Alteryx Designer Desktop Discussions
Find answers, ask questions, and share expertise about Alteryx Designer Desktop and Intelligence Suite.- Community
- :
- Community
- :
- Participate
- :
- Discussions
- :
- Designer Desktop
- :
- Pass results as parameters from Alteryx to Python ...
Pass results as parameters from Alteryx to Python script
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Hi Experts,
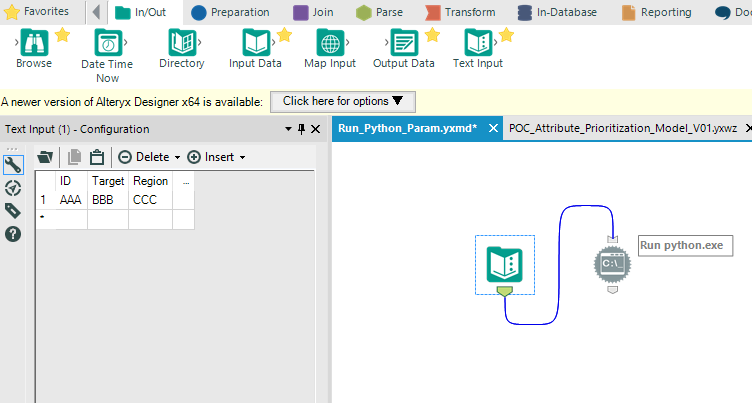
I want to embed my python script in an alteryx workflow for deployment. I wonder if there is a way to pass the alteryx results as parameters that can be later used by python. I attached a simple example here where I want to pass three parameters: ID = "AAA", Target = "BBB", and Region = "CCC". Then in my python script, I have three corresponding variables named "ID", "Target", and "Region". How do I automatically set the three variables in python to have the values specified from the previous workflow? I prefer to put everything under the alteryx WF rather than saving the alteryx table to an external file (e.g., csv file) before loading into python. Is there a decent solution? I would expect this should work similar to passing command line arguments to python.
Thanks!!
Solved! Go to Solution.
- Labels:
-
Input
-
Python
-
Run Command

{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
I believe that the Python tool will read input data as a pandas dataframe when you use Alteryx.read().
This means that you could do some indexing to set your variables in the python script:
dat = Alteryx.read('#1')
id_var = dat['ID'].iloc[0]
target = dat['target'].iloc[0]
region = dat['region'].iloc[0]dat['field_name'] tells python to look only at that column, `,iloc[0]` says look at the value in index location 0.
You could the do `.astype(<whatevertypeyouwant>)` to further transform this.
Note that you can't (and shouldnt) name something "ID", as id is a keyword in Python.
Let me know if this helps or I've missed something,
Cheers!
EDIT: Provided that these are the only 3 variables in the #1 input, I think you could also do the following, however I don't have a python environment on this computer so I cant test it right now:
id_var, target, region = dat.iloc[0]
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
How do I read the alteryx table in if the table is named ("%TEMP%dummy.yxdb")?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
It shouldn't matter what the file is named, what's important is the connection name. If you have only 1 connection into the Python Tool, as in your screen shot, then the table should be named '#1' in Python.
EDIT: Sorry, I misunderstood the screenshot, you're running a Script using the Run Command Tool, not the Python Tool. If you're on Alteryx 2018.3 you should try out the new Python Tool.
Otherwise, I don't think Python has support for .yxdb files. I think your best bet would be saving to a .csv or a SQL table, however if this script will be running many times, this could certainly be a bottleneck and I can see why you're trying to avoid it.
Let me know if you have access to 2018.3, otherwise I'll try to find more information about .yxdb files and Python
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Thanks for your clarification. I am using Alteryx Designer 11.7 and the python 3 miniconda version comes with the alteryx distribution.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
I see, in that case I don't think you'll be able to avoid writing it to a file that Python can read in first.
Either that or you could try to turn your script into an Alteryx macro using the Python SDK.
The only other solution that comes to mind would be reading it into R, turning it to something like a binary .feather file which has very I/O speeds, and then reading that feather into Python, however that doesn't help much to avoid the bottleneck that comes with reading/writing to disk.
Here's a link from StackOverflow: https://stackoverflow.com/questions/41750487/open-alteryx-yxdb-file-in-python
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Thank you for your detailed explanation. Very helpful!
-
Academy
6 -
ADAPT
2 -
Adobe
204 -
Advent of Code
3 -
Alias Manager
78 -
Alteryx Copilot
26 -
Alteryx Designer
7 -
Alteryx Editions
95 -
Alteryx Practice
20 -
Amazon S3
149 -
AMP Engine
252 -
Announcement
1 -
API
1,208 -
App Builder
116 -
Apps
1,360 -
Assets | Wealth Management
1 -
Basic Creator
15 -
Batch Macro
1,559 -
Behavior Analysis
246 -
Best Practices
2,695 -
Bug
719 -
Bugs & Issues
1 -
Calgary
67 -
CASS
53 -
Chained App
268 -
Common Use Cases
3,825 -
Community
26 -
Computer Vision
86 -
Connectors
1,426 -
Conversation Starter
3 -
COVID-19
1 -
Custom Formula Function
1 -
Custom Tools
1,938 -
Data
1 -
Data Challenge
10 -
Data Investigation
3,487 -
Data Science
3 -
Database Connection
2,220 -
Datasets
5,222 -
Date Time
3,227 -
Demographic Analysis
186 -
Designer Cloud
742 -
Developer
4,372 -
Developer Tools
3,530 -
Documentation
527 -
Download
1,037 -
Dynamic Processing
2,939 -
Email
928 -
Engine
145 -
Enterprise (Edition)
1 -
Error Message
2,258 -
Events
198 -
Expression
1,868 -
Financial Services
1 -
Full Creator
2 -
Fun
2 -
Fuzzy Match
712 -
Gallery
666 -
GenAI Tools
3 -
General
2 -
Google Analytics
155 -
Help
4,708 -
In Database
966 -
Input
4,293 -
Installation
361 -
Interface Tools
1,901 -
Iterative Macro
1,094 -
Join
1,958 -
Licensing
252 -
Location Optimizer
60 -
Machine Learning
260 -
Macros
2,864 -
Marketo
12 -
Marketplace
23 -
MongoDB
82 -
Off-Topic
5 -
Optimization
751 -
Output
5,255 -
Parse
2,328 -
Power BI
228 -
Predictive Analysis
937 -
Preparation
5,169 -
Prescriptive Analytics
206 -
Professional (Edition)
4 -
Publish
257 -
Python
855 -
Qlik
39 -
Question
1 -
Questions
2 -
R Tool
476 -
Regex
2,339 -
Reporting
2,434 -
Resource
1 -
Run Command
575 -
Salesforce
277 -
Scheduler
411 -
Search Feedback
3 -
Server
630 -
Settings
935 -
Setup & Configuration
3 -
Sharepoint
627 -
Spatial Analysis
599 -
Starter (Edition)
1 -
Tableau
512 -
Tax & Audit
1 -
Text Mining
468 -
Thursday Thought
4 -
Time Series
431 -
Tips and Tricks
4,187 -
Topic of Interest
1,126 -
Transformation
3,730 -
Twitter
23 -
Udacity
84 -
Updates
1 -
Viewer
3 -
Workflow
9,980
- « Previous
- Next »