Alteryx Designer Desktop Ideas
Share your Designer Desktop product ideas - we're listening!Submitting an Idea?
Be sure to review our Idea Submission Guidelines for more information!
Submission Guidelines- Community
- :
- Community
- :
- Participate
- :
- Ideas
- :
- Designer Desktop: Hot Ideas
Featured Ideas
Hello,
After used the new "Image Recognition Tool" a few days, I think you could improve it :
> by adding the dimensional constraints in front of each of the pre-trained models,
> by adding a true tool to divide the training data correctly (in order to have an equivalent number of images for each of the labels)
> at least, allow the tool to use black & white images (I wanted to test it on the MNIST, but the tool tells me that it necessarily needs RGB images) ?
Question : do you in the future allow the user to choose between CPU or GPU usage ?
In any case, thank you again for this new tool, it is certainly perfectible, but very simple to use, and I sincerely think that it will allow a greater number of people to understand the many use cases made possible thanks to image recognition.
Thank you again
Kévin VANCAPPEL (France ;-))
Thank you again.
Kévin VANCAPPEL
Formula Tool --> Functions --> Operators list
The operator titles for the two comment functions are too similar, the difference cannot be determined unless checking the hover text.
Can the title for /* Comment */ be adjusted to make it more clear that it is for block or multi-line usage?
I didn't understand the difference until I saw this post on LinkedIn:
https://www.linkedin.com/feed/update/urn:li:activity:7165816592063266817/
/* Comment */ --> /* Block Comment */ | /* Multi-line Comment */


We currently have language support for a few major languages. I know Chinese is available, but the writing system is only Simplified at this moment.
I was recently in conversation with a few people from Taiwan, and they are using the Traditional writing system of Chinese.
If Alteryx can provide Traditional as an additional to their already available Simplified writing system, I think Alteryx can help capture the market in Taiwan better.
The people I spoke with never heard of Alteryx before, and after a demo - they were impressed. If it has this language support, then I think it’ll be much easier to get more sign ups for Alteryx from the Taiwanese market.
Good morning!
This may be a very simple thing, but would it be possible to add a DateTimeQuarter() function? We have DateTime Second, Minute, Day, Month, and Year, and being able to have an easy formula for the quarter as well would be incredibly convenient.
Thanks,
Kat
Documenting your Alteryx workflow is important because it allows others to understand and modify it as needed. To document your workflow effectively, you should provide detailed information about your inputs, outputs, tools used, and any assumptions or limitations.
When it comes to documentation, annotations are often more practical than the comments tool. However, the comments tool in Alteryx offers a useful feature that allows you to customize the background, font, and border colors. These customizable colors can be beneficial when reviewing workflows, as they help draw attention to specific details or notes.
In the screenshot below, you can observe that the highlighted comment attracts more attention compared to the annotation on the left side, even though they contain the same comment.
It would be great if the color customization features available in the comments tool could also be added to the annotations of any tool.

Hello all,
As of today, we use the good old alias in-memory to connect to our datasources in in-memory. We have several environments so we use constants in order to change the name of the in-memory alias during execution.
To illustrate :

Depending of the environment, the constant « v_gp_contexte » will take different values :
- GP_DS08_SIDATA for la dev.
- GP_EE_SIDATA for prod.
Sounds nice, right? But now, we would like to use DCM and the nightmare begins :
We can't manually change the name and set the question :

if we look at the xml of the workflow, we only find an id so editing it is useless :

(for informationDCM connections are stored in some sqlite db in C:\Users\{yourname}\AppData\Local\Alteryx
So, I would like to use the DCM inside the in-memory alias (the in-memory alias is stored and can be edited), just like for in-db connection alias.
Best regards,
Simon
I want a feature to enable join by custom conditions. Currently, in Join tool, allowed condition is only equality of specific fields and specific position, however, in SQL, we can join data by much more flexible conditions like;
SELECT TableA.id FROM TableA INNER JOIN TableB ON TableA.id=TableB.id and TableA.value > TableB.value
Of course, my idea can be easily realized by using combination of Appendix Field + Filter tool, but I meant to say is that Appendix-Fields is quite expensive operation in calculation cost, and it would generate many unnecessary records, which is annoying us in case of handling a huge dataset.
I suppose this kind of flexible conditions can be specified by using expression editor, thereby configuration window of this feature would look like the below image; Adding one more radio button option, and expression editor similar to one used in Filter tool.
Any positive/negative feedback on my idea would be appreciated. Thank you for your attention!

