Alteryx Designer Desktop Ideas
Share your Designer Desktop product ideas - we're listening!Submitting an Idea?
Be sure to review our Idea Submission Guidelines for more information!
Submission Guidelines- Community
- :
- Community
- :
- Participate
- :
- Ideas
- :
- Designer Desktop: Hot Ideas
Featured Ideas
Hello,
After used the new "Image Recognition Tool" a few days, I think you could improve it :
> by adding the dimensional constraints in front of each of the pre-trained models,
> by adding a true tool to divide the training data correctly (in order to have an equivalent number of images for each of the labels)
> at least, allow the tool to use black & white images (I wanted to test it on the MNIST, but the tool tells me that it necessarily needs RGB images) ?
Question : do you in the future allow the user to choose between CPU or GPU usage ?
In any case, thank you again for this new tool, it is certainly perfectible, but very simple to use, and I sincerely think that it will allow a greater number of people to understand the many use cases made possible thanks to image recognition.
Thank you again
Kévin VANCAPPEL (France ;-))
Thank you again.
Kévin VANCAPPEL
The "Browse HDFS" for the Spark Direct connection does not allow to specify a File Format at "ORC". Could you please add these feature?

I find that to do a simple concatenation of multiple fields, it takes multiple tools where it seems one would suffice. For example, if I had an address parsed into multiple fields (House Number, Street, Apt, City, State, Zip Code, Country), to combine these into a single address field, I'd have two options: Formula that manually adds each field with +' '+ in between each field, which is a lot of typing and selecting...Or Transpose data and then Summarize (concatenating) the values field with a space delimiter between each record.
Seems to me that a simpler solution would be a concatenate tool that might look and feel much like the Select tool, allowing you to choose a name for your concatenated string, input a delimiter, select the fields to concatenate, and re-order them within the tool. Bonus if it automatically converted everything to string fields (or at least allows you to designate whether you want to concatenate all your fields as numbers or strings, and then translates accordingly). Extra bonus if you also had the option to put a different delimiter after every field...
Not a super complex thing to do this task with the given tools, but it does seem like a fairly straightforward add that would likely save a whole bunch of folks at least a few minutes here and there.
I would like to see a way to partially execute a workflow (specifically for an App) for the purposes of allowing user to make selections based on a dynamic data flow.
Ex:
1. Database Selection Interface
Click Next
2. Select from available columns to pass through to the output file.
Click Next
3. Pick from selected fields which fields should be pivoted.
Output file and complete run time
This was a simple example to explain a case, but the most common use I could see is for APIs.
With complex ETL jobs, we often have a very similar ETL process that needs to be run for multiple different tables (with different surrogate and natural key column IDs)
While you can do a bulk-replace by opening this up in notepad (in XML format) - it would be better if the user could do a find/replace for all instances of a table-name or a columnID from the designer UI (a deep find/replace into all the tools).
This can also be used when a field is renamed in the beginning of the flow, so that we can update this for the remainder of the flow without having to do this by trial/error.
In the browse tool, and the cell viewer attached to the browse tool - the standard control keys (control A for select all; control C for copy) do not behave as they would normally - in order to select all in the cell viewer, you have to right-click and say "Select All".
Please could you include these capabilities in the basic browse tool (control-A and control-C)?
Many thanks
Sean
can we have a formula tool to refer multiple field (especially dynamic as well)

i KNOWN we can use transpose and crosstab tool. but it silly to do one thing with two tool.
Problem
To sum all the fields in the file. so now is A-D.

I can use formula tool to do it. easy. But, what if fields add / delete frequently?

Now, it sum A-E, what if G-F tomorrow, and B-Z after tomorrow, i do not want to update workflow every time.

suggestion :
I hope we have a tool that similar to multiple field tool, but it output to a new field only.

