Engine Works
Under the hood of Alteryx: tips, tricks and how-tos.- Community
- :
- Community
- :
- Learn
- :
- Blogs
- :
- Engine Works
- :
- The Metadata Macro
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Notify Moderator
Ever gotten to the end of adding some new functionality to a module or app and asked yourself something like “This process used to output 77 columns—why am I seeing only 75?” Or ever have a downstream process break because you inadvertently changed an int to a string? Tracking down and preventing these little data issues can take time away from the fun of developing something new, or the fun of, say, reading more blogs like this one. Enter the new Metadata Macro. [Cue the super hero music.] The Metadata Macro is here to simplify development and save time by alerting you to metadata issues in a quick and easy way. Stick it on the end of a module to ensure your metadata always comes out the way you want it, or use it during development in the middle of a module to ensure that any metadata changes you caused are intentional.
Here’s how it works:
The Metadata Macro accepts 2 inputs:
- 😧 The ‘Data’ stream to be evaluated, (a.k.a. the ‘test’ stream) and
- S: The ‘Standard’ metadata stream—usually a file—which has all the desired/required columns and data types. It needs just 1 row of data on it, and the data itself is ignored on the ‘standard’ stream.
The Metadata Macro essentially does 3 things, detailed further down:
- Counts records on the test data stream.
- Compares the data types of the test data stream against the standard stream.
- Counts nulls and empty strings on all columns in the test data stream.
The macro produces 2 outputs:
- R: The ‘Report’ output indicating the evaluation of the 3 items listed above.
- 😧 The ‘Data’ stream which is simply a duplicate of the input data stream, i.e. the incoming ‘D’ data stream all passes straight through the macro unaltered.
Record counting:
The first thing the macro does is simply count the total number of records on the test stream.
Data type comparison:
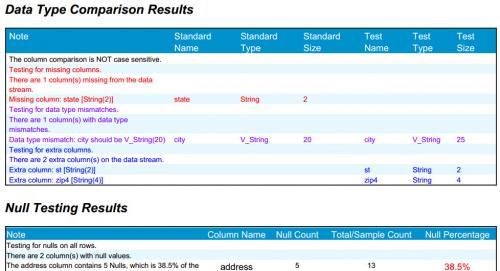
Next, the macro compares data types on the test stream to the standard stream and indicates the following:
- What columns are missing vs. the standard
- What columns are extra vs. the standard
- What columns 'mismatch', i.e. what columns match in name but have different data types than the standard.
By default the macro looks for all 3 metadata differences noted here, but you have the option to select/deselect any of the options above. For example, you may not care about extra columns being on the test stream, but you want to ensure there’s nothing missing or mismatching, so you could deselect the ‘extra columns’ checkbox and leave the other 2 selected. Selecting/deselecting these options will not affect speed performance of the macro.
Null and empty-string counting:
Finally, the macro counts nulls and empty strings on all columns in the test stream. This can be very useful in cases of:
- You’re loading data to a database table that disallows nulls, so you want to prevent a load crash by ensuring there are no nulls on any columns, any rows.
- You’ve modified an existing process and you want an easy way to tell if a change you just made has introduced nulls or empty strings into your data stream.
By default the macro will count nulls and empty strings on all columns on all rows, but you have the option to count them on a sampling of rows, e.g. 1 out of every 100 rows. While counting nulls and empty strings on just a sampling of rows will not catch every single occurrence of a null or empty string, it will perform much faster on large data sets. Depending on the usage scenario, a sampling may be more than enough to capture any issues you’re trapping for. Or for maximum speed you can simply skip null and empty-string counting altogether.
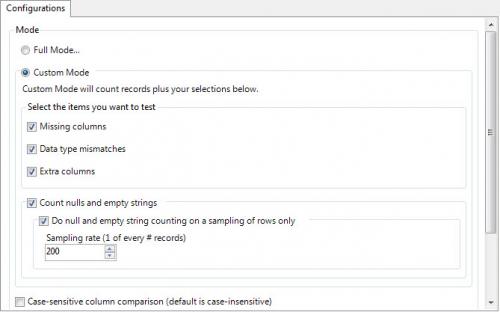
2 Modes:
- Full Mode:
- Count all records (always)
- Look for all 3 kinds of data type differences
- Count nulls/empty strings on all rows
- Custom Mode:
- Count all records (always)
- Look for all, some, or none of the data type differences
- Count nulls/empty strings on all rows, a sampling of rows, or none.
In addition, in either mode you have the option to make the column comparison case-sensitive, e.g. make it so that zip5 will be treated as a different column than ZIP5. This can be helpful for example on loads to relational database management systems (RDBMS’s) that are case sensitive on column names, such as Oracle, vs. other RDBMS’s like SQL Server—and the Alteryx platform itself—which are not case-sensitive.
The macro reports the results in 2 ways:
- All of the detailed results are laid out in the ‘R’ report output of the macro. It reports all the settings you chose on the macro and the results of all tests chosen.
- All of the same notes included in the report output also appear in the Alteryx output window, either as regular messages or as warnings depending on the nature of the note.

This versatility allows you to use the macro the way you want to and still have access to all the same information. Depending on the situation, you may just wish to
- Have a browse tool attached to the macro’s “R” report output, to review at the end of module execution if you’re running manually, or
- Choose the option within the macro to output the report to a pdf for later review, as in automated processes,

or - If you’re logging your processing you can review the logs to find all of the Metadata Macro results.
Two of the most common usages for the Metadata Macro are:
- Put it at the end of commonly-used, (possibly automated) modules, to ensure no metadata issues have crept in.
- Or my favorite usage: refactoring. When updating an existing fully functional module by adding a block of tools, I’ll make the data stream that’s entering the new block of tools be the ‘S’ standard input, and the data stream exiting the new block of tools be the ‘D’ input. This serves as a sort of regression test, and is the quickest way to find out if I’ve made a metadata mistake somewhere within the newly-added block of tools.
Both of these example usages are demonstrated on the demo module for the macro, found at the bottom of this blog post.
Save the MetadataMacro.yxmc in your Alteryx macros folder (C:\Program Files\Alteryx\Engine\RuntimeData\Macros\) and then you’ll find it in the ‘Data Investigation’ tool set in the tool palette the next time you fire up Alteryx.
Enjoy!
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.