Alteryx Designer Desktop Ideas
Share your Designer Desktop product ideas - we're listening!Submitting an Idea?
Be sure to review our Idea Submission Guidelines for more information!
Submission Guidelines- Community
- :
- Community
- :
- Participate
- :
- Ideas
- :
- Designer Desktop
Featured Ideas
Hello,
After used the new "Image Recognition Tool" a few days, I think you could improve it :
> by adding the dimensional constraints in front of each of the pre-trained models,
> by adding a true tool to divide the training data correctly (in order to have an equivalent number of images for each of the labels)
> at least, allow the tool to use black & white images (I wanted to test it on the MNIST, but the tool tells me that it necessarily needs RGB images) ?
Question : do you in the future allow the user to choose between CPU or GPU usage ?
In any case, thank you again for this new tool, it is certainly perfectible, but very simple to use, and I sincerely think that it will allow a greater number of people to understand the many use cases made possible thanks to image recognition.
Thank you again
Kévin VANCAPPEL (France ;-))
Thank you again.
Kévin VANCAPPEL
Hi all!
Based on the title, here's some background information: SHAPLEY Values
Currently, one way of doing so is to utilize the Python tool to write out the script and install the package. However, this will require running Alteryx as an administrator in order to successfully load, test, and run the script. The problem is, a substantial number of companies do not grant such privileges to their Alteryx teams to run as administrator fully as it will always require admin credentials to log in to even open Alteryx after closing it.
I am aware that there is a macro covering SHAP but I've recently tested it and it did not work as intended, plus it covers non-categorical values as determinants only, thereby requiring a conversion of categorical variables into numeric categories or binary categories.
It will be nice to have a built in Alteryx ML tool that does this analysis and produces a graph akin to a heat map that showcases the values like below:

By doing so, it adds more value to the ML suite and actually helps convince companies to get it.
Otherwise teams will just use Python and be done with it, leaving only Alteryx as the clean-up ETL tool. It leaves much to be desired, and can leave some teams hanging.
I hope for some consideration on this - thank you.
-
Category Data Investigation
-
Category Machine Learning
-
Category Predictive
-
Desktop Experience
Hello!
I appreciate this is a very underused element of Alteryx Functionality, however, I have noticed a few issues with the description of fields.
Firstly, if you set a description on a field within a select tool:

And then attempt to clear the description later in the workflow (in another select tool), you cannot. When you delete the description, it will clear back to the original value (in this case, 'test'):

This can be easily recreated, and can be more applicable to yxdb outputs that contain the description of fields. In that scenario, you cannot go back to the previous select tool and remove the description. The closest you can come to easily clearing the description is replacing it with a space ' '.
As a secondary issue, as current the score tool removes field descriptions and overrides the source. For example if I open the Score tool example workflow, and add a select tool/description:

You can see the meta data going into the score tool:

But unfortunately the output of the tool looks like:

Showing that it has completely removes the descriptions, and also replaced all of the 'source' information. My suggestion for this would be that it would not replace the source information or descriptions.
Thirdly - and quite a niche issue, but an int64 field specifically will break when the description differs between the data and the model.
Again, easy to recreate within the Ccore tool example workflow. Apply a Select tool to both streams, setting 'First_Years' to an int64. Within the bottom stream (the model creation), set a description, in this case, 'test':