So our company is relatively new to Alteryx Designer and Server and we recently found out that there's no official communication sent out from Alteryx on when there are patch releases for Designer and Server. We've encountered so many bugs that we later found on the release notes that would've been helpful to know about months before.
So my suggestion is to have an option for Administrators to opt in/out for communication emails on when the patches are released.
Thank you!
Right now, the List Box interface tool allows end users to select multiple options of fields for selections, filtering, and formatting/formulating.
However, it doesn't do quite as good when a use case has over 1,000+ columns/fields. This is made even more complicated with each column/field having somewhat similar naming conventions thereby causing confusion.
Having a search function, as made available in standard Select Tools, Join tools, and other tools that has filtering capacity, will be most helpful for developers to give maximum flexibility to end users.
Sometimes I want to set up a filter to compare the values in two fields in my data set. The basic filter option would be much more powerful and configuration would be quicker if this option allowed this.
For example, currently I must use a custom filter to check if Field1 and Field2 are equal:

I would love to have the option to either use a static value in the basic filter (as you can now) or select a field name from a dropdown:

For all Alteryx versions I can remember, when entering a connection string into an input tool (e.g., "C:\Users\mbarone\Desktop\ . . . "), you could just start typing and it would auto-complete. This is no longer the case when DCM is enabled. This is a huge efficiency hit we're taking, and is enough for us not to enable DCM (optional or otherwise), given the fact that current workflow connection manager works just fine (meaning the "akas").
Please bring back auto-complete/predictive text when DCM is enabled.
For companies that have migrated to OneDrive/Teams for data storage, employees need to be able to dynamically input and output data within their workflows in order to schedule a workflow on Alteryx Server and avoid building batch MACROs.
With many organizations migrating to OneDrive, a Dynamic Input/Output tool for OneDrive and SharePoint is needed.
- The existing Directory and Dynamic Input tools only work with UNC path and cannot be leveraged for OneDrive or SharePoint.
- The existing OneDrive and SharePoint tools do not have a dynamic input or output component to them.
- Users have to build work arounds and custom MACROS for a common problem/challenge.
- Users have to map the OneDrive folders to their machine (and server if published to the Gallery)
- This option generates a lot of maintenance, especially on Server, to free up space consumed by the local version when outputting the data.
The enhancement should have the following components:
OneDrive/SharePoint Directory Tool
- Ability to read either one folder with the option to include/exclude subfolders within OneDrive
- Ability to retrieve Creation Date
- Ability to retrieve Last Modified Date
- Ability to identify file type (e.g. .xlsx)
- Ability to read Author
- Ability to read last modified by
- Ability to generate the specific web path for the files
OneDrive/SharePoint Dynamic Input Tool
- Receive the input from the OneDrive/SharePoint Directory Tool and retrieve the data.
Dynamic OneDrive/SharePoint Output Tool
- Dynamically write the output from the workflow to a specific directory individual files in the same location
- Dynamically write the output to multiple tabs on the same file within the directory.
- Dynamically write the output to a new folder within the directory
We have lots of tools that create new column(s) from the Inputs, e.g., Generate Rows. It'd be very nice if the new column(s) is/are highlighted in the Output. This makes it a lot easier for users when developing the workflow.
The Find Replace tool has a checkbox to do a case insensitive find. It would be fabulous if the Join and Join Multiple tools had a similar checkbox.
I frequently have to create a new field in each data stream, convert the data I want to join on to upper case, perform the join and remove the extra "helper" fields. Using the helper field is needed in my case in order to preserve unique capitalization (i.e., acronyms within the string, etc.).
Hello all,
As of now, you have two very distinct kinds of connection :
-in memory alias
-in database alias
It happens than every single time I use a in-database alias I have to create the same for in memory since some operations cannot be realized in in-database (such as pre-sql or interface tools)
What does that mean for us :
-more complex settings operations/training/tests
-unefficient worflows that have to deal with two kinds of alias.
What I propose :
-a single "connection alias", that can be used either for in-db either for in-memory,
-one place to configure
-the in-db or in-memory being dependant on the tools you use

