Alteryx Designer Desktop Discussions
Find answers, ask questions, and share expertise about Alteryx Designer Desktop and Intelligence Suite.- Community
- :
- Community
- :
- Participate
- :
- Discussions
- :
- Designer Desktop
- :
- Transforming Data
Transforming Data
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
trI need to transform data from rows to columns.
So the group field is called PIN but then I have Lic #, Lic Type, Lic Date.
I need to include all lic fields on the same row as the pin. How can I accomplish this?
So like this:
| Pin | Lic # | Lic type | Lic Date | Lic # | Lic type | Lic Date |
| 100 | 1 | Small | 1/1/2023 | 4 | Medium | 4/1/2023 |
| 200 | 2 | Small | 2/1/2023 | 5 | Medium | 5/1/2023 |
| 300 | 3 | Small | 3/1/2023 | 6 | Medium | 6/1/2023 |
- Labels:
-
Transformation
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
I'm thinking the Crosstab tool, but column headers are required to be unique so they won't look like the way you pictured in your table.
If you can also share what your source/start data looks like, we may be able to provide a more detailed solution.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
I want all lice on the same row as the pin. Your example has it on different rows.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Apologies - I see now that is your desired output. Can you quickly demonstrate what it would look like coming in
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sure, actually exactly what you have in our output, without the record id. So I need the reverse.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
You can group by the pin and concatenate the other fields. This does not get exactly to your desired output of having the information in separate fields. To get that I used some brute force with text-to-columns splitting on the ",".
This works fine when there are only ever two of each but I'd need to spend more time thinking up a dynamic solution to split based on the number of records per pin. Suppose you could increase the split to a larger number than the maximum and then remove null columns. Potential problem is that you are making the data very wide and not as performant.
I'll leave the brute force one here and then give a smarter solution some thought.

The second workflow is one that expands the table and removes null columns
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
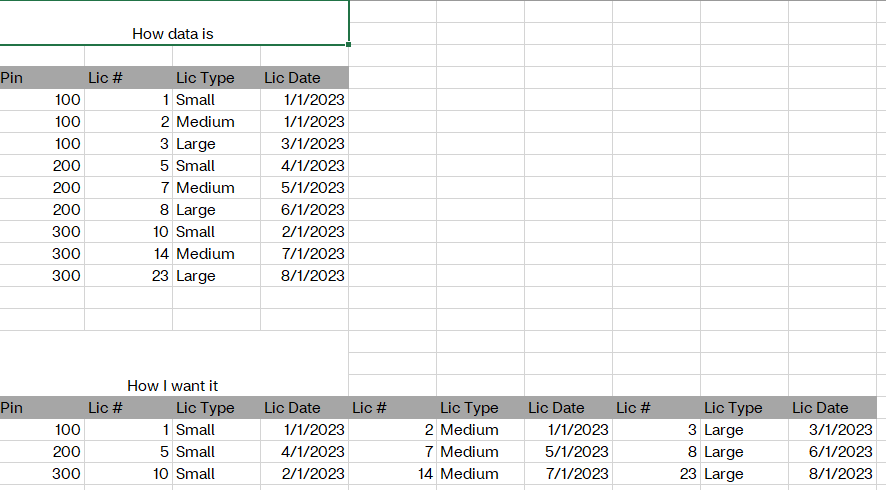
I think I might have confused you.
Maybe this will help.
