Alteryx Designer Desktop Ideas
Share your Designer Desktop product ideas - we're listening!Submitting an Idea?
Be sure to review our Idea Submission Guidelines for more information!
Submission Guidelines- Community
- :
- Community
- :
- Participate
- :
- Ideas
- :
- Designer Desktop: Hot Ideas
Featured Ideas
Hello,
After used the new "Image Recognition Tool" a few days, I think you could improve it :
> by adding the dimensional constraints in front of each of the pre-trained models,
> by adding a true tool to divide the training data correctly (in order to have an equivalent number of images for each of the labels)
> at least, allow the tool to use black & white images (I wanted to test it on the MNIST, but the tool tells me that it necessarily needs RGB images) ?
Question : do you in the future allow the user to choose between CPU or GPU usage ?
In any case, thank you again for this new tool, it is certainly perfectible, but very simple to use, and I sincerely think that it will allow a greater number of people to understand the many use cases made possible thanks to image recognition.
Thank you again
Kévin VANCAPPEL (France ;-))
Thank you again.
Kévin VANCAPPEL
I’ve been using the Regex tool more and more now. I have a use case which can parse text if the text inside matches a certain pattern. Sometimes it returns no results and that is by design.
Having the warnings pop up so many times is not helpful when it is a genuine miss and a fine one at that.
Just like the Union tool having the ability to ignore warnings, like Dynamic Rename as well, can we have the ignore function for all parse tools?
That’s the idea in a nutshell.
The TO field (and I assume other fields) in the Email tool seem to have a 254 character limit - this should be increased heavily as there are many distribution lists that will go above this character limit!
- Solved: Email tool recipients list truncating emails - Alteryx Community
- Solved: Email Widget: Cut off all the emails in the "To" r... - Alteryx Community
- Re: Email Address Truncated in the "To" Field - Alteryx Community
A distribution list works but is not ideal. Thumbs up if you like this idea!
Hello all,
We all know for sure that != is the Alteryx operator for inequality. However, I suggest the implementation of <> as an other operator for inequality. Why ?
<> is a very common operator in most languages/tools such as SQL, Qlik or Tableau. It's by far more intuitive than != and it will help interoperability and copy/paste of expression between tools or from/to in-database mode to/from in-memory mode.
Best regards,
Simon
Hello,
Working on Dataiku DSS and there is a cool feature : they can tag tools, parts of a worklow.. and then emphasize the tools tagged.

Best regards,
Simon
Hello all,
The reasons why I would the cadence to be back to quarter release :
-for customers, a quarter cadence means waiting less time to profit of the Alteryx new features so more value
-quarter cadence is now an industry standard on data software.
-the new situation of special cadence creates a lot of frustration. And frustration is pretty bad in business.
-for partners, the new situation means less customer upgrade opportunities, so less cash but also less contacts with customers.
Best regards,
Simon
Hello all,
When using in-database, all you have in select or formula are the Alteryx field types (V_String, etc..).
However, since you're mostly writing in database, in the end, there is a conversion of Alteryx field types to real SQL field types (like varchar). But how is it done ? As of today, it's a total black box. Some documentation would be appreciated.
Best regards,
Simon
Hi everyone! I have been trying to find a way to do this without creating a new idea, but I have decided to make it an official 'Idea' to see if there is anyone else that might appreciate a feature like this (or has found there own way to do it!)
Do your workflows look like this...
.png")
but you wish they could look like this?
.png")
Well... they can with your help!
Okay, I might be crazy...but its worth a shot.
While I understand this is an extremely niche issue, in my experience, it can become very difficult to trace the data through unmanaged lines in large workflows. I think it will be great to cable manage canvas lines so workflows are easier to follow. Heck, while I am already at it, I think it we should all start calling these canvas lines cables... They don't carry electricity, but they sure do carry data!
Here is an example I created in Alteryx using select tools and containers:

Hello all,
A few years ago, I asked for svg support in Alteryx (https://community.alteryx.com/t5/Alteryx-Designer-Desktop-Ideas/svg-support-for-icon-comment-image-e... ). Now, there is Alteryx Designer Cloud with other icons... already in svg !
So I think it would be great to have an harmonization between designer and cloud.
Best regards,
Simon

I would like a way to disable all containers within a workflow with a single click. It could be simply disable / enable all or a series of check boxes, one for each container, where you can choose to disable / enable all or a chosen selection.
In large workflows, with many containers, if you want to run a single container while testing it can take a while to scroll up and down the workflow disabling each container in turn.
Hello all,
It's really frustrating to have an "alteryx field type" in In-Database Select. It doesn't even make sense since we're manipulating only data in SQL database where those types does not exist. What we should see is the SQL field type.
Best regards,
Simon

