Alteryx Designer Desktop Discussions
Find answers, ask questions, and share expertise about Alteryx Designer Desktop and Intelligence Suite.- Community
- :
- Community
- :
- Participate
- :
- Discussions
- :
- Designer Desktop
- :
- Dynamically update Workflow based on Input Schema
Dynamically update Workflow based on Input Schema
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Hi everyone!
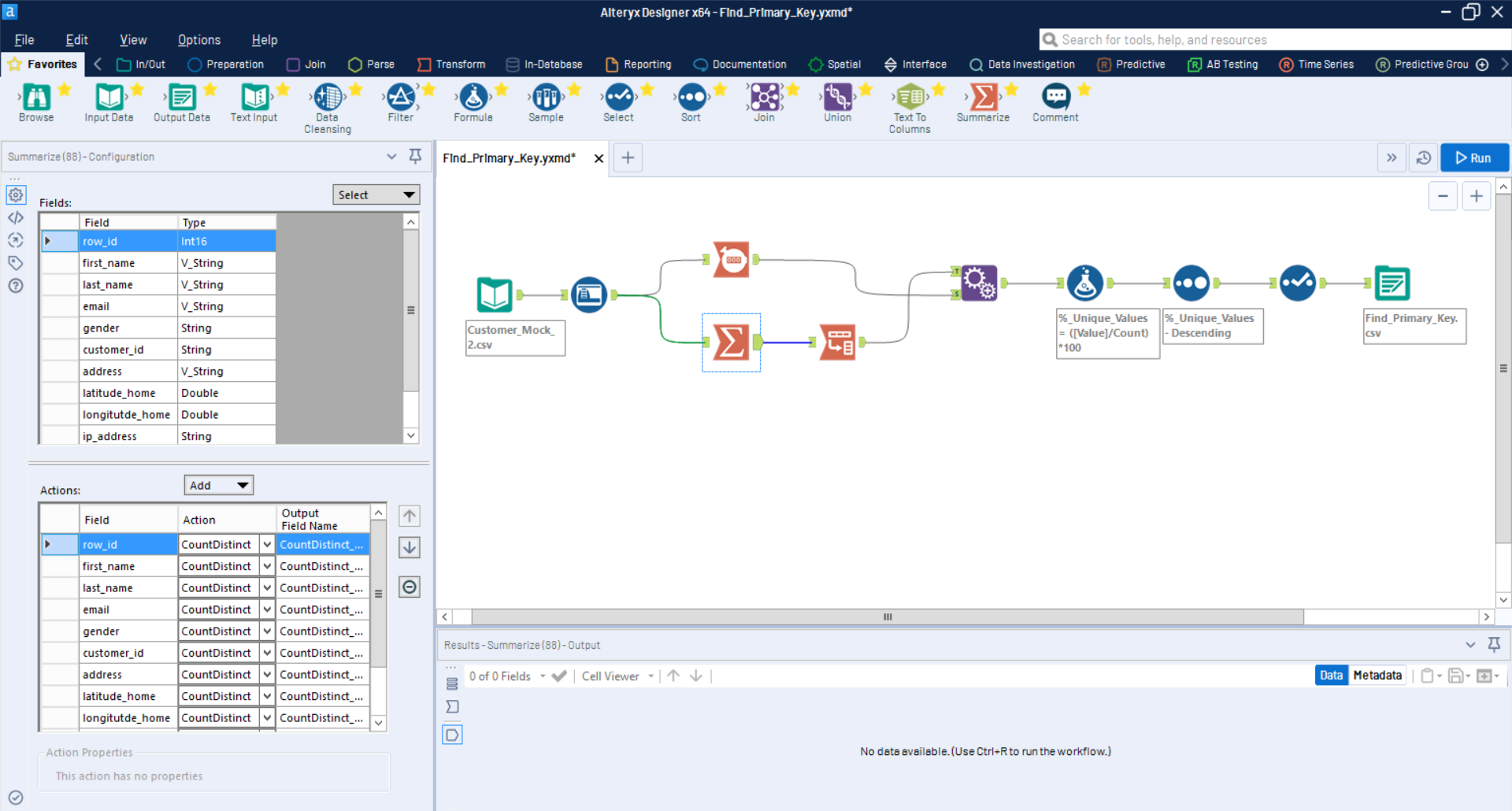
We're currently looking at hundreds of files and trying to "figure out" what column is most probably the Primary Key.
I have created a simple workflow which will read/write .CSV files from/to HDFS. Step by step, I am:
- Summarizing all the columns from the input to count unique values ("Count distinct")
- Transposing to obtain 2 columns (column_name + count_Distinct)
- Appending the total number of rows for each and calculating the % of unique values
- Sorting by % descending, selecting relevant columns and outputting the result.