I KNOWN SUM() is not alteryx function but just an example. we can expand further other formula for string and date.
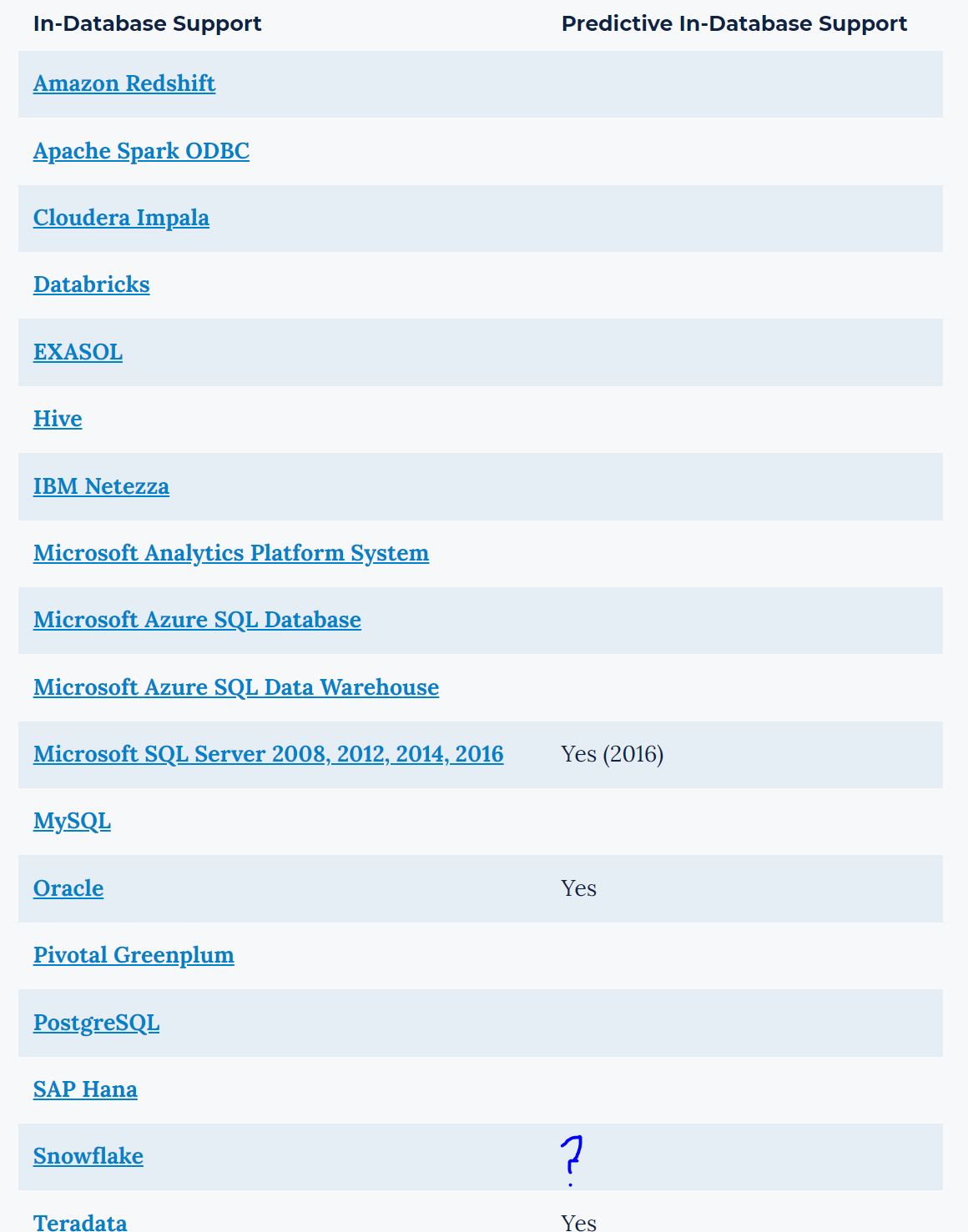
Hi Alteryx,
Can we get the R tools/models to work in database for SNOWFLAKE.
In-Database Overview | Alteryx Help
I understand that Snowflake currently doesn't support R through their UDFs yet; therefore, you might be waiting for them to add it.
I hear Python is coming soon, which is good & Java already available..
However, what about the ‘DPLYR’ package? https://db.rstudio.com/r-packages/dplyr/
My understanding is that this can translate the R code into SQL, so it can run in-DB?
Could this R code package be appended to the Alteryx R models? (maybe this isn’t possible, but wanted ask).
Many Thanks,
Chris
it would particularly interesting to develop a WMS support in Alteryx.
To include other Maps like bing, google, HERE instead of CloudMade to display geo informations.
Mathias
I would love to have a User Setting Default where it allows the "Show All Macro Messages" to be on for all workflows instead of having to turn it on for each workflow.


