Alteryx Designer Desktop Ideas
Share your Designer Desktop product ideas - we're listening!Submitting an Idea?
Be sure to review our Idea Submission Guidelines for more information!
Submission Guidelines- Community
- :
- Community
- :
- Participate
- :
- Ideas
- :
- Designer Desktop: Top Ideas
Featured Ideas
Hello,
After used the new "Image Recognition Tool" a few days, I think you could improve it :
> by adding the dimensional constraints in front of each of the pre-trained models,
> by adding a true tool to divide the training data correctly (in order to have an equivalent number of images for each of the labels)
> at least, allow the tool to use black & white images (I wanted to test it on the MNIST, but the tool tells me that it necessarily needs RGB images) ?
Question : do you in the future allow the user to choose between CPU or GPU usage ?
In any case, thank you again for this new tool, it is certainly perfectible, but very simple to use, and I sincerely think that it will allow a greater number of people to understand the many use cases made possible thanks to image recognition.
Thank you again
Kévin VANCAPPEL (France ;-))
Thank you again.
Kévin VANCAPPEL
The TO field (and I assume other fields) in the Email tool seem to have a 254 character limit - this should be increased heavily as there are many distribution lists that will go above this character limit!
- Solved: Email tool recipients list truncating emails - Alteryx Community
- Solved: Email Widget: Cut off all the emails in the "To" r... - Alteryx Community
- Re: Email Address Truncated in the "To" Field - Alteryx Community
A distribution list works but is not ideal. Thumbs up if you like this idea!
When I make the workflow, the font size on Result window is no problem.
But, when we show the contents of Results window on the presentation or online meeting, the font size is too small.
I want the function which is enlarge the font size. The important point is that the current font size is okay on making workflow and the large font size is only needed on showing to the another people on presentation or online meeting.
One more point to add, it would be helpful to be able to change the font size with Ctrl + mouse wheel.

Push the zoom button:

Documenting your Alteryx workflow is important because it allows others to understand and modify it as needed. To document your workflow effectively, you should provide detailed information about your inputs, outputs, tools used, and any assumptions or limitations.
When it comes to documentation, annotations are often more practical than the comments tool. However, the comments tool in Alteryx offers a useful feature that allows you to customize the background, font, and border colors. These customizable colors can be beneficial when reviewing workflows, as they help draw attention to specific details or notes.
In the screenshot below, you can observe that the highlighted comment attracts more attention compared to the annotation on the left side, even though they contain the same comment.
It would be great if the color customization features available in the comments tool could also be added to the annotations of any tool.

I would like a way to disable all containers within a workflow with a single click. It could be simply disable / enable all or a series of check boxes, one for each container, where you can choose to disable / enable all or a chosen selection.
In large workflows, with many containers, if you want to run a single container while testing it can take a while to scroll up and down the workflow disabling each container in turn.
Sometimes I want to set up a filter to compare the values in two fields in my data set. The basic filter option would be much more powerful and configuration would be quicker if this option allowed this.
For example, currently I must use a custom filter to check if Field1 and Field2 are equal:

I would love to have the option to either use a static value in the basic filter (as you can now) or select a field name from a dropdown:

For companies that have migrated to OneDrive/Teams for data storage, employees need to be able to dynamically input and output data within their workflows in order to schedule a workflow on Alteryx Server and avoid building batch MACROs.
With many organizations migrating to OneDrive, a Dynamic Input/Output tool for OneDrive and SharePoint is needed.
- The existing Directory and Dynamic Input tools only work with UNC path and cannot be leveraged for OneDrive or SharePoint.
- The existing OneDrive and SharePoint tools do not have a dynamic input or output component to them.
- Users have to build work arounds and custom MACROS for a common problem/challenge.
- Users have to map the OneDrive folders to their machine (and server if published to the Gallery)
- This option generates a lot of maintenance, especially on Server, to free up space consumed by the local version when outputting the data.
The enhancement should have the following components:
OneDrive/SharePoint Directory Tool
- Ability to read either one folder with the option to include/exclude subfolders within OneDrive
- Ability to retrieve Creation Date
- Ability to retrieve Last Modified Date
- Ability to identify file type (e.g. .xlsx)
- Ability to read Author
- Ability to read last modified by
- Ability to generate the specific web path for the files
OneDrive/SharePoint Dynamic Input Tool
- Receive the input from the OneDrive/SharePoint Directory Tool and retrieve the data.
Dynamic OneDrive/SharePoint Output Tool
- Dynamically write the output from the workflow to a specific directory individual files in the same location
- Dynamically write the output to multiple tabs on the same file within the directory.
- Dynamically write the output to a new folder within the directory
Hello all,
As of now, you have two very distinct kinds of connection :
-in memory alias
-in database alias
It happens than every single time I use a in-database alias I have to create the same for in memory since some operations cannot be realized in in-database (such as pre-sql or interface tools)
What does that mean for us :
-more complex settings operations/training/tests
-unefficient worflows that have to deal with two kinds of alias.
What I propose :
-a single "connection alias", that can be used either for in-db either for in-memory,
-one place to configure
-the in-db or in-memory being dependant on the tools you use

Best regards,
Simon
Hey all,
I don't know about you, but I have always had trouble hovering the mouse over the Results window pane trying to get the resize icon to appear. It seems like you need surgeon level precision to find the icon! 😷
I love Designer and want to see it be the best it can possibly be. I feel like increasing the clickable/hovering area for this resize would be amazingly helpful!
Just wanted to see if we could get some community momentum going in order to get some developer eyes on this issue. 🙂
Please help by bumping/upvoting this thread!

-K
Migrated this from another thread. Some folks tagged from the original post :)
@cpatrickwk @caltang @afellows @MRod @alexnajm @ericsmalley @MilindG @Prometheus @innovate20
I want a feature to enable join by custom conditions. Currently, in Join tool, allowed condition is only equality of specific fields and specific position, however, in SQL, we can join data by much more flexible conditions like;
SELECT TableA.id FROM TableA INNER JOIN TableB ON TableA.id=TableB.id and TableA.value > TableB.value
Of course, my idea can be easily realized by using combination of Appendix Field + Filter tool, but I meant to say is that Appendix-Fields is quite expensive operation in calculation cost, and it would generate many unnecessary records, which is annoying us in case of handling a huge dataset.
I suppose this kind of flexible conditions can be specified by using expression editor, thereby configuration window of this feature would look like the below image; Adding one more radio button option, and expression editor similar to one used in Filter tool.
Any positive/negative feedback on my idea would be appreciated. Thank you for your attention!

Hello all,
According to wikipedia https://en.wikipedia.org/wiki/Materialized_view
In computing, a materialized view is a database object that contains the results of a query. For example, it may be a local copy of data located remotely, or may be a subset of the rows and/or columns of a table or join result, or may be a summary using an aggregate function.
The process of setting up a materialized view is sometimes called materialization.[1] This is a form of caching the results of a query, similar to memoization of the value of a function in functional languages, and it is sometimes described as a form of precomputation.[2][3] As with other forms of precomputation, database users typically use materialized views for performance reasons, i.e. as a form of optimization.
So, I would like to create that in Alteryx, for obvious performance reasons in some use cases.
This is not a duplicate of https://community.alteryx.com/t5/Alteryx-Designer-Desktop-Ideas/In-DB-Create-View/idi-p/157886
Best regards,
Simon
Everyone knows the importance of adding the appropriate controls and governance to your workflows - and often, this means including events that will generate notifications if a workflow is running with errors.
But who is the audience of that email? If it's not a developer, will that person know what they are reading and where to focus?
How about a developer that would like to customize the message that the end user will receive?
Porting some existing functionality from other tools in the Alteryx toolkit to the Events page could easily provide added flexibility to event generation:
1) Add a formatting bar to the tool like shown in the image below
-- Style changes
-- Alignment
-- Highlighting
-- Coloring
-- Images
2) Add a function bar to the tool like shown in the image below
-- Ability to view all available variables
-- Ability to apply formulas using variables
-- Ability to save formulas