Make sure to leave the top streams description blank.
Run the workflow, observe the error:
Error: Score (106): Score: The variable testFirst_Years is missing from the input data stream.
Interestingly, it seems to be using the description as part of the name within the Score tool, which is causing issue when the descriptions differ. My suggestion for this would be that it would not utilise descriptions at all.
Kind Regards,
Owen
-
Category Predictive
-
Category Preparation
-
Desktop Experience
Alteryx hosting CRAN
Installing R packages in Alteryx has been a tricky issue with many posts over the years and it fundamentally boils down to the way the install.packages() function is used; I've made a detailed post on the subject. There is a way that Alteryx can help remedy the compatibility challenge between their updates of Predictive Tools and the ever-changing landscape that is open-source development. That way is for Alteryx to host their own CRAN!
The current version of Alteryx runs R 4.1.3, which is considered an 'old release', and there are over 18,000 packages on CRAN for this version of R. By the time you read this post, there is likely a newer version of one of these packages that the package author has submitted to the R Foundation's CRAN. There is also a good chance that package isn't compatible with any Alteryx tool that uses R. What if you need that package for a macro you've downloaded? How do you get the old version, the one that is compatible? This is where Alteryx hosting CRAN comes into full fruition.
Alteryx can host their own CRAN, one that is not updated by one of many package authors throughout its history, and the packages will remain unchanged and compatible with the version of Predictive Tools that is released. All we need to do as Alteryx users is direct install.packages() to the Alteryx CRAN to get our new packages, like so,
install.packages(pkg_name, repo = "https://cran.alteryx.com")
There is a R package to create a CRAN directory, so Alteryx can get R to do the legwork for them. Here is a way of using the miniCRAN package,
library(miniCRAN)
library(tools)
path2CRAN <- "/local/path/to/CRAN"
ver <- paste(R.version$major, strsplit(R.version$minor, "\\.")[[1]][1], sep = ".") # ver = 4.1
repo <- "https://cran.r-project.org" # R Foundation's CRAN
m <- available.packages() # a matrix of all packages and their meta data from repo
pkgs4CRAN <- m[,"Package"] # character vector of all packages from repo
makeRepo(pkgs = pkgs4CRAN, path = path2CRAN, type = c("win.binary", "source"), repos = repo) # makes the local repo
write_PACKAGES(paste(path2CRAN, "bin/windows/contrib", ver, sep = "/"), type = "win.binary") # creates the PACKAGES file for package binaries
write_PACKAGES(paste(path2CRAN, "src/contrib", sep = "/"), type = "source") # creates the PACKAGES files for package sources
It will create a directory structure that replicates R Foundation's CRAN, but just for the version that Alteryx uses, 4.1/.
Alteryx can create the CRAN, host it to somewhere meaningful (like https://cran.alteryx.com), update Predictive Tools to use the packages downloaded with the script above and then release the new version of Predictive Tools and announce the CRAN. Users like me and you just need to tell the R Tool (for example) to install from the Alteryx repo rather than any others, which may have package dependency conflicts.
This is future-proof too. Let's say Alteryx decide to release a new version of Designer and Predictive Tools based on R 4.2.2. What do they do? Download R 4.2.2, run the above script, it'll create a new directory called 4.2/, update Predictive Tools to work with R 4.2.2 and the packages in their CRAN, host the 4.2/ directory to their CRAN and then release the new version of Designer and Predictive Tools.
Simple!
-
API SDK
-
Category Developer
-
Category Machine Learning
-
Category Predictive
Hello!
I remember a while ago running into a peculiar error:
'The R.exe exit code (4294967295) indicted an error'. This was peculiar, as the data output was still seemingly correct, however, the error made me double-check the community for answers.
There are some very technical sources here:
https://community.alteryx.com/t5/Alteryx-Designer-Discussions/R-tool-Fake-Errors/td-p/25163
https://community.alteryx.com/t5/Alteryx-Designer-Discussions/Boosted-Model-Error/td-p/5509
but in short, this seems to be caused by a return code from C++ libraries, being understood by R as an error. Its a very inconsistent error, typically caused by low memory. This creates what most call a 'fake error' - the code runs perfectly fine, but seems to produce an error that doesn't actually indicate anything wrong.
Within those threads, its also stated that calling the garbage collection function (gc()) does tend to solve the problem on R exit, however this requires a user to understand basic R, and have access to the macro to be able to change the code - thus making predictive analytics more intimidating than it already is for new Alteryx users.
The first occurrence of this error seems to be way back in 2015, however the error is still being reported by users (see posts from 2020 and 2021):
https://community.alteryx.com/t5/Alteryx-Designer-Discussions/Password-protected-Excel-files-R-solut...
https://community.alteryx.com/t5/Alteryx-Designer-Knowledge-Base/Error-The-R-exe-exit-code-n-indicat...
An important issue of these 'fake errors', is not only that they cause confusion, but also that they will cause analytic apps and server workflows to not work as expected, and stop running depending on the configuration.
My suggestion would be to revisit this issue, as by my understanding it occurs inconsistently, and calling garbage collection does not always seem to fix it. Even if the Error message is still created, it may be worth Alteryx suppressing these errors, in the case they are not real errors.
Steps to reproduce:
(as mentioned, its very inconsistent)
1. Open the Boosted Model example workflow
2. *10 the number of maximum trees in the model, in the boosted model configuration (Model customization)
3. Run the workflow, inspect the results (which are seemingly correct), and the error message in the results window.

