Alteryx Designer Desktop Discussions
Find answers, ask questions, and share expertise about Alteryx Designer Desktop and Intelligence Suite.- Community
- :
- Community
- :
- Participate
- :
- Discussions
- :
- Designer Desktop
- :
- Re: How to trap fields/values from a .txt input
How to trap fields/values from a .txt input
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
I have a .txt file where the data is somewhat unstructured as shown in the two attachments, especially page 2. Highlighted in both are the data I would like to bring into Alteryx as a table with the field names (e.g. PAYT GRP ID/NAME) and their corresponding values (e.g. 24/MONTHLY AFIS). How is the best way to trap this information and bring it in. The other issue is this txt document can have a page range of anywhere between 3 - 15 but I'm only needing the information from pages 1 & 2. Thanks.
Solved! Go to Solution.
- Labels:
-
Data Investigation

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Felipe - I'm trying to accomplish a similar objective with the attached .txt file, but I don't understand how to adapt your Regex formula to work with this data set. When running it, I can't get the expected values within the Key and Value fields as I don't understand how this formula works. Also attached is a screencapture (.png) of the fields I'm trying to make use of along with the workflow. Are you able to take a look and advise how to get this regex to work? Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
@Jake5 for the Field 1 error, you need to uncheck the box in the input configuration that says "First Row Contains Field Names"

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Thank you Felipe. That achieved the desired results, but can you share what update you made compared to the workflow I sent you? The regex formula looks the same as what I included in mine.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
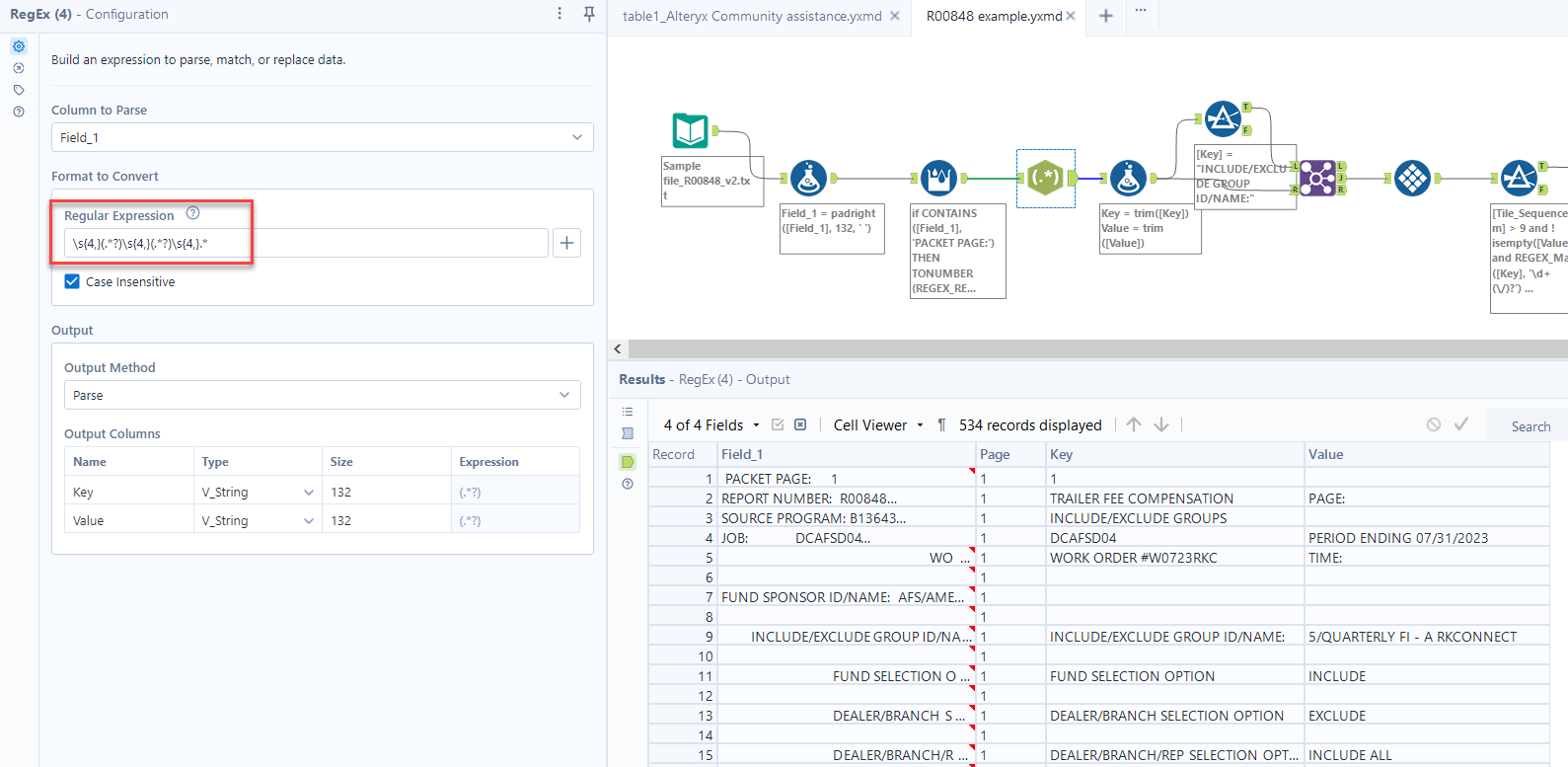
Thank you, Felipe. So something I just realized is for this input, there can be instances where page 1 layout can repeat in subsequent pages, the difference from one page to the next being the field value for INCLUDE/EXCLUDE GROUP ID/NAME:. Using the attached txt file, page 1 has INCLUDE/EXCLUDE GROUP ID/NAME: = 5/QUARTERLY FI - A RKCONNECT, page 5 = 11/QUARTERLY TPA - R RKCONNECT and so forth. I need the workflow to identify all pages where this layout is present in order to render the attached, desired output. My challenge is trying to trap the unique value for INCLUDE/EXCLUDE GROUP ID/NAME from each page. Are you able to assist?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator

{kind=link}
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Hi, Felipe. The output seems to work with that input file but I just tried running the workflow against this version (see attached Sample file_R00848_v3.txt.) There seems to be an issue with the page numbers that are being assigned as the highest page number the multi-row formula generates is 9 but this is a 37 page document. In this version the values I"m after are on pages 1, 17, 29, and 33. Sorry to continue to ask for your help - you've been amazing! Can you look over and advise? Thank you!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Hi @Jake5
You are right, there is an error unable to parse page numbers above the page 10. Please replace the expression of the multi row formula by this one, it should work now.
if CONTAINS([Field_1], 'PACKET PAGE:') THEN TONUMBER(REGEX_REPLACE([Field_1], '(.*?)(\d+)(.*)', '$2')) ELSE [Row-1:Page] ENDIF
(Basically, i just added the red ? to the previous version)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Yes - that worked - thank you!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Hi, Felipe
In the attached workflow you provided, you used \s{4,}(.*?)\s{4,}(.*?)\s{4,}.* as the Regex formula (Regex tool). Can you help me understand how this formula is able to effectively parse Field_1 into the Key and Value fields? I'm just wanting to learn for my own understanding. Thanks!
{kind=link}

-
Academy
6 -
ADAPT
2 -
Adobe
203 -
Advent of Code
3 -
Alias Manager
77 -
Alteryx Copilot
23 -
Alteryx Designer
7 -
Alteryx Editions
86 -
Alteryx Practice
20 -
Amazon S3
149 -
AMP Engine
250 -
Announcement
1 -
API
1,205 -
App Builder
115 -
Apps
1,358 -
Assets | Wealth Management
1 -
Basic Creator
13 -
Batch Macro
1,550 -
Behavior Analysis
244 -
Best Practices
2,689 -
Bug
719 -
Bugs & Issues
1 -
Calgary
67 -
CASS
53 -
Chained App
267 -
Common Use Cases
3,817 -
Community
26 -
Computer Vision
85 -
Connectors
1,422 -
Conversation Starter
3 -
COVID-19
1 -
Custom Formula Function
1 -
Custom Tools
1,933 -
Data
1 -
Data Challenge
10 -
Data Investigation
3,484 -
Data Science
3 -
Database Connection
2,214 -
Datasets
5,212 -
Date Time
3,226 -
Demographic Analysis
185 -
Designer Cloud
736 -
Developer
4,355 -
Developer Tools
3,523 -
Documentation
525 -
Download
1,035 -
Dynamic Processing
2,932 -
Email
925 -
Engine
145 -
Enterprise (Edition)
1 -
Error Message
2,251 -
Events
196 -
Expression
1,867 -
Financial Services
1 -
Full Creator
2 -
Fun
2 -
Fuzzy Match
711 -
Gallery
666 -
GenAI Tools
2 -
General
2 -
Google Analytics
155 -
Help
4,701 -
In Database
965 -
Input
4,288 -
Installation
359 -
Interface Tools
1,895 -
Iterative Macro
1,090 -
Join
1,954 -
Licensing
250 -
Location Optimizer
60 -
Machine Learning
259 -
Macros
2,854 -
Marketo
12 -
Marketplace
23 -
MongoDB
82 -
Off-Topic
5 -
Optimization
749 -
Output
5,239 -
Parse
2,323 -
Power BI
227 -
Predictive Analysis
936 -
Preparation
5,157 -
Prescriptive Analytics
205 -
Professional (Edition)
4 -
Publish
257 -
Python
850 -
Qlik
39 -
Question
1 -
Questions
2 -
R Tool
476 -
Regex
2,338 -
Reporting
2,428 -
Resource
1 -
Run Command
572 -
Salesforce
276 -
Scheduler
410 -
Search Feedback
3 -
Server
627 -
Settings
931 -
Setup & Configuration
3 -
Sharepoint
624 -
Spatial Analysis
598 -
Starter (Edition)
1 -
Tableau
511 -
Tax & Audit
1 -
Text Mining
468 -
Thursday Thought
4 -
Time Series
430 -
Tips and Tricks
4,178 -
Topic of Interest
1,123 -
Transformation
3,719 -
Twitter
23 -
Udacity
84 -
Updates
1 -
Viewer
3 -
Workflow
9,955
- « Previous
- Next »