Everyone knows the importance of adding the appropriate controls and governance to your workflows - and often, this means including events that will generate notifications if a workflow is running with errors.
But who is the audience of that email? If it's not a developer, will that person know what they are reading and where to focus?
How about a developer that would like to customize the message that the end user will receive?
Porting some existing functionality from other tools in the Alteryx toolkit to the Events page could easily provide added flexibility to event generation:
1) Add a formatting bar to the tool like shown in the image below
-- Style changes
-- Alignment
-- Highlighting
-- Coloring
-- Images
2) Add a function bar to the tool like shown in the image below
-- Ability to view all available variables
-- Ability to apply formulas using variables
-- Ability to save formulas

What do you think? Give this post a thumbs up if you find the post helpful!
Hello all,
We all have experienced these last years the now famous concept of hide/unhide password :
Here a few examples of it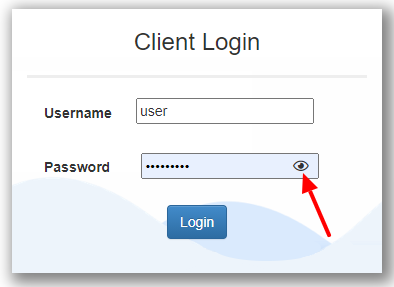
I would like this exact principle everywhere we have a password on Alteryx.
Best regards,
Simon

Hey all,
I don't know about you, but I have always had trouble hovering the mouse over the Results window pane trying to get the resize icon to appear. It seems like you need surgeon level precision to find the icon! 😷
I love Designer and want to see it be the best it can possibly be. I feel like increasing the clickable/hovering area for this resize would be amazingly helpful!
Just wanted to see if we could get some community momentum going in order to get some developer eyes on this issue. 🙂
Please help by bumping/upvoting this thread!

-K
Migrated this from another thread. Some folks tagged from the original post :)
@cpatrickwk @caltang @afellows @MRod @alexnajm @ericsmalley @MilindG @Prometheus @innovate20
Allow users the ability to add a delay on the connection between Control Container tools. I frequently have to rerun workflows that use the control container because the workflow has not registered that the file was properly closed on outputting from one output tool to the next. The network drives haven't resolved and show that the file is still open while its moved on to the next control container. Users should have an option in the Configuration screen to add a delay before a signal is sent for the next container to run.
In the past I was able to use a CReW tool (Wait a Second) in conjunction with the Block Until Done tool to add the delay in manually. But I have since converted all of my workflows over to Control Containers. Since then half of the times the workflow has run I encounter the following errors.


Alteryx offers the ability to add new formulae (e.g. the Abacus addin) and new tools (e.g. the marketplace; custom macros etc) - which is a very valuable and valued way to extend the capability of the platform.
However - if you add a new function or tool that has the same name as an existing function / tool - this can lead to a confusing user experience (a namespace conflict)
Would it be possible to add capability to Alteryx to help work around this - two potential vectors are listed below:
- Check for name conflicts when loading tools or when loading Alteryx - and warn the user. e.g. "The Coalesce function in package CORE Alteryx conflicts with the same function name in XXX package - this may cause mysterious behaviours"
- Potentially allow prefixes to address a function if there are same names - e.g. CoreAlteryx.Coalesce or Abacus.Coalesce - and if there is a function used in a function tool in a way that is ambiguous (e.g. "Coalesce") then give the user a simple dialog that allows them to pick which one they meant, and then Alteryx can self-cleanup.
Similar to the setting that you have in many individual tools (join, append, select, et al) where you can go to options and choose to "forget missing fields" it would be nice where you could go to options for the entire flow and "forget missing fields".
This would remove the headache that you have with large flows where you make a change(s) then have to go back through each and every tool to "forget" within that tool. Yes you could still do it individually, but if you chose, you could also do it universally for the entire flow all at once to all the 'missing fields'.
The idea is quite simple. I am sure a lot of Alteryx enthusiasts use containers frequently. These can also be color coded for better overview and readability of your workflows. However, while connections between tools can be named, they cannot be colored.
Therefore, this idea is very simple. Adding an option to color these connections. This would allow for even more readability of workflows. Especially if a workflow contains multiple separate streams of data, this could help to navigate and keep track of how and where data is flowing.

Currently if I have a connection between two tools as per the example below:

I can drag and drop a new tool on the connection between these tools to add it in:

And designer updates the connections nicely, however if I select multiple tools and try and collectively drop them inbetween, on a connection then it won't allow me to do this, and will move the connection out of the way so it doesn't cause an overlap.

