Alteryx Designer Desktop Discussions
Find answers, ask questions, and share expertise about Alteryx Designer Desktop and Intelligence Suite.- Community
- :
- Community
- :
- Participate
- :
- Discussions
- :
- Designer Desktop
- :
- Better view of the sorting problem
Order number field within a group
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
I feel like there is probably a tool that can easily do what I want, but for whatever reason I'm having a hard time finding it.
I'm simply looking to group and then number rows within the group. For example, in the below table i want to add a column called 'order num' that essentially numbers each item within the group.
| lookup id | product id |
| 100 | 5234 |
| 100 | 6987 |
| 100 | 4465 |
| 101 | 7899 |
| 102 | 6891 |
| 102 | 3233 |
So the final result would look like this:
| lookup id | order num | product id |
| 100 | 1 | 5234 |
| 100 | 2 | 6987 |
| 100 | 3 | 4465 |
| 101 | 1 | 7899 |
| 102 | 1 | 6891 |
| 102 | 2 | 3233 |
Solved! Go to Solution.
- Labels:
-
Transformation

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
The Tile tool (in Preparation category) is a good tool for this: Set your tile method to Unique Value, and choose your lookupid as the unique field. The results will give you Tile_Num based on the groups of lookup id's, and then the Tile_SequenceNum will be your record id within each group. :)
NJ
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
So for unique value I choose the lookupid, and then also choose that as the 'grouping fields' at the bottom section?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
I get an error (Parse error) with the code and was wondering the same thing. The grouping that I'm using is based on a string variable that is a concatenate of 'school system/school/race [alpha]/grade' for the purpose of doing a 1:1 matched-pair analysis.
Are the built-in operations used?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
can you send over a screenshot of your config and the error that's being triggered?
Parse errors are usually caused by string+double missmatches.
Ben
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
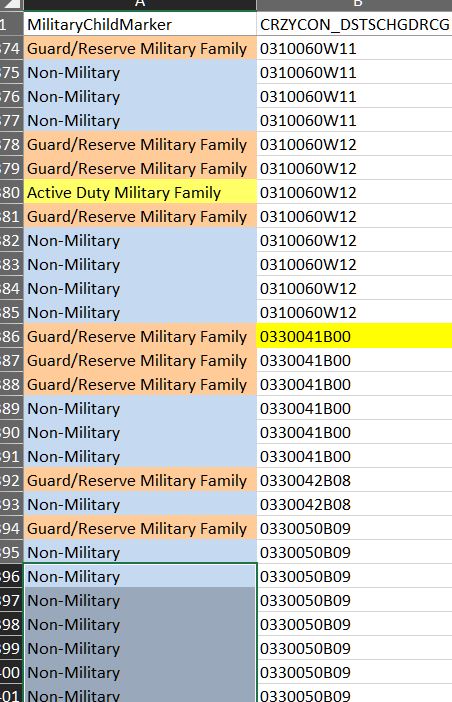
There are two images attached.
Yes, that's probably the problem. The field that I want to parse is a string from the concatenate of four other string variables (system_no,school_no,race_alpha,grade_no) The school systems reuse the numbering sequence (0010), and the system designations have leading zeros on a three-digit code. Converting to numbers prior to concatenating produces mismatched duplicates such that different schools would share the same number. To create a unique identifier for the school, we have used a concatenate of the strings. My match will also rely on race ( and inconsistent alphabetical designation that changes by year) and grade (two digits) is named CRZYCON_DSTSCHGDRCG. It's an ugly mess, but I need the student matches to occur within the same school, within the same race and grade.
I'm comparing assessments and discipline rates for children of military families to their peers in their respective schools. The state did not provide a poverty marker, so we cannot match on that dimension. I'm exploring using the tile function as a substitute.
That field (CRZYCON_DSTSCHGDRCG) sorts beautifully in Excel, with the military/non-military field as a second criterion. If I have five military students in a school with X characteristics, I need five non-military students from that same school with X characteristics (already randomly sorted), and I will discard the unmatched. I tried this manually in Excel, but need a more efficient way to do it (600,000+ records, but only 9,000 military kids).
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
{kind=link}
-
Academy
6 -
ADAPT
2 -
Adobe
204 -
Advent of Code
3 -
Alias Manager
78 -
Alteryx Copilot
26 -
Alteryx Designer
7 -
Alteryx Editions
95 -
Alteryx Practice
20 -
Amazon S3
149 -
AMP Engine
252 -
Announcement
1 -
API
1,208 -
App Builder
116 -
Apps
1,360 -
Assets | Wealth Management
1 -
Basic Creator
15 -
Batch Macro
1,559 -
Behavior Analysis
246 -
Best Practices
2,695 -
Bug
719 -
Bugs & Issues
1 -
Calgary
67 -
CASS
53 -
Chained App
268 -
Common Use Cases
3,825 -
Community
26 -
Computer Vision
86 -
Connectors
1,426 -
Conversation Starter
3 -
COVID-19
1 -
Custom Formula Function
1 -
Custom Tools
1,938 -
Data
1 -
Data Challenge
10 -
Data Investigation
3,487 -
Data Science
3 -
Database Connection
2,220 -
Datasets
5,222 -
Date Time
3,227 -
Demographic Analysis
186 -
Designer Cloud
742 -
Developer
4,372 -
Developer Tools
3,530 -
Documentation
527 -
Download
1,037 -
Dynamic Processing
2,939 -
Email
928 -
Engine
145 -
Enterprise (Edition)
1 -
Error Message
2,258 -
Events
198 -
Expression
1,868 -
Financial Services
1 -
Full Creator
2 -
Fun
2 -
Fuzzy Match
712 -
Gallery
666 -
GenAI Tools
3 -
General
2 -
Google Analytics
155 -
Help
4,708 -
In Database
966 -
Input
4,293 -
Installation
361 -
Interface Tools
1,901 -
Iterative Macro
1,094 -
Join
1,958 -
Licensing
252 -
Location Optimizer
60 -
Machine Learning
260 -
Macros
2,864 -
Marketo
12 -
Marketplace
23 -
MongoDB
82 -
Off-Topic
5 -
Optimization
751 -
Output
5,255 -
Parse
2,328 -
Power BI
228 -
Predictive Analysis
937 -
Preparation
5,169 -
Prescriptive Analytics
206 -
Professional (Edition)
4 -
Publish
257 -
Python
855 -
Qlik
39 -
Question
1 -
Questions
2 -
R Tool
476 -
Regex
2,339 -
Reporting
2,434 -
Resource
1 -
Run Command
575 -
Salesforce
277 -
Scheduler
411 -
Search Feedback
3 -
Server
630 -
Settings
935 -
Setup & Configuration
3 -
Sharepoint
627 -
Spatial Analysis
599 -
Starter (Edition)
1 -
Tableau
512 -
Tax & Audit
1 -
Text Mining
468 -
Thursday Thought
4 -
Time Series
431 -
Tips and Tricks
4,187 -
Topic of Interest
1,126 -
Transformation
3,730 -
Twitter
23 -
Udacity
84 -
Updates
1 -
Viewer
3 -
Workflow
9,980
- « Previous
- Next »