Best regards,
Simon
It would be great if you could include a new Parse tool to process Data Sets description (Meta data) formatted using the DCAT (W3C) standard in the next version of Alteryx.
DCAT is a standard for the description of data sets. It provides a comprehensive set of metadata that can be used to describe the content, structure, and lineage of a data set.
We believe that supporting DCAT in Alteryx would be a valuable addition to the product. It would allow us to:
- Improve the interoperability of our data sets with other systems (M2M)
- Make it easier to share and reuse our data sets
- Provide a more consistent way to describe our data sets
- Bring down the costs of describing and developing interfaces with other Government Entities
- Work on some parts of making our data Findable – Accessible – Interopable - Reusable (FAIR)
We understand that implementing support for this standards requires some development effort (eventually done in stages, building from a minimal viable support to a full-blown support). However, we believe that the benefits to the Alteryx Community worldwide and Alteryx as a top-quality data preparation tool outweigh the cost.
I also expect the effort to be manageable (perhaps a macro will do as a start) when you see the standard RDF syntax being used, which is similar to JSON.
DCAT, which stands for Data Catalog Vocabulary, is a W3C Recommendation for describing data catalogs in RDF. It provides a set of classes and properties for describing datasets, their distributions, and their relationships to other datasets and data catalogs. This allows data catalogs to be discovered and searched more easily, and it also makes it possible to integrate data catalogs with other Semantic Web applications.
DCAT is designed to be flexible and extensible, so they can be used to describe a wide variety. They are both also designed to be interoperable, so they can be used together to create rich and interconnected descriptions of data and knowledge.
Here are some of the benefits of using DCAT:
- Improved discoverability: DCAT makes it easier to discover and use KOS, as they provide a standard way of describing their attributes.
- Increased interoperability: DCAT allows KOS to be integrated with other Semantic Web applications, making it possible to create more powerful and interoperable applications.
- Enhanced semantic richness: DCAT provides a way to add semantic richness to KOS , making it possible to describe them in a more detailed and nuanced way.
Here are some examples of how DCAT is being used:
- The DataCite metadata standard uses DCAT to describe data catalogs.
- The European Data Portal uses DCAT to discover and search for data sets.
- The Dutch Government made it a mandatory standard for all Dutch Government Agencies.
As the Semantic Web continues to grow, DCAT is likely to become even more widely used.
DCAT
- Reference Page: https://www.w3.org/TR/vocab-dcat/
- Dutch (NL) Standard: https://forumstandaardisatie.nl/open-standaarden/dcat-ap-donl
- WIKI Pedia on DCAT: https://en.wikipedia.org/wiki/Data_Catalog_Vocabulary
RDF
- Reference Page: https://www.w3.org/TR/REC-rdf-syntax/
- Dutch (NL) Standard: https://forumstandaardisatie.nl/open-standaarden/rdf
- WIKI Pedia on DCAT: https://en.wikipedia.org/wiki/Resource_Description_Framework
In some cases, the information about incoming columns to tools are (temporarily) forgotten, e.g. if Autoconfig is switched off, if the incoming connection is temporarily missing, or if column names are generated dynamically and the workflow has not been executed, yet.
Many tools deal with that situation well, e.g. Selection, Formula, or Summarize. In these cases, the tools tell the user that they cannot find incoming columns, but they preserve the configuration so that the user still can (at least partially) work on these tools and important information on the configuration is not lost:
Example Select Tool
- First step: Connections present, configuration typed in:
- Second step: Connection cut, confguration opened. The configuration looks screwed up but implicitly contains all settings:
- Third step: Connection re-connected. The configuration is as before:



Other tools behave the opposite, for example Unique or Macro Input (an for sure many other tools). If the incoming columns are currently unknown to the Designer and you click once on the symbol, the entire configuration of this tool is lost. You might try to get the configuration back by pressing undo. This, in most cases does not work. Or, even worse, you find out what happened later when it's too late for undo. In this case, you either have an old version of that workflow to look up the configuration or you have to re-develop it. In any case, this is unnecessary and time-consuming software behaviour.
Example Unique Tool
- Step 1: Connections present, configuration typed in:
- Step 2: Connection cut, confguration opened. The configuration is empty:
- Step 3: Connection re-connected: The entire configuration is permanently lost:



I wasn't sure whether I should report this as a bug or a feature enhancement. It is somehow in between. Two aspects tell me that this should be changed:
- Inconsistent behaviour of different tools for now reason,
- Easy loss of programming work, resulting in time-consuming bug fixing.
Please make sure that all tools preserve their configuration also if information on incoming columns is temporarily lost.
Hi everyone,
Add two additional features to a directory tool. Something like this:

Use cases:
1. Since it is not possible to use a folder browse on the Gallery, this could help a basic user create a list of possible folders to select from with the help of a drop-down
2. Directory analysis for cleaning purposes - currently, if you want to get a list of the folders with Alteryx, it takes forever for big file servers since Alteryx is mapping all the files
Both are achievable today through regex or a bat script.
Thank you,
Fernando Vizcaino
Hello all,
According to wikipedia https://en.wikipedia.org/wiki/Materialized_view
In computing, a materialized view is a database object that contains the results of a query. For example, it may be a local copy of data located remotely, or may be a subset of the rows and/or columns of a table or join result, or may be a summary using an aggregate function.
The process of setting up a materialized view is sometimes called materialization.[1] This is a form of caching the results of a query, similar to memoization of the value of a function in functional languages, and it is sometimes described as a form of precomputation.[2][3] As with other forms of precomputation, database users typically use materialized views for performance reasons, i.e. as a form of optimization.
So, I would like to create that in Alteryx, for obvious performance reasons in some use cases.
This is not a duplicate of https://community.alteryx.com/t5/Alteryx-Designer-Desktop-Ideas/In-DB-Create-View/idi-p/157886