Hope this helps!
TheOC
-
Category Predictive
-
Desktop Experience
-
Category Predictive
-
Desktop Experience
I would like to request that the Python tool metadata either be automatically populated after the code has run once, or a simple line of code added in the tool to output the metadata. Also, the metadata needs to be cached just like all of the other tools.
As it sits now, the Python tool is nearly unusable in a larger workflow. This is because it does not save or pass metadata in a workflow. Most other tools cache temporary metadata and pass it on to the next tool in line. This allows for things like selecting columns and seeing previews before the workflow is run.
Each time an edit is made to the workflow, the workflow must be re-run to update everything downstream of the Python tool. As you can imagine, this can get tedious (unusable) in larger workflows.
Alteryx support has replied with "this is expected behavior" and "It is giving that error because Alteryx is
doing a soft push for the metadata but unfortunately it is as designed."
-
Category Predictive
-
Desktop Experience
-
Tool Improvement
Would be extremely useful if the Summarize Tool had an option in the numeric menu to Standardize the data. More often than not, data sets will not have the same count of variables which makes the comparison analysis meaningless. Currently, there is no easy way to Standardize the data without using the K-Centroids Cluster Analysis tool or standardize_unit interval supporting macro.
-
Category Predictive
-
Desktop Experience
XGboost regression is now the benchmark for every Kaggle competition and seems to consistently outperform random forest, spline regression, and all of the more basic models. For those of us using predictive modeling on a regular basis in our actual work, this tool would allow for a quick improvement in our model accuracy. And I think, from a marketing standpoint, having a core group of users competing in Kaggle using Alteryx would be a great way to show off Alteryx's power.
It is readily available as an R package: https://cran.r-project.org/web/packages/xgboost/index.html
-
Category Predictive
-
Desktop Experience
This idea arose recently when working specifically with the Association Analysis tool, but I have a feeling that other predictive tools could benefit as well. I was trying to run an association analysis for a large number of variables, but when I was investigating the output using the new interactive tools, I was presented with something similar to this:

While the correlation plot draws your high to high associations, the user is unable to read the field names, and the tooltip only provides the correlation value rather than the fields with the value. As such, I shifted my attention to the report output, which looked like this:

While I could now read everything, it made pulling out the insights much more difficult. Wanting the best of both worlds, I decided to extract the correlation table from the R output and drop it into Tableau for a filterable, interactive version of the correlation matrix. This turned out to be much easier said than done. Because the R output comes in report form, I tried to use the report extract macros mentioned in this thread to pull out the actual values. This was an issue due to the report formatting, so instead I cracked open the macro to extract the data directly from the R output. To make a long story shorter, this ended up being problematic due to report formats, batch macro pathing, and an unidentifiable bug.
In the end, it would be great if there was a “Data” output for reports from certain predictive tools that would benefit from further analysis. While the reports and interactive outputs are great for ingesting small model outputs, at times there is a need to extract the data itself for further analysis/visualization. This is one example, as is the model coefficients from regression analyses that I have used in the past. I know Dr. Dan created a model coefficients macro for the case of regression, but I have to imagine that there are other cases where the data is desired along with the report/interactive output.
-
Category Data Investigation
-
Category Predictive
-
Desktop Experience
Unsupervised learning method to detect topics in a text document.
Helpful for users interested in text mining.
-
Category Data Investigation
-
Category Predictive
-
Desktop Experience
Sometimes, as a sanity check, I would like to be able to model only the mean of my data set, i.e. I would like to use a predictive tool with no predictors included. The result would be a model with only an intercept, and this value would be the mean of the target variable. This would not be an important feature for final models, of course, but when starting to look at a data set and build up a model, it can be useful to first ensure the model is producing the expected output in the simplest case.
Note, this can be achieved when just one predictor is included, but it takes some math (see below), so it would be nice to be able to have this as a built-in option.

-
Category Predictive
-
Desktop Experience
I'm really liking the new assisted modelling capabilities released in 2020.2, but it should not error if the data contains: spatial, blob, date, datetime, or datetime types.
This is essentially telling the user to add an extra step of adding a select before the assisted modelling tool and then a join after the models. I think the tool should be able to read in and through these field types (especially dates) and just not use them in any of the modelling.
An even better enhancement would be to transform date as part of the assisted modelling into something usable for the modelling (season, month, day of week, etc.)