What do you think? Give this post a thumbs up if you find the post helpful!
Hello all,
According to wikipedia :
https://en.wikipedia.org/wiki/Embedded_database
An embedded database system is a database management system (DBMS) which is tightly integrated with an application software; it is embedded in the application.
It's often like a single file/dll that you can use inside an application without the user having to connect (or at least to configure it) to it (it's all done inside the application). So, it's widely portable.
Why it does matter ?
As of today, there is not a single example of in database workflow because all the supported databases need the user to:
1/install an odbc driver (most of time, he won't have the rights to do so)
2/configure an odbc connection (sometimes, he doesn't have the rights to)
3/configure a connection on Alteryx (ok, he can)
So it requires IT action, which can be pretty long (in ùany organization, it requires several weeks !!). And even with all of that,the users must be granted privilege to access database and the customer need to develop its own examples and write its own specific documentation.
Well, this is not efficient.
What I suggest is Alteryx to use one of embedded database for training support/one tool examples. SQLlite seems good, maybe a more analytics oriented (like DuckDB ) would be more efficient.
The requirement are, I think, the following :
-OpenSource and free
-Fast
-SQL compliant
-With a bulk load ability
Best regards,
Simon
Hi everyone,
Add two additional features to a directory tool. Something like this:

Use cases:
1. Since it is not possible to use a folder browse on the Gallery, this could help a basic user create a list of possible folders to select from with the help of a drop-down
2. Directory analysis for cleaning purposes - currently, if you want to get a list of the folders with Alteryx, it takes forever for big file servers since Alteryx is mapping all the files
Both are achievable today through regex or a bat script.
Thank you,
Fernando Vizcaino
Right now, the List Box interface tool allows end users to select multiple options of fields for selections, filtering, and formatting/formulating.
However, it doesn't do quite as good when a use case has over 1,000+ columns/fields. This is made even more complicated with each column/field having somewhat similar naming conventions thereby causing confusion.
Having a search function, as made available in standard Select Tools, Join tools, and other tools that has filtering capacity, will be most helpful for developers to give maximum flexibility to end users.
We all know and love the Comment tool. It's a staple of every workflow to give users an idea of the workflow in finer details. It's a powerful tool - it helps adds context to tools and containers, and it also serves as an image placeholder for us to style our workflows as aesthetically pleasing as possible.
Now, the gensis of this idea is inspired by this post and subsequent research question here.
The Comment Tool today allows you to:
- Write your text and provide context / documentation to your workflow
- Style its shape
- Style its font, colour, and background colour
- Align the text
- Put an image to your workflow

But it would provide way more functionality if it had the capabilities of another awesome Alteryx tool that is not so frequently mentioned... the Report Text Tool!
What's missing in the Comment tool that the Report Text tool has?
- The ability to add active data records from the workflow to its text
- Its wider range of styles which allows for more functionality such as with its Special Tags functions
- Its ability to hyperlink
- Text mode options!

Now, whilst I understand that the Report Text tool is just that, a tool that needs to be connected to the data to work, so too does the Comment tool (to a lesser extent).
It would be awesome to have the ability to connect the data to the Comment tool as it was a Control Container-like connector. It can also be just like the Report Text tool with an optional input, thereby making it like a normal Comment tool.
To visualize my point:

The benefits of doing so:
- Greater flexibility to the user
- Styles are endgame
- Users can use the comment box as a checksum or even a total count / checker to ensure everything is working as intended
- Makes the comment tool more powerful as a dynamic workflow documentation tool
I think it'll be a killer feature enhancement to the comment tool. Hoping to hear comments on this!
Kindly like, share, and subscribe I mean comment your support. Thanks all! 😁
-caltang
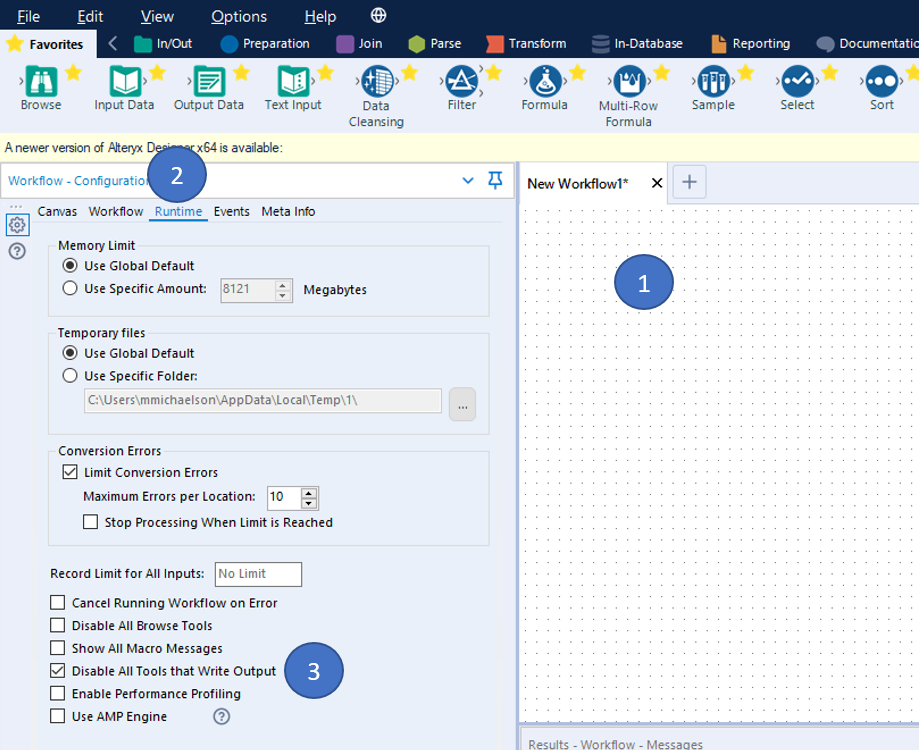
Today, there is an checkbox to "Disable All Tools that Write Output" within the Runtime settings for a workflow. Setting this option requires at least 3 clicks:
- Click on the canvas
- Click the "Runtime" tab in the Configuration pane
- Click the checkbox
Could a keyboard shortcut be added for this? I've spoken to several users who leverage this feature and, while it is already a time saver, it seems helpful enough where a keyboard shortcut is warranted.
When making any type of macro, it's important to test the functionality of the macro via a debug. This is accomplished successfully with normal tools, however there's a bug that will not allow the user to debug In-DB macros that use either of the following standard Alteryx tools:
- Macro Input In-DB
- Macro Output In-DB
If either of these tools are included in the macro you are building, an error message will appear not allowing you to open a debug.
Error message: Question Tool Load Error: A question tool with a tool id of XXX is missing the associated question data.
Of course, Macro input and output tools do not require any specific action/question tool associated with it. This is a bug. A user pointed out the XML issue almost 3 years ago here:
In summary: "It appears that the tool itself inserts a hidden Question attribute into the XML which can also be seen in Workflow Configuration"
Source:
Examples....
A normal macro, using standard tools:

After debugging a standard macro, the Macro Input/Output tools correctly change to a Text Input and a Browse tool. This allows the macro author to test the macro.

However, when trying the same thing with In-DB tools in a macro, an error message appears:
In-DB macro 1:

In-DB Macro error message (after clicking "Open Debug"):

Hello all,
When using in-database, all you have in select or formula are the Alteryx field types (V_String, etc..).
However, since you're mostly writing in database, in the end, there is a conversion of Alteryx field types to real SQL field types (like varchar). But how is it done ? As of today, it's a total black box. Some documentation would be appreciated.
Best regards,
Simon
In some cases, the information about incoming columns to tools are (temporarily) forgotten, e.g. if Autoconfig is switched off, if the incoming connection is temporarily missing, or if column names are generated dynamically and the workflow has not been executed, yet.
Many tools deal with that situation well, e.g. Selection, Formula, or Summarize. In these cases, the tools tell the user that they cannot find incoming columns, but they preserve the configuration so that the user still can (at least partially) work on these tools and important information on the configuration is not lost:
Example Select Tool
- First step: Connections present, configuration typed in:
- Second step: Connection cut, confguration opened. The configuration looks screwed up but implicitly contains all settings:
- Third step: Connection re-connected. The configuration is as before:



Other tools behave the opposite, for example Unique or Macro Input (an for sure many other tools). If the incoming columns are currently unknown to the Designer and you click once on the symbol, the entire configuration of this tool is lost. You might try to get the configuration back by pressing undo. This, in most cases does not work. Or, even worse, you find out what happened later when it's too late for undo. In this case, you either have an old version of that workflow to look up the configuration or you have to re-develop it. In any case, this is unnecessary and time-consuming software behaviour.
Example Unique Tool
- Step 1: Connections present, configuration typed in:
- Step 2: Connection cut, confguration opened. The configuration is empty:
- Step 3: Connection re-connected: The entire configuration is permanently lost:



I wasn't sure whether I should report this as a bug or a feature enhancement. It is somehow in between. Two aspects tell me that this should be changed:
- Inconsistent behaviour of different tools for now reason,
- Easy loss of programming work, resulting in time-consuming bug fixing.
Please make sure that all tools preserve their configuration also if information on incoming columns is temporarily lost.
Hello all,
It's really frustrating to have an "alteryx field type" in In-Database Select. It doesn't even make sense since we're manipulating only data in SQL database where those types does not exist. What we should see is the SQL field type.
Best regards,
Simon

{kind=link}
- New Idea 208
- Accepting Votes 1,837
- Comments Requested 25
- Under Review 150
- Accepted 55
- Ongoing 7
- Coming Soon 8
- Implemented 473
- Not Planned 123
- Revisit 68
- Partner Dependent 4
- Inactive 674
-
Admin Settings
19 -
AMP Engine
27 -
API
11 -
API SDK
217 -
Category Address
13 -
Category Apps
111 -
Category Behavior Analysis
5 -
Category Calgary
21 -
Category Connectors
239 -
Category Data Investigation
75 -
Category Demographic Analysis
2 -
Category Developer
206 -
Category Documentation
77 -
Category In Database
212 -
Category Input Output
632 -
Category Interface
236 -
Category Join
101 -
Category Machine Learning
3 -
Category Macros
153 -
Category Parse
75 -
Category Predictive
76 -
Category Preparation
384 -
Category Prescriptive
1 -
Category Reporting
198 -
Category Spatial
80 -
Category Text Mining
23 -
Category Time Series
22 -
Category Transform
87 -
Configuration
1 -
Data Connectors
948 -
Desktop Experience
1,493 -
Documentation
64 -
Engine
122 -
Enhancement
275 -
Feature Request
212 -
General
307 -
General Suggestion
4 -
Insights Dataset
2 -
Installation
24 -
Licenses and Activation
15 -
Licensing
10 -
Localization
8 -
Location Intelligence
79 -
Machine Learning
13 -
New Request
177 -
New Tool
32 -
Permissions
1 -
Runtime
28 -
Scheduler
21 -
SDK
10 -
Setup & Configuration
58 -
Tool Improvement
210 -
User Experience Design
165 -
User Settings
73 -
UX
220 -
XML
7
- « Previous
- Next »
- vijayguru on: YXDB SQL Tool to fetch the required data
- Fabrice_P on: Hide/Unhide password button
- cjaneczko on: Adjustable Delay for Control Containers
-
 Watermark
on:
Dynamic Input: Check box to include a field with D...
Watermark
on:
Dynamic Input: Check box to include a field with D...
- aatalai on: cross tab special characters
- KamenRider on: Expand Character Limit of Email Fields to >254
- TimN on: When activate license key, display more informatio...
- simonaubert_bd on: Supporting QVDs
- simonaubert_bd on: In database : documentation for SQL field types ve...
- guth05 on: Search for Tool ID within a workflow