At the moment one of the Union Tool errors reads: "The field "abc" is not present in all inputs".
It would be useful if the tool said "The field "abc" is not present in Input(s) #x,y..."
If there are a lot of inputs on the tool it can take a while to find which input is missing the field.
In Dec I had an issue where I could not uninstall or upgrade Alteryx. As part of troubleshooting and the eventual solution I had to manually delete any registry key related to Alteryx. As these were hundreds of entries this took a long time. It would be handy if Alteryx could provide a tool that cleaned the registry of all Alteryx related entries. Related: "Case 00088264: Unable to uninstall Alteryx"
Would be nice to have the regex tool allow you to drop original input field and report and error if any records fail to parse.
Hello!
I have a very regional problem, when we use reporting tools, they seem to be encoded in ansi, but in France, we use a lot of accents, and when we want to use the mail tool, we have to "write wrong" with e instead of é for instance, would it be possible to make it possible for us to use accents, I saw a solution in this post (https://community.alteryx.com/t5/Alteryx-Designer-Discussions/French-Characters-in-an-Email-using-Re...) but if it would be possible to have the option directly in the reporting tools it would be a lot easier for us to use them in an automated way!
The regular filter tool is great because I get the true and false returns. When doing ad-hoc analytics it would be super helpful if the date filter did the same thing.
In the example below, I had to create an "IF" statement that returned a T/F value and then fitler out based on the output of that formula.

In the previous tools the information lab had build for publishing to Tableau server, they had the incremental TDE refresh option available. I would like to see that included in the Publish to Tableau Server Macro. We often just want to add previous day data to a YTD data extract without running the full data set from our Datawarehouse. The full set takes long and a daily increment / add only would take a couple minutes.
For deeply structured XML - it would be very helpful to be able to search XML (as you would using the DOM). Even better would be to implement XML Query capability (a visual tool) within Alteryx so that XML data can be directly queried: https://en.wikipedia.org/wiki/XQuery
Hi Team,
Can we use IN DB to connect to Sybase IQ to optimize data extraction and transformation.
If your "Dedicated Sort/Join Memory Usage" setting is set higher than the actual amount of RAM available on your machine, you will get a message in the Results window like this:

My understanding is that the Alteryx workflow will continue to limit itself to the lower memory level throughout the entire duration of running that workflow, even if more memory opens up while the workflow is running. If Alteryx were to check the amount of available RAM periodically while running workflows, Alteryx could take advantage of additional RAM that may open up, resulting in getting results faster. This is particularly valuable for Server environments when many jobs of all sizes are running concurrently.
Alternative data sources namely #altdata are key for enriching data. One source is social media.
I believe Alteryx lacks in social media analytics.
- I would like to propose a Instagram connector...
- Crawl comments, tags(useful for text analytics)
- Impression and likes... (time-series data)
If you are into #media, #advertising, #marketing analytics, #influencer analytics please support the idea by seconding...
https://www.instagram.com/developer/authorization/ is the link for the graph API updated after the latest acebook scandal... now fixed...