{kind=link}
-
Category Predictive
-
Desktop Experience
-
Machine Learning
-
Tool Improvement
Python pandas dataframes and data types (numpy arrays, lists, dictionaries, etc.) are much more robust in general than their counterparts in R, and they play together much easier as well. Moreover, there are only a handful of packages that do everything a data scientist would need, including graphing, such as SciKit Learn, Pandas, Numpy, and Seaborn. After utliizing R, Python, and Alteryx, I'm still a big proponent of integrating with the Python language much like Alteryx has integrated with R. At the very least, I propose to create the ability to create custom code such as a Python tool.
-
API SDK
-
Category Data Investigation
-
Category Developer
-
Category Predictive
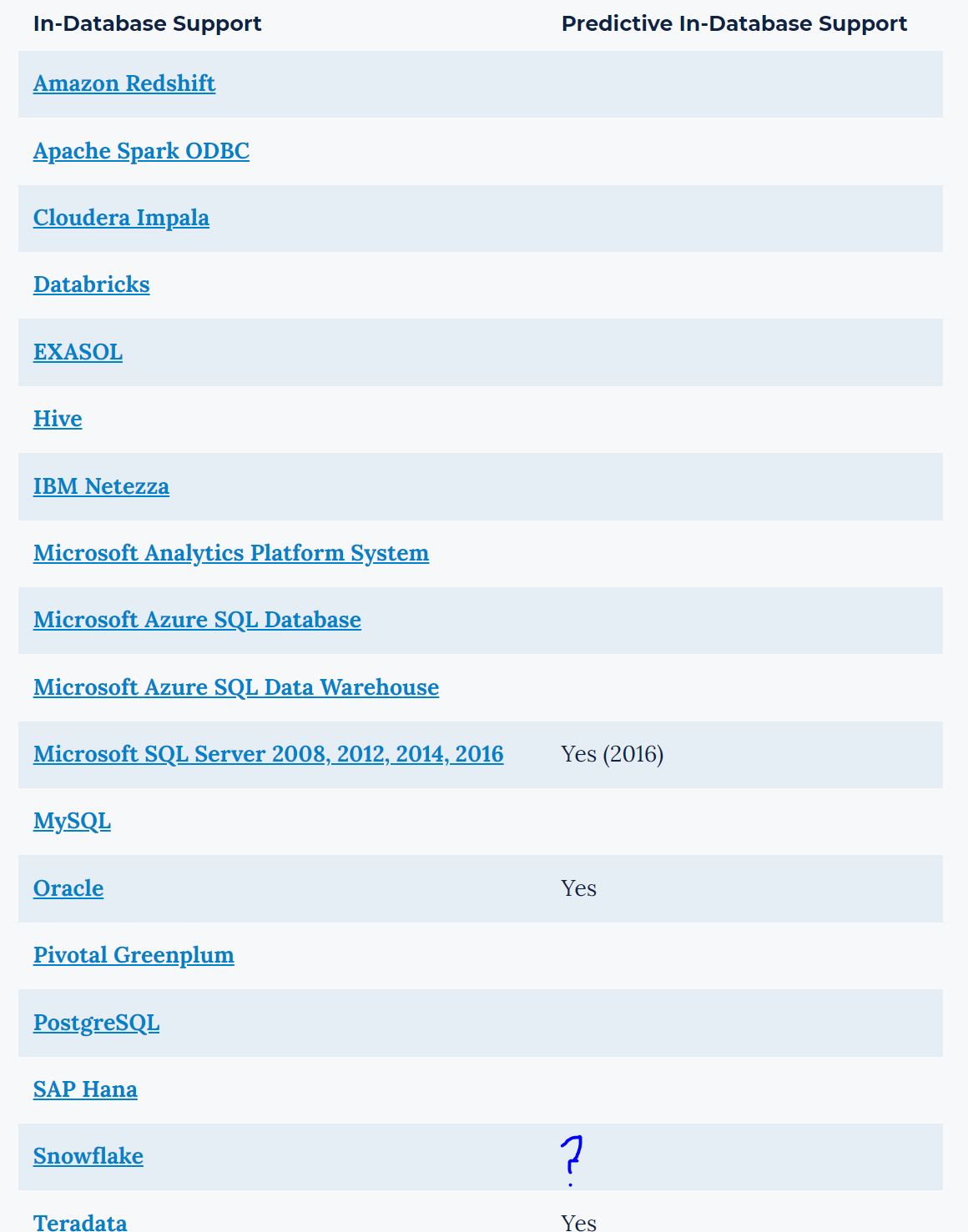
Hi Alteryx,
Can we get the R tools/models to work in database for SNOWFLAKE.
In-Database Overview | Alteryx Help
I understand that Snowflake currently doesn't support R through their UDFs yet; therefore, you might be waiting for them to add it.
I hear Python is coming soon, which is good & Java already available..
However, what about the ‘DPLYR’ package? https://db.rstudio.com/r-packages/dplyr/
My understanding is that this can translate the R code into SQL, so it can run in-DB?
Could this R code package be appended to the Alteryx R models? (maybe this isn’t possible, but wanted ask).
Many Thanks,
Chris
{kind=link}
-
Category In Database
-
Category Predictive
-
Data Connectors
-
Desktop Experience
So - with Challenge 111 - many folk used the Optimization tool
… and Joe has done a great training on this here
https://community.alteryx.com/t5/Live-Training/Live-Training-Prescriptive-Optimization/m-p/44779
But it's still to hard to use. It requires you to have pre-knowledge of a bunch of parameters and different types of knowledge.
Can we improve the interface on this tool so that it can be used by folk who do not have a background in R - for example, take all the different inputs, and make them parameterized on drop-down boxes or input boxes on the tool?
Thank you all
S
CC: @JoeM
-
Category Predictive
-
Desktop Experience
Is there a reason why Alteryx does not include hierarchical clustering?
Well it's sort of slow especially with huge data sets, computation effort increases cubic, but then when you need to do two step clustering,
"creating more than enough k-means clusters and joining cluster centers with hierarchical clustering" it seems to be a must...
P.s. Knime, SPSS modeler, SAS, Rapidminer has it already...
-
Category Predictive
-
Desktop Experience
It would be nice if this option would take you to the correct download page relative to the version the user has installed. Currently, this always loads the download page for the current version which is confusing for users of a company who are still required to use an older version.

