then that 2nd row in Southern would be removed from the data.
There are workarounds to use a series of other tools (for example multi-field formula + filter + select) to do this, so extending the Data Cleansing tool to support this feature is a nice to have.
I've attached the sample packaged workflow used to create this example.
Currently, when multiple tabs are created in the Interface Designer, Alteryx will require the user to click through all tabs before running the app. Many times, extra tabs are there for advanced settings that may confuse the average user.

I propose a check box in the Tab Configuration to allow the tab to be a "background, or silent" tab, that is not clicked through in the process of running the app.
Before Designer 2019.4 there was a "bug" in the workflow statistics collection that under the "SampleModule" data from the UsageGallery collection the name of the workflow run from within Designer was available. We used that information to determine the common workflows run in our community as well as generating a measure of community growth. The "bug" was removed in 2019.4 and now we can only determine the number of runs, but not the number of distinct workflows that were run. This idea to do return the workflow name run to the information stored in the Mongo database.

I understand that Server and Designer + Scheduler versions have the option to "cancel workflows running longer than X”.
I'd like to see that functionality in the desktop edition as well.
Dynamic macros that fetch the current version at every run time vs storing a static copy of the macro with the workflow at publish time are challenging to pull off using shared drives.
This suggestion is to store dynamic macros in the gallery and secure their use with collections.
Right click + "Insert After" and Right click + "Paste After" should behave the same. In the picture below I show the two cases. Currently, the "Insert After" option inserts a tool between the selected tool and the tools after it. The "Paste After" creates a new branch with the pasted tool. I think the "Paste After" should behave the same as the "Insert After": paste the tool on the existing branches. In case we want to create a new branch, we will paste the tool and connect a new branch to it.

1) A single tool that I want to connect to several tools (e.g. an input connecting to a number of selects)
2) Several tools that I want to connect to a single tool (e.g. several inputs connecting to a single union tool)
The current interface requires that I establish these connections by connecting the tools individually. It would be great to have the ability to have a right-click option. Simplistically, it might work something like this...
1) Select the tools that you want connected to a single tool (e.g. all the selects); Right-click; Get connection from Tool...{drop down list}
2) Select the tools that you want to get their connection from a single tool (e.g. all the inputs); Right-click; Connect to Tool...{drop down list}
Alteryx creates a Livy Session when connecting to Spark Direct

