Engine Works
Under the hood of Alteryx: tips, tricks and how-tos.- Community
- :
- Community
- :
- Learn
- :
- Blogs
- :
- Engine Works
- :
- Coming in 7.0: XML Parsing
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Notify Moderator
This blog post is referring to functionality that will be in our next major release. Beta users can preview this feature in the latest Beta release of Alteryx. Please send an email to products@alteryx.com if you are interested in participating in our Beta program.
Reading XML files has probably been the single most requested Alteryx feature that we have never done. The issue is that XML is inherently not a data table format. XML describes hierarchical data which is inherently incompatible with the way Alteryx streams data as records. Other tools (like Excel) require either an XML Schema or that the user has an extensive knowledge of XPath, which in many ways is as complicated as Regular Expressions. The specialized XML knowhow are not skills that a typical Alteryx user can be expected to have. We wanted to come up with a way that reading XML would be intuitive to an Alteryx user.
Let's look at some simple XML (from Wikipedia😞
<feed xmlns="http://www.w3.org/2005/Atom">
<title>Example Feed</title>
<subtitle>A subtitle.</subtitle>
<link href="http://example.org/feed/" rel="self" />
<link href="http://example.org/" />
<id>urn:uuid:60a76c80-d399-11d9-b91C-0003939e0af6</id>
<updated>2003-12-13T18:30:02Z</updated>
<author>
<name>John Doe</name>
<email>johndoe@example.com</email>
</author>
<entry>
<title>Atom-Powered Robots Run Amok</title>
<link href="http://example.org/2003/12/13/atom03" />
<link rel="alternate" type="text/html" href="http://example.org/2003/12/13/atom03.html"/>
<link rel="edit" href="http://example.org/2003/12/13/atom03/edit"/>
<id>urn:uuid:1225c695-cfb8-4ebb-aaaa-80da344efa6a</id>
<updated>2003-12-13T18:30:02Z</updated>
<summary>Some text.</summary>
</entry>
</feed>
You probably want to parse out the<entry> tags (there are typically more than 1) and their information, but notice the <link tags inside? The only way to make sense of this is with a relational table structure consisting of 2 tables (streams.)
Again, trying to make reading XML as simple as possible, there are only 3 configuration questions:
- XML Element: This is the element we want to read from the XML file. If left blank, Alteryx will guess and often get it right.
- Return Child Values: If true, then fields will be created based on all children 1 level deep from the XML Element
- Return Outer XML: If true, then the Outer XML of the XML Element will be returned as a string field. Also if Return Child Values it will separately return the Outer XML of child elements. This is useful for further parsing.
Reading the atom XML above, with XML Element=="entry" and both Return Child Values and Return Outer XML set to true, we get the following table (some fields have been deselected):
| title | id | updated | summary | Entry_OuterXML |
|---|---|---|---|---|
| Atom-Powered Robots Run Amok | urn:uuid:1225c695-cfb8-4ebb-aaaa-80da344efa6a | 2003-12-13T18:30:02Z | Some text. | <entry><title>Atom-Powered Robots Run Amok</title>... |
With very little configuration, we have quickly parsed out the summary information we need from the Atom feed. Using the companion XML Parse tool, which can be found in the developer tools toolbox, we can quickly parse out the link tags and get another table of info about them (again, extra fields have been removed):
| id | href | rel | type |
|---|---|---|---|
| urn:uuid:1225c695-cfb8-4ebb-aaaa-80da344efa6a | http://example.org/2003/12/13/atom03 | [NULL] | [NULL] |
| urn:uuid:1225c695-cfb8-4ebb-aaaa-80da344efa6a | http://example.org/2003/12/13/atom03.html | alternate | text/html |
| urn:uuid:1225c695-cfb8-4ebb-aaaa-80da344efa6a | http://example.org/2003/12/13/atom03/edit | edit | [NULL] |
A very simple module, with just a few tools was able to parse out this data very effectively. The good news is that it is very adaptable if future files have different children or different #'s of elements, it should all just work.
Performance & size considerations
The other thing that we wanted to make sure of was that there were no size limitations and that the speed was pretty good. This was another thing that ruled out using any sort of XPath. Since XPath allows for backwards and forward references within the file, it basically requires the entire file to be in memory.
We used a parser that looks at the data as it is parsing (a SAX Parser) and handles each piece without ever needing the entire document in memory. Since we are automatically finding out what fields (and field sizes) to create based on the content, this ends up requiring 2 passes through the data. One to figure out what set of fields to return and another to return the actual data. Since this style of parsing is so efficient, it is still very fast.
For texting purposes though, we wanted to find some very large XML files:
A search online found some samples of large XML files:
http://www.grants.gov/search/XMLExtract.do
- 52MB XML File
- 2.4 Seconds to Parse
- Default configuration found all the relevant data!
Data sample:
| ... | EstimatedFunding | AwardCeiling | AwardFloor | AgencyMailingAddress | FundingOppTitle | ... |
|---|---|---|---|---|---|---|
| 500000 | 10000 | 0 | Contact Information | Commodity Partnerships Small Sessions Program | ||
| 60000 | 60000 | 60000 | tekla_vines@nps.gov | NATIONAL PARK SERVICE RECOVERY ACT Whiskeytown National Recreation Area, Repair and Maintain Parkwide Trails |
http://dumps.wikimedia.org/enwiki/latest/enwiki-latest-abstract1.xml
- 650MB File
- 18 seconds to Parse
- Default configuration found the top level of relevant data. There is a sub level of data containing lists of links for each. A second level parse to pull out all the sub links as well makes the parse time 1 minutes 9 seconds.
Data Sample:
| ... | title | url | abstract | ... |
|---|---|---|---|---|
| Wikipedia: Anarchism | http://en.wikipedia.org/wiki/Anarchism | Anarchism is a political philosophy which considers the state undesirable unnecessary, and harmful, and instead promotes a stateless society, or anarchy. | ||
| Wikipedia: Autism | http://en.wikipedia.org/wiki/Autism | ICD9 = 299.00 |
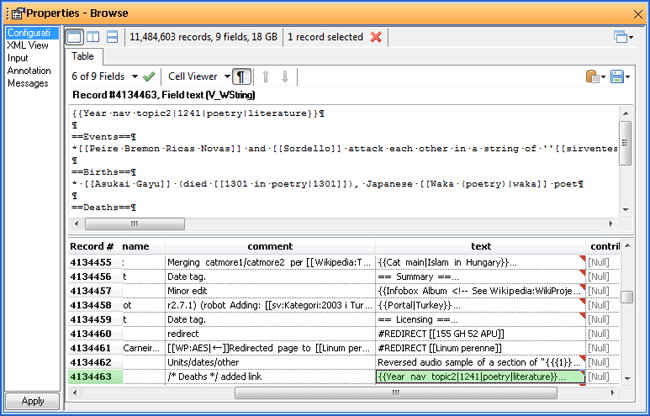
http://dumps.wikimedia.org/enwiki/latest/enwiki-latest-pages-articles.xml.bz2
- 32GB XML File!
- 40 Minutes to parse at 1 level.
- 92 minutes to parse at 3 different levels
Data Sample:
The files from this article can be found here.
Remember that this will require the latest beta (or newer) of Alteryx 7.0 as of August 2011.
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.