| How data is | |||||||||
| Pin | Lic # | Lic Type | Lic Date | ||||||
| 100 | 1 | Small | 1/1/2023 | ||||||
| 100 | 2 | Medium | 1/1/2023 | ||||||
| 100 | 3 | Large | 3/1/2023 | ||||||
| 200 | 5 | Small | 4/1/2023 | ||||||
| 200 | 7 | Medium | 5/1/2023 | ||||||
| 200 | 8 | Large | 6/1/2023 | ||||||
| 300 | 10 | Small | 2/1/2023 | ||||||
| 300 | 14 | Medium | 7/1/2023 | ||||||
| 300 | 23 | Large | 8/1/2023 | ||||||
| How I want it | |||||||||
| Pin | Lic # | Lic Type | Lic Date | Lic # | Lic Type | Lic Date | Lic # | Lic Type | Lic Date |
| 100 | 1 | Small | 1/1/2023 | 2 | Medium | 1/1/2023 | 3 | Large | 3/1/2023 |
| 200 | 5 | Small | 4/1/2023 | 7 | Medium | 5/1/2023 | 8 | Large | 6/1/2023 |
| 300 | 10 | Small | 2/1/2023 | 14 | Medium | 7/1/2023 | 23 | Large | 8/1/2023 |
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
The above Workflow would achieve that output - although you cannot have column headers with identical names - hence the suffix (LIC_1, LIC_2 ETC.). But the logic of bringing all that information onto the same row for each pin and then splitting on the list delimiter is likely the best way to achieve this.
The second part of my comment was more rambling about thinking of more dynamic ways of getting to the desired output (when pins have varying amount of LICs in them.)


-
Academy
5 -
ADAPT
2 -
Adobe
201 -
Advent of Code
2 -
Alias Manager
76 -
Alteryx Copilot
21 -
Alteryx Designer
7 -
Alteryx Editions
58 -
Alteryx Practice
19 -
Amazon S3
148 -
AMP Engine
247 -
Announcement
1 -
API
1,201 -
App Builder
113 -
Apps
1,356 -
Assets | Wealth Management
1 -
Basic Creator
10 -
Batch Macro
1,530 -
Behavior Analysis
244 -
Best Practices
2,677 -
Bug
713 -
Bugs & Issues
1 -
Calgary
67 -
CASS
53 -
Chained App
265 -
Common Use Cases
3,801 -
Community
24 -
Computer Vision
82 -
Connectors
1,411 -
Conversation Starter
3 -
COVID-19
1 -
Custom Formula Function
1 -
Custom Tools
1,932 -
Data
1 -
Data Challenge
9 -
Data Investigation
3,471 -
Data Science
2 -
Database Connection
2,200 -
Datasets
5,190 -
Date Time
3,218 -
Demographic Analysis
184 -
Designer Cloud
724 -
Developer
4,333 -
Developer Tools
3,507 -
Documentation
524 -
Download
1,026 -
Dynamic Processing
2,916 -
Email
924 -
Engine
145 -
Error Message
2,235 -
Events
194 -
Expression
1,862 -
Financial Services
1 -
Full Creator
1 -
Fun
2 -
Fuzzy Match
707 -
Gallery
658 -
GenAI Tools
1 -
General
1 -
Google Analytics
156 -
Help
4,688 -
In Database
961 -
Input
4,267 -
Installation
352 -
Interface Tools
1,890 -
Iterative Macro
1,084 -
Join
1,945 -
Licensing
245 -
Location Optimizer
61 -
Machine Learning
257 -
Macros
2,836 -
Marketo
12 -
Marketplace
22 -
MongoDB
83 -
Off-Topic
4 -
Optimization
745 -
Output
5,216 -
Parse
2,315 -
Power BI
224 -
Predictive Analysis
934 -
Preparation
5,137 -
Prescriptive Analytics
205 -
Professional (Edition)
2 -
Publish
256 -
Python
849 -
Qlik
39 -
Question
1 -
Questions
2 -
R Tool
477 -
Regex
2,332 -
Reporting
2,424 -
Resource
1 -
Run Command
568 -
Salesforce
276 -
Scheduler
410 -
Search Feedback
3 -
Server
619 -
Settings
929 -
Setup & Configuration
3 -
Sharepoint
615 -
Spatial Analysis
596 -
Tableau
511 -
Tax & Audit
1 -
Text Mining
465 -
Thursday Thought
4 -
Time Series
428 -
Tips and Tricks
4,166 -
Topic of Interest
1,120 -
Transformation
3,698 -
Twitter
23 -
Udacity
84 -
Updates
1 -
Viewer
2 -
Workflow
9,900
- « Previous
- Next »
| User | Count |
|---|---|
| 106 | |
| 85 | |
| 76 | |
| 54 | |
| 40 |