Therefore as a QoL improvement it would be great if there was a multi-drop option on connections between tools.
Hello all,
ADBC is a database connection standard (like ODBC or JDBC) but specifically designed for columnar storage (so database like DuckDB, Clickhouse, MonetDB, Vertica...). This is typically the kind of stuff that can make Alteryx way faster.
more info in https://arrow.apache.org/blog/2023/01/05/introducing-arrow-adbc/
Here a benchmark made by the guys at DuckDB : 38x improvement
https://duckdb.org/2023/08/04/adbc.html

Best regards,
Simon
We all know and love the Comment tool. It's a staple of every workflow to give users an idea of the workflow in finer details. It's a powerful tool - it helps adds context to tools and containers, and it also serves as an image placeholder for us to style our workflows as aesthetically pleasing as possible.
Now, the gensis of this idea is inspired by this post and subsequent research question here.
The Comment Tool today allows you to:
- Write your text and provide context / documentation to your workflow
- Style its shape
- Style its font, colour, and background colour
- Align the text
- Put an image to your workflow

But it would provide way more functionality if it had the capabilities of another awesome Alteryx tool that is not so frequently mentioned... the Report Text Tool!
What's missing in the Comment tool that the Report Text tool has?
- The ability to add active data records from the workflow to its text
- Its wider range of styles which allows for more functionality such as with its Special Tags functions
- Its ability to hyperlink
- Text mode options!

Now, whilst I understand that the Report Text tool is just that, a tool that needs to be connected to the data to work, so too does the Comment tool (to a lesser extent).
It would be awesome to have the ability to connect the data to the Comment tool as it was a Control Container-like connector. It can also be just like the Report Text tool with an optional input, thereby making it like a normal Comment tool.
To visualize my point:

The benefits of doing so:
- Greater flexibility to the user
- Styles are endgame
- Users can use the comment box as a checksum or even a total count / checker to ensure everything is working as intended
- Makes the comment tool more powerful as a dynamic workflow documentation tool
I think it'll be a killer feature enhancement to the comment tool. Hoping to hear comments on this!
Kindly like, share, and subscribe I mean comment your support. Thanks all! 😁
-caltang
- New Idea 207
- Accepting Votes 1,838
- Comments Requested 25
- Under Review 149
- Accepted 55
- Ongoing 7
- Coming Soon 8
- Implemented 473
- Not Planned 123
- Revisit 68
- Partner Dependent 4
- Inactive 674
-
Admin Settings
19 -
AMP Engine
27 -
API
11 -
API SDK
217 -
Category Address
13 -
Category Apps
111 -
Category Behavior Analysis
5 -
Category Calgary
21 -
Category Connectors
239 -
Category Data Investigation
75 -
Category Demographic Analysis
2 -
Category Developer
206 -
Category Documentation
77 -
Category In Database
212 -
Category Input Output
631 -
Category Interface
236 -
Category Join
101 -
Category Machine Learning
3 -
Category Macros
153 -
Category Parse
75 -
Category Predictive
76 -
Category Preparation
384 -
Category Prescriptive
1 -
Category Reporting
198 -
Category Spatial
80 -
Category Text Mining
23 -
Category Time Series
22 -
Category Transform
87 -
Configuration
1 -
Data Connectors
948 -
Desktop Experience
1,493 -
Documentation
64 -
Engine
121 -
Enhancement
274 -
Feature Request
212 -
General
307 -
General Suggestion
4 -
Insights Dataset
2 -
Installation
24 -
Licenses and Activation
15 -
Licensing
10 -
Localization
8 -
Location Intelligence
79 -
Machine Learning
13 -
New Request
177 -
New Tool
32 -
Permissions
1 -
Runtime
28 -
Scheduler
21 -
SDK
10 -
Setup & Configuration
58 -
Tool Improvement
210 -
User Experience Design
165 -
User Settings
73 -
UX
220 -
XML
7
- « Previous
- Next »
- vijayguru on: YXDB SQL Tool to fetch the required data
- Fabrice_P on: Hide/Unhide password button
- cjaneczko on: Adjustable Delay for Control Containers
-
 Watermark
on:
Dynamic Input: Check box to include a field with D...
Watermark
on:
Dynamic Input: Check box to include a field with D...
- aatalai on: cross tab special characters
- KamenRider on: Expand Character Limit of Email Fields to >254
- TimN on: When activate license key, display more informatio...
- simonaubert_bd on: Supporting QVDs
- simonaubert_bd on: In database : documentation for SQL field types ve...
- guth05 on: Search for Tool ID within a workflow