{kind=link}
I just want to identify easily the session.
While exporting a report to Excel via the Table/Layout/Render tools, it would be helpful to have the ability to manually adjust the size of specific columns within the report table.
Currently, Alteryx auto-corrects the column widths based on the data in the columns and the selected paper size, even if you select specific column widths using the Table tool. This is a great feature for reporting, however in my use-case my output report contains two blank columns which will be manually edited by my team. Because these two "manual update" columns are blank in Alteryx, the column widths on the output are quite small compared to the other columns, and this will require manual column width formatting within the Excel sheet to both accommodate the (often lengthy) manual updates that will be entered into these two columns, and to keep the report within the paper size parameters.
Thanks!
Taryn
The Download tool is so much more than Downloads. Think about the situation where you are using the Download tool to upload invoices and try explaining that to co-workers. "Oh yes - I'm going to implement the API to upload the invoices using the Alteryx download tool..." Could we call it the Curl tool or something?
When you add a tool in the canvas, the annotation is automatically set (for example the formula, or connection configuration etc). You can then customize the annotation text in the "Annotation" tool's tab. But sometimes it can be useful to revert to the "automatic" annotation, and it doesn't seem possible once you set it to something different.
Apparently there is currently no way to reset a tool's annotation text to the automatic value.
I've found a way to do it by editing the xml content of the file : as far as I know you just have to delete the <AnnotationText>[...]</AnnotationText> tag and reload the file, and the annotation gets back to the default "automatic" value, which is still present in the <DefaultAnnotationText> tag.
I think a simple button in the tool's annotation tab to reset it would be nice.
Thank you!
I enjoy using Alteryx. It saves me a lot of time compared to manually writing scripts. But one of my frustrations is the lack of 'intelligence' in the IDE. Please make it so that if I change a name of a column in a select tool or a join, every occurence of that variable/column in selects, summarises, formulae and probably all tools downstream of the select tool renames as well. In other IDEs I believe this is called refactoring. It doesn't seem like an big feature to make, it would save enormous amounts of time and would make me very happy.
While we're on the 'intelligence' of the IDE, there is a small, easily fixable bug. When I have a variable with spaces in the middle, for example, 'This is my column name', and start writing in the code field "[Thi" then the drop downbox suggests "[This is my column name]". All good so far. But if I get a little further in the variable name, and write instead "[This i", then the dropdown box suggests "[This is my column name]", and I click this, the result is this: "[This [This is my column name]". Alternatively, I could write "[This is my col" and the result would be "[This is my [This is my column name]". Clearly this could be avoided by my using column names with underscores or hyphens; but I wanted to highlight to you the poor functionality here.
Kind regards,
Ben Hopkins
I think it would be really good if we have the option to cache data for few days, as currently cached data gets deleted when you close the workflow.
It’s useful to catch data when developing reports with input data from data warehouses or big data platforms , as sometimes it can takes a while to extract the data.
If we have the option to cache data for few days or delete when it’s not required anymore, it can save a lot of time, the next time when you open the workflow to complete the development or make changes to your workflow.
- New Idea 301
- Accepting Votes 1,790
- Comments Requested 22
- Under Review 168
- Accepted 54
- Ongoing 8
- Coming Soon 7
- Implemented 539
- Not Planned 111
- Revisit 59
- Partner Dependent 4
- Inactive 674
-
Admin Settings
20 -
AMP Engine
27 -
API
11 -
API SDK
222 -
Category Address
13 -
Category Apps
113 -
Category Behavior Analysis
5 -
Category Calgary
21 -
Category Connectors
247 -
Category Data Investigation
79 -
Category Demographic Analysis
2 -
Category Developer
211 -
Category Documentation
80 -
Category In Database
215 -
Category Input Output
646 -
Category Interface
242 -
Category Join
105 -
Category Machine Learning
3 -
Category Macros
154 -
Category Parse
76 -
Category Predictive
79 -
Category Preparation
395 -
Category Prescriptive
1 -
Category Reporting
199 -
Category Spatial
81 -
Category Text Mining
23 -
Category Time Series
22 -
Category Transform
89 -
Configuration
1 -
Content
1 -
Data Connectors
969 -
Data Products
3 -
Desktop Experience
1,558 -
Documentation
64 -
Engine
127 -
Enhancement
348 -
Feature Request
213 -
General
307 -
General Suggestion
6 -
Insights Dataset
2 -
Installation
24 -
Licenses and Activation
15 -
Licensing
13 -
Localization
8 -
Location Intelligence
80 -
Machine Learning
13 -
My Alteryx
1 -
New Request
209 -
New Tool
32 -
Permissions
1 -
Runtime
28 -
Scheduler
24 -
SDK
10 -
Setup & Configuration
58 -
Tool Improvement
210 -
User Experience Design
165 -
User Settings
81 -
UX
223 -
XML
7
- « Previous
- Next »
- nkmcn on: Auto rename fields
- Shifty on: Copy Tool Configuration
- simonaubert_bd on: A formula to get DCM connection name and type (and...
-
 NicoleJ
on:
Disable mouse wheel interactions for unexpanded dr...
NicoleJ
on:
Disable mouse wheel interactions for unexpanded dr...
- haraldharders on: Improve Text Input tool
- simonaubert_bd on: Unique key detector tool
- TUSHAR050392 on: Read an Open Excel file through Input/Dynamic Inpu...
- jackchoy on: Enhancing Data Cleaning
- NeoInfiniTech on: Extended Concatenate Functionality for Cross Tab T...
- AudreyMcPfe on: Overhaul Management of Server Connections