Alteryx Designer Desktop Discussions
Find answers, ask questions, and share expertise about Alteryx Designer Desktop and Intelligence Suite.- Community
- :
- Community
- :
- Participate
- :
- Discussions
- :
- Designer Desktop
- :
- Parsing HTML with Python Tool
Parsing HTML with Python Tool
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
After reading many articles about HTML parsing and NOT to use REGEX, which is how I am doing it, with a high level, but not 100% accuracy. Has anyone used a Python HTML parsing package within the Python Tool? I am parsing many fields of HTML/CLOB with REGEX but I am looking for a better way. Thank you
Solved! Go to Solution.
- Labels:
-
Best Practices
-
Developer
-
Help
-
Python

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
While you wait for someone more knowledgeable than myself to reply, I'll suggest the python library "beautiful soup". Without knowing more about your specific needs and use case I can't say for sure if it's the right solution for you but it's a solid html parsing tool.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Excellent idea. How would I use it in the Python Tool? I am looking for an example on how to code the Python tool using such a package.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Beautiful Soup is the most common python package used for web scraping. There are a few other options, including lxml. It is usually a matter of finding the package that best fits your needs
I've attached a screenshot from a very simple example I have. The Python tool uses Jupyter Notebook, so no extra modifications are needed unless you are reading/writing data from Alteryx Designer.
Below is some useful documentation:
Beautiful Soup:
https://codeburst.io/web-scraping-101-with-python-beautiful-soup-bb617be1f486
lxml:
https://docs.python-guide.org/scenarios/scrape/
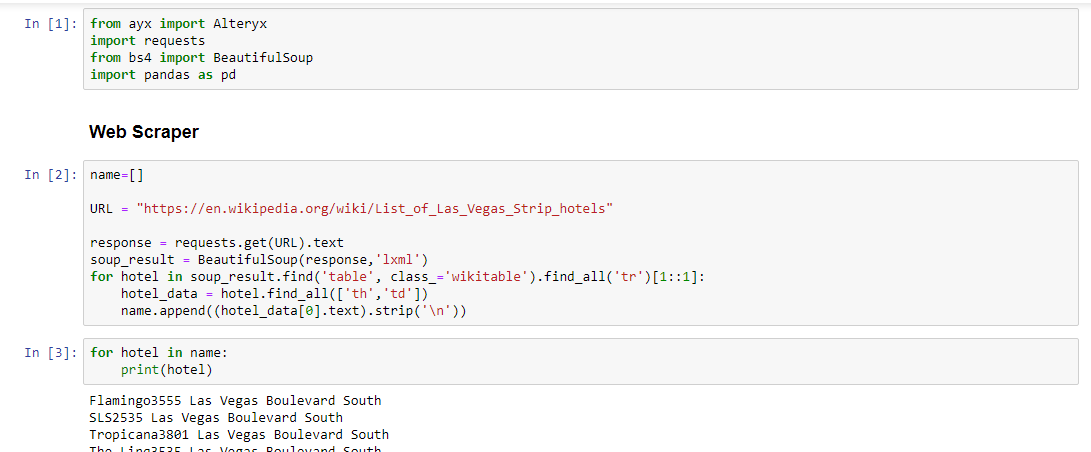{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Thank you I understand what I need ot do but I am running into some issues.
I go to import, either bs4 or BeautifulSoup, and I get a ModuleNotFoundError.
To complicate things, I am using an Anaconda instance (which has BeautifulSoup). Does Alteryx need to know where the Anaconda instance is?
Thank you
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
The Python Tool in Designer uses its own version of Miniconda, which may not have BeautifulSoup installed by default. You will need to install the necessary packages.
Use the following syntax in the Python Tool to install the packages
from ayx import Package
Package.installPackages(['beautifulSoup4'])
After this, the following should work:
from bs4 import BeautifulSoup
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Thank you. I need to get admin privileges on my machine to do that but I can get everything else to work in command line and Anaconda. Now I just need to get it inside Alteryx.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Finally everything is set up. Now my question is how do I apply this against one column in a database table? For some reason, the HTML is stored in an Oracle table within the database with other columns. Of course, not a column with just the clean text out of the HTML.
Thank you for you assistance. I am hoping this will finally get me over the hump.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
You'll need to setup an ODBC Driver in Alteryx to reach out to Oracle and grab your field with the HTML.
https://help.alteryx.com/2018.2/DataSources/Oracle.htm
You can then read this into the Python tool and use the libraries to parse the html.
-
Academy
6 -
ADAPT
2 -
Adobe
204 -
Advent of Code
3 -
Alias Manager
78 -
Alteryx Copilot
25 -
Alteryx Designer
7 -
Alteryx Editions
94 -
Alteryx Practice
20 -
Amazon S3
149 -
AMP Engine
252 -
Announcement
1 -
API
1,208 -
App Builder
116 -
Apps
1,360 -
Assets | Wealth Management
1 -
Basic Creator
15 -
Batch Macro
1,558 -
Behavior Analysis
246 -
Best Practices
2,693 -
Bug
719 -
Bugs & Issues
1 -
Calgary
67 -
CASS
53 -
Chained App
268 -
Common Use Cases
3,823 -
Community
26 -
Computer Vision
85 -
Connectors
1,426 -
Conversation Starter
3 -
COVID-19
1 -
Custom Formula Function
1 -
Custom Tools
1,936 -
Data
1 -
Data Challenge
10 -
Data Investigation
3,486 -
Data Science
3 -
Database Connection
2,220 -
Datasets
5,221 -
Date Time
3,227 -
Demographic Analysis
186 -
Designer Cloud
740 -
Developer
4,369 -
Developer Tools
3,528 -
Documentation
526 -
Download
1,037 -
Dynamic Processing
2,937 -
Email
927 -
Engine
145 -
Enterprise (Edition)
1 -
Error Message
2,256 -
Events
198 -
Expression
1,868 -
Financial Services
1 -
Full Creator
2 -
Fun
2 -
Fuzzy Match
711 -
Gallery
666 -
GenAI Tools
3 -
General
2 -
Google Analytics
155 -
Help
4,706 -
In Database
966 -
Input
4,291 -
Installation
360 -
Interface Tools
1,900 -
Iterative Macro
1,094 -
Join
1,957 -
Licensing
252 -
Location Optimizer
60 -
Machine Learning
259 -
Macros
2,862 -
Marketo
12 -
Marketplace
23 -
MongoDB
82 -
Off-Topic
5 -
Optimization
750 -
Output
5,252 -
Parse
2,327 -
Power BI
228 -
Predictive Analysis
936 -
Preparation
5,167 -
Prescriptive Analytics
205 -
Professional (Edition)
4 -
Publish
257 -
Python
855 -
Qlik
39 -
Question
1 -
Questions
2 -
R Tool
476 -
Regex
2,339 -
Reporting
2,431 -
Resource
1 -
Run Command
575 -
Salesforce
277 -
Scheduler
411 -
Search Feedback
3 -
Server
629 -
Settings
933 -
Setup & Configuration
3 -
Sharepoint
626 -
Spatial Analysis
599 -
Starter (Edition)
1 -
Tableau
512 -
Tax & Audit
1 -
Text Mining
468 -
Thursday Thought
4 -
Time Series
431 -
Tips and Tricks
4,187 -
Topic of Interest
1,126 -
Transformation
3,726 -
Twitter
23 -
Udacity
84 -
Updates
1 -
Viewer
3 -
Workflow
9,976
- « Previous
- Next »