Best regards,
Simon
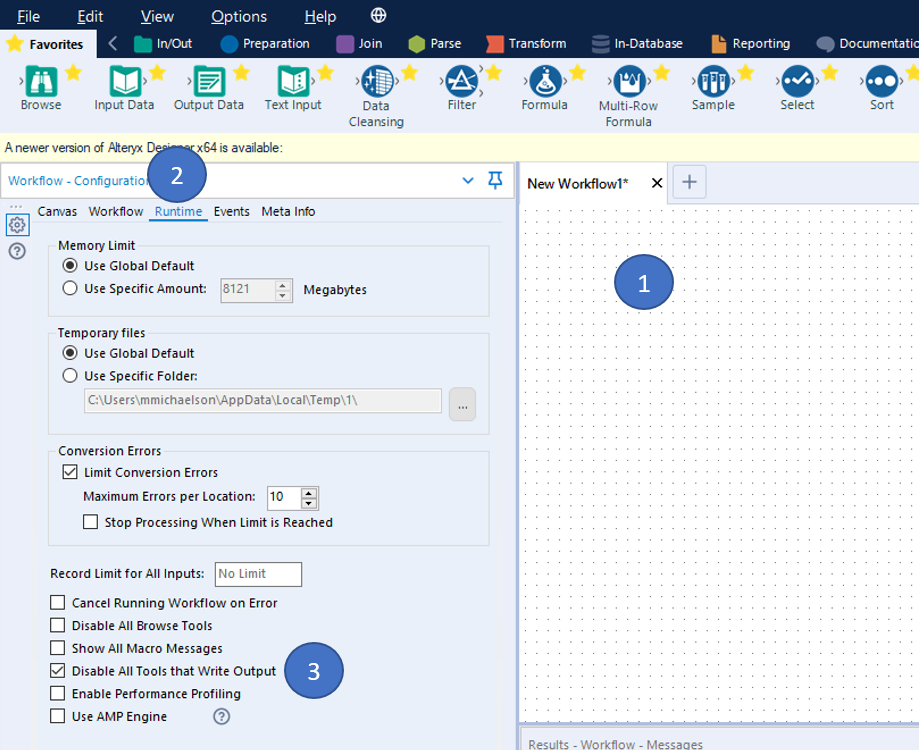
Today, there is an checkbox to "Disable All Tools that Write Output" within the Runtime settings for a workflow. Setting this option requires at least 3 clicks:
- Click on the canvas
- Click the "Runtime" tab in the Configuration pane
- Click the checkbox
Could a keyboard shortcut be added for this? I've spoken to several users who leverage this feature and, while it is already a time saver, it seems helpful enough where a keyboard shortcut is warranted.
{kind=link}
Add Unicode category to the cleansing tool
- New Idea 205
- Accepting Votes 1,838
- Comments Requested 25
- Under Review 149
- Accepted 55
- Ongoing 7
- Coming Soon 8
- Implemented 473
- Not Planned 123
- Revisit 68
- Partner Dependent 4
- Inactive 674
-
Admin Settings
19 -
AMP Engine
27 -
API
11 -
API SDK
217 -
Category Address
13 -
Category Apps
111 -
Category Behavior Analysis
5 -
Category Calgary
21 -
Category Connectors
239 -
Category Data Investigation
75 -
Category Demographic Analysis
2 -
Category Developer
206 -
Category Documentation
77 -
Category In Database
212 -
Category Input Output
631 -
Category Interface
236 -
Category Join
101 -
Category Machine Learning
3 -
Category Macros
153 -
Category Parse
74 -
Category Predictive
76 -
Category Preparation
384 -
Category Prescriptive
1 -
Category Reporting
198 -
Category Spatial
80 -
Category Text Mining
23 -
Category Time Series
22 -
Category Transform
87 -
Configuration
1 -
Data Connectors
948 -
Desktop Experience
1,491 -
Documentation
64 -
Engine
121 -
Enhancement
274 -
Feature Request
212 -
General
307 -
General Suggestion
4 -
Insights Dataset
2 -
Installation
24 -
Licenses and Activation
15 -
Licensing
10 -
Localization
8 -
Location Intelligence
79 -
Machine Learning
13 -
New Request
175 -
New Tool
32 -
Permissions
1 -
Runtime
28 -
Scheduler
21 -
SDK
10 -
Setup & Configuration
58 -
Tool Improvement
210 -
User Experience Design
165 -
User Settings
73 -
UX
220 -
XML
7
- « Previous
- Next »
- vijayguru on: YXDB SQL Tool to fetch the required data
- Fabrice_P on: Hide/Unhide password button
- cjaneczko on: Adjustable Delay for Control Containers
-
 Watermark
on:
Dynamic Input: Check box to include a field with D...
Watermark
on:
Dynamic Input: Check box to include a field with D...
- aatalai on: cross tab special characters
- KamenRider on: Expand Character Limit of Email Fields to >254
- TimN on: When activate license key, display more informatio...
- simonaubert_bd on: Supporting QVDs
- simonaubert_bd on: In database : documentation for SQL field types ve...
- guth05 on: Search for Tool ID within a workflow
| User | Likes Count |
|---|---|
| 41 | |
| 29 | |
| 18 | |
| 10 | |
| 7 |