-
Category Predictive
-
Desktop Experience
When working with R code and errors occur, the application needs to show which line the error happened on.
-
Category Predictive
-
Desktop Experience
Designer should support statistical testing tools that ignore data distribution and support Statistical Learning methods.
Alteryx already supports resampling for predictive modeling with Cross-Validation.
Resampling tools for bootstrap and permutation tests (supporting with or without replacement) should be tools for analysts and data scientists alike that assess random variability in a statistic without needing to worry about the restrictions of the data's distribution, as is the case with many parametric tests, most commonly supported by the t-test Tool in Alteryx. With modern computing power the need for hundred-year-old statistical sampling testing is fading: the power to sample a data set thousands of times to compare results to random chance is much easier today.
The tool's results could include, like R, outputs of not only the results histogram but the associated Q-Q plot that visualizes the distribution of the data for the analyst. This would duplicate the Distribution Analysis tool somewhat, but the Q-Q plot is, to me, a major missing element in the simplest visualization of data. This tool could be very valuable in terms of feeding the A/B Test tools.
-
Category Data Investigation
-
Category Predictive
-
Desktop Experience
Up to version 10.0 I could open pretty much all analytics tools as a macro, to tweak things in R or in the macro workflow to get the results in a way most useful to us.
But apparently with Alteryx 11.0 the newer tools does not have that option, Although we can still access the older versions of those tools and still open them as macro but I don't understand (may be because they have interactive report option) why that is being killed in the newer versions?
Most of the newer versions have new features, like Linear Regression now support elastic net and cross validation etc.. but I still want to be able to go in to them to tweak them.
-
Category Macros
-
Category Predictive
-
Desktop Experience
- New Idea 205
- Accepting Votes 1,839
- Comments Requested 25
- Under Review 148
- Accepted 55
- Ongoing 7
- Coming Soon 8
- Implemented 473
- Not Planned 123
- Revisit 68
- Partner Dependent 4
- Inactive 674
-
Admin Settings
19 -
AMP Engine
27 -
API
11 -
API SDK
217 -
Category Address
13 -
Category Apps
111 -
Category Behavior Analysis
5 -
Category Calgary
21 -
Category Connectors
239 -
Category Data Investigation
75 -
Category Demographic Analysis
2 -
Category Developer
206 -
Category Documentation
77 -
Category In Database
212 -
Category Input Output
631 -
Category Interface
236 -
Category Join
101 -
Category Machine Learning
3 -
Category Macros
153 -
Category Parse
74 -
Category Predictive
76 -
Category Preparation
384 -
Category Prescriptive
1 -
Category Reporting
198 -
Category Spatial
80 -
Category Text Mining
23 -
Category Time Series
22 -
Category Transform
87 -
Configuration
1 -
Data Connectors
948 -
Desktop Experience
1,491 -
Documentation
64 -
Engine
121 -
Enhancement
274 -
Feature Request
212 -
General
307 -
General Suggestion
4 -
Insights Dataset
2 -
Installation
24 -
Licenses and Activation
15 -
Licensing
10 -
Localization
8 -
Location Intelligence
79 -
Machine Learning
13 -
New Request
175 -
New Tool
32 -
Permissions
1 -
Runtime
28 -
Scheduler
21 -
SDK
10 -
Setup & Configuration
58 -
Tool Improvement
210 -
User Experience Design
165 -
User Settings
73 -
UX
220 -
XML
7
- « Previous
- Next »
- vijayguru on: YXDB SQL Tool to fetch the required data
- Fabrice_P on: Hide/Unhide password button
- cjaneczko on: Adjustable Delay for Control Containers
-
 Watermark
on:
Dynamic Input: Check box to include a field with D...
Watermark
on:
Dynamic Input: Check box to include a field with D...
- aatalai on: cross tab special characters
- KamenRider on: Expand Character Limit of Email Fields to >254
- TimN on: When activate license key, display more informatio...
- simonaubert_bd on: Supporting QVDs
- simonaubert_bd on: In database : documentation for SQL field types ve...
- guth05 on: Search for Tool ID within a workflow