Alteryx Designer Desktop Discussions
Find answers, ask questions, and share expertise about Alteryx Designer Desktop and Intelligence Suite.- Community
- :
- Community
- :
- Participate
- :
- Discussions
- :
- Designer Desktop
- :
- Re: Filter and remove duplicates
Filter and remove duplicates
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Hi All,
I have a file. Column A has all employee IDs and it has duplicate IDs since data is consolidated for different dates into one file. Now my requirement is to filter the data as per employee ID and remove the duplicates based on value in a different column. So I will put a filter in Column A and check the the values in Column G and remove the entire row if column G has duplicate value. Appreciate any help around this.
Thanks in Advance!
Solved! Go to Solution.
- Labels:
-
Common Use Cases

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Hello Hermant86,
If I understand your use case correctly you should be able to use the unique tool. Configure it to identify a duplicate using both the ID column as well as the additional column. If this is an incorrect assumption of what you would like to accomplish please post a small sample of the data and identify a few "duplicates" and I can try again.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Yes that is what I was expecting. The unique tool (in preparation) should get the job done for you.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Thanks Erica!....That does the job for me. This community is amazing.🙂
If I can ask for one more favor.
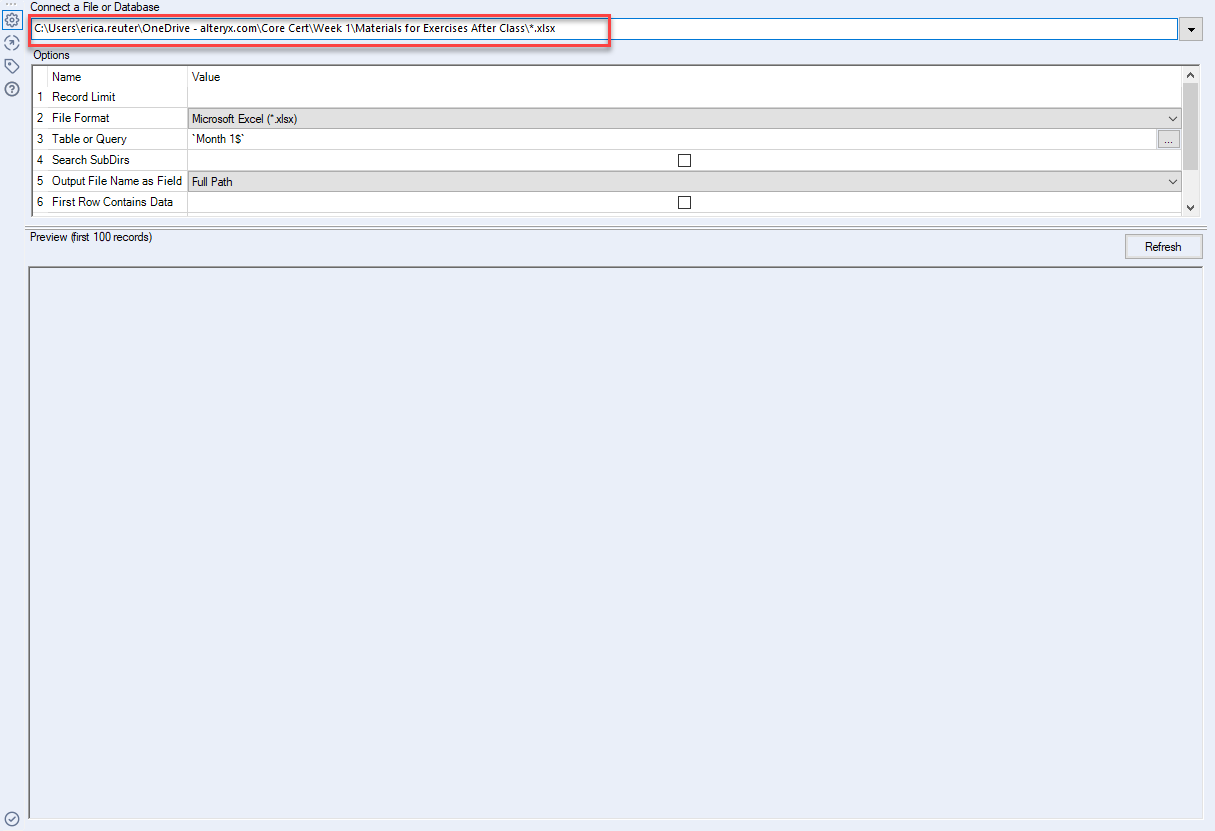
I need to consolidate a bunch of excel files placed in a folder. The number of files in the folder keeps changing. The files names are different and each file has a sheet with a different name. But the column headers and order is always constant. So I need to merge all the data into a single file. I tried something which I got online like using a wildcard in the path of the files to loop through all available files but it throws an error.