The Remove Null Rows feature added to the Data Cleansing tool is really nice, however it doesn't work for a common use case for us where we have key metadata field(s) added to the data stream that make rows not null so we'd like to be able to ignore or exclude one or more fields from the Remove Null Rows output.
Here's a use case starting with an Excel file with multiple tabs where each tab holds the records for a different Province:

Note that the 2nd record in Southern is entirely empty, so this is the record that we'd like to remove using the Data Cleansing tool.
Since the Province name is only in the worksheet name (and not in the data) I'm using a Dynamic Input tool with the "Output File Name as Field" to include the worksheet name so I can parse it out later. So the output of the Dynamic Input looks like this:

With the FileName field populated the entire row is not Null and therefore the Remove Null Rows feature of the Data Cleansing tool fails to remove that record:

{kind=link}
Therefore what we'd like is when we're using the Remove null rows feature in the Data Cleansing tool to be able to choose field(s) to ignore or exclude from that evaluation. For example in the above use case we might tick the "FileName" checkbox to exclude it and then that 2nd row in Southern would be removed from the data.
There are workarounds to use a series of other tools (for example multi-field formula + filter + select) to do this, so extending the Data Cleansing tool to support this feature is a nice to have.
I've attached the sample packaged workflow used to create this example.
- New Idea 294
- Accepting Votes 1,790
- Comments Requested 22
- Under Review 168
- Accepted 54
- Ongoing 8
- Coming Soon 7
- Implemented 539
- Not Planned 111
- Revisit 59
- Partner Dependent 4
- Inactive 674
-
Admin Settings
20 -
AMP Engine
27 -
API
11 -
API SDK
221 -
Category Address
13 -
Category Apps
113 -
Category Behavior Analysis
5 -
Category Calgary
21 -
Category Connectors
247 -
Category Data Investigation
79 -
Category Demographic Analysis
2 -
Category Developer
210 -
Category Documentation
80 -
Category In Database
215 -
Category Input Output
646 -
Category Interface
240 -
Category Join
103 -
Category Machine Learning
3 -
Category Macros
153 -
Category Parse
76 -
Category Predictive
79 -
Category Preparation
395 -
Category Prescriptive
1 -
Category Reporting
199 -
Category Spatial
81 -
Category Text Mining
23 -
Category Time Series
22 -
Category Transform
89 -
Configuration
1 -
Content
1 -
Data Connectors
969 -
Data Products
3 -
Desktop Experience
1,552 -
Documentation
64 -
Engine
127 -
Enhancement
346 -
Feature Request
213 -
General
307 -
General Suggestion
6 -
Insights Dataset
2 -
Installation
24 -
Licenses and Activation
15 -
Licensing
13 -
Localization
8 -
Location Intelligence
80 -
Machine Learning
13 -
My Alteryx
1 -
New Request
204 -
New Tool
32 -
Permissions
1 -
Runtime
28 -
Scheduler
24 -
SDK
10 -
Setup & Configuration
58 -
Tool Improvement
210 -
User Experience Design
165 -
User Settings
81 -
UX
223 -
XML
7
- « Previous
- Next »
- Shifty on: Copy Tool Configuration
- simonaubert_bd on: A formula to get DCM connection name and type (and...
-
 NicoleJ
on:
Disable mouse wheel interactions for unexpanded dr...
NicoleJ
on:
Disable mouse wheel interactions for unexpanded dr...
- haraldharders on: Improve Text Input tool
- simonaubert_bd on: Unique key detector tool
- TUSHAR050392 on: Read an Open Excel file through Input/Dynamic Inpu...
- jackchoy on: Enhancing Data Cleaning
- NeoInfiniTech on: Extended Concatenate Functionality for Cross Tab T...
- AudreyMcPfe on: Overhaul Management of Server Connections
-
AlteryxIdeasTea
m on: Expression Editors: Quality of life update
| User | Likes Count |
|---|---|
| 4 | |
| 3 | |
| 3 | |
| 2 | |
| 2 |