This works well for a single file, but it would be amazing if we could automate the process for our +- 300 files tables (with different schema/size):
- For the input, I'm thinking of a batch macro for all files and Auto configure by name to adapt for the schemas
- For the output, I'm thinking about taking the name of the .CSV from a field (1 output per table name)
- My issue is dynamically updating the "summarize" tool, which is crucial for the workflow. The tool would need to "Select All columns" and "Count Discount" for all, no matter how many columns are within the table. I thought about modifying the inner XML with an action tool, but I'm unsure if specifying "select all + count discount" is do-able.
Thanks in advance!
Solved! Go to Solution.
- Labels:
-
Dynamic Processing
-
Macros

{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Hi @YULteryx ,
Instead of using the Summarize tool to Count Distinct, could you:
- Transpose all your data to just Name and Value fields
- Use a Unique tool to get just distinct Name and Value pairs
- Add a new field which is just a 1 for every row
- Use the Summarize tool to 'Group By' Name and 'Sum' the new 1 field, creating a count.
This should replicate the Count Distinct but in a more dynamic way for your Batch Macro.
Hope this helps.
Luke
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Hi,
There may be a performance reason not to do this, but have you tried transposing the data first?
Then you can Group By the Name field, and take a Count of Value and a Count Distinct of value at the same time, which will let you perform your calculations from there.
You might need to filter out NULL values as well.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Love the finding the Primary Key solution by the way!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Thank you both for your answers! It clearly shows how Alteryx offers several ways to obtain the same output.
I will try to implement your approach and let you know how it goes.
Cheers.
[EDIT] - it works perfectly. Appreciate your support!
-
Academy
6 -
ADAPT
2 -
Adobe
204 -
Advent of Code
3 -
Alias Manager
78 -
Alteryx Copilot
26 -
Alteryx Designer
7 -
Alteryx Editions
95 -
Alteryx Practice
20 -
Amazon S3
149 -
AMP Engine
252 -
Announcement
1 -
API
1,208 -
App Builder
116 -
Apps
1,360 -
Assets | Wealth Management
1 -
Basic Creator
15 -
Batch Macro
1,559 -
Behavior Analysis
246 -
Best Practices
2,695 -
Bug
719 -
Bugs & Issues
1 -
Calgary
67 -
CASS
53 -
Chained App
268 -
Common Use Cases
3,825 -
Community
26 -
Computer Vision
86 -
Connectors
1,426 -
Conversation Starter
3 -
COVID-19
1 -
Custom Formula Function
1 -
Custom Tools
1,938 -
Data
1 -
Data Challenge
10 -
Data Investigation
3,487 -
Data Science
3 -
Database Connection
2,220 -
Datasets
5,222 -
Date Time
3,227 -
Demographic Analysis
186 -
Designer Cloud
742 -
Developer
4,372 -
Developer Tools
3,530 -
Documentation
527 -
Download
1,037 -
Dynamic Processing
2,939 -
Email
928 -
Engine
145 -
Enterprise (Edition)
1 -
Error Message
2,258 -
Events
198 -
Expression
1,868 -
Financial Services
1 -
Full Creator
2 -
Fun
2 -
Fuzzy Match
712 -
Gallery
666 -
GenAI Tools
3 -
General
2 -
Google Analytics
155 -
Help
4,708 -
In Database
966 -
Input
4,293 -
Installation
361 -
Interface Tools
1,901 -
Iterative Macro
1,094 -
Join
1,958 -
Licensing
252 -
Location Optimizer
60 -
Machine Learning
260 -
Macros
2,864 -
Marketo
12 -
Marketplace
23 -
MongoDB
82 -
Off-Topic
5 -
Optimization
751 -
Output
5,255 -
Parse
2,328 -
Power BI
228 -
Predictive Analysis
937 -
Preparation
5,169 -
Prescriptive Analytics
206 -
Professional (Edition)
4 -
Publish
257 -
Python
855 -
Qlik
39 -
Question
1 -
Questions
2 -
R Tool
476 -
Regex
2,339 -
Reporting
2,434 -
Resource
1 -
Run Command
575 -
Salesforce
277 -
Scheduler
411 -
Search Feedback
3 -
Server
630 -
Settings
935 -
Setup & Configuration
3 -
Sharepoint
627 -
Spatial Analysis
599 -
Starter (Edition)
1 -
Tableau
512 -
Tax & Audit
1 -
Text Mining
468 -
Thursday Thought
4 -
Time Series
431 -
Tips and Tricks
4,187 -
Topic of Interest
1,126 -
Transformation
3,730 -
Twitter
23 -
Udacity
84 -
Updates
1 -
Viewer
3 -
Workflow
9,980
- « Previous
- Next »