Appreciate if you can guide me on that.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
{kind=link}
-
Academy
6 -
ADAPT
2 -
Adobe
204 -
Advent of Code
3 -
Alias Manager
78 -
Alteryx Copilot
26 -
Alteryx Designer
7 -
Alteryx Editions
95 -
Alteryx Practice
20 -
Amazon S3
149 -
AMP Engine
252 -
Announcement
1 -
API
1,209 -
App Builder
116 -
Apps
1,360 -
Assets | Wealth Management
1 -
Basic Creator
15 -
Batch Macro
1,559 -
Behavior Analysis
246 -
Best Practices
2,695 -
Bug
719 -
Bugs & Issues
1 -
Calgary
67 -
CASS
53 -
Chained App
268 -
Common Use Cases
3,825 -
Community
26 -
Computer Vision
86 -
Connectors
1,426 -
Conversation Starter
3 -
COVID-19
1 -
Custom Formula Function
1 -
Custom Tools
1,939 -
Data
1 -
Data Challenge
10 -
Data Investigation
3,488 -
Data Science
3 -
Database Connection
2,221 -
Datasets
5,223 -
Date Time
3,229 -
Demographic Analysis
186 -
Designer Cloud
743 -
Developer
4,376 -
Developer Tools
3,533 -
Documentation
528 -
Download
1,037 -
Dynamic Processing
2,941 -
Email
928 -
Engine
145 -
Enterprise (Edition)
1 -
Error Message
2,262 -
Events
198 -
Expression
1,868 -
Financial Services
1 -
Full Creator
2 -
Fun
2 -
Fuzzy Match
714 -
Gallery
666 -
GenAI Tools
3 -
General
2 -
Google Analytics
155 -
Help
4,711 -
In Database
966 -
Input
4,296 -
Installation
361 -
Interface Tools
1,902 -
Iterative Macro
1,095 -
Join
1,960 -
Licensing
252 -
Location Optimizer
60 -
Machine Learning
260 -
Macros
2,865 -
Marketo
12 -
Marketplace
23 -
MongoDB
82 -
Off-Topic
5 -
Optimization
751 -
Output
5,258 -
Parse
2,328 -
Power BI
228 -
Predictive Analysis
937 -
Preparation
5,171 -
Prescriptive Analytics
206 -
Professional (Edition)
4 -
Publish
257 -
Python
855 -
Qlik
39 -
Question
1 -
Questions
2 -
R Tool
476 -
Regex
2,339 -
Reporting
2,434 -
Resource
1 -
Run Command
575 -
Salesforce
277 -
Scheduler
411 -
Search Feedback
3 -
Server
631 -
Settings
936 -
Setup & Configuration
3 -
Sharepoint
628 -
Spatial Analysis
599 -
Starter (Edition)
1 -
Tableau
512 -
Tax & Audit
1 -
Text Mining
468 -
Thursday Thought
4 -
Time Series
432 -
Tips and Tricks
4,187 -
Topic of Interest
1,126 -
Transformation
3,731 -
Twitter
23 -
Udacity
84 -
Updates
1 -
Viewer
3 -
Workflow
9,982
- « Previous
- Next »