Alteryx Designer Desktop Ideas
Share your Designer Desktop product ideas - we're listening!Submitting an Idea?
Be sure to review our Idea Submission Guidelines for more information!
Submission Guidelines- Community
- :
- Community
- :
- Participate
- :
- Ideas
- :
- Designer Desktop
Featured Ideas
Hello,
After used the new "Image Recognition Tool" a few days, I think you could improve it :
> by adding the dimensional constraints in front of each of the pre-trained models,
> by adding a true tool to divide the training data correctly (in order to have an equivalent number of images for each of the labels)
> at least, allow the tool to use black & white images (I wanted to test it on the MNIST, but the tool tells me that it necessarily needs RGB images) ?
Question : do you in the future allow the user to choose between CPU or GPU usage ?
In any case, thank you again for this new tool, it is certainly perfectible, but very simple to use, and I sincerely think that it will allow a greater number of people to understand the many use cases made possible thanks to image recognition.
Thank you again
Kévin VANCAPPEL (France ;-))
Thank you again.
Kévin VANCAPPEL
I would LOVE the quick win of selecting some cells in the browse tool results pane, and a label somewhere shows me the sum, average, count, distinct count, etc. I hate to use the line but ... “a bit like Excel does”. They even alow a user to choose what metrics they want to show in the label by right clicking. 🙂
This improvement would save me having to export to Excel, check they add up just by selecting, and jumping back, or even worse getting my calculator out and punching the numbers in.
Jay
Currently, in order to change the header and data justification to CENTER, one has to select the "Column Rules" button for each column configuration. In a large report (25+ columns), that means selecting each time. It would be more efficient to have the header justification in the Default Table Settings style editor. There is already a setting for font, font size, bold or itallic, text color and background color. I have never created a report for someone where they did not want the headers centered. The workaround is to only feed one column through, then to change the column rules for that column and the Cynamic or Unknown Fields. This works fine, but when I have a report that creates an Excel workbook with 5+ tabs, it gets annoying. It's even more time consuming when I have a report tab, that I need to create sub headings for, so there are multiple report tools for one Excel tab.
Hi all,
Within the last days I was confronted with a problem in a production workflow, which was not working as expected. The main problem was, that the input tool was collecting data from a MSSQL database, but some parts of the strings disappeared on the way.
One column was specified as a VARCHAR and contained some special characters (e.g. '…', not '...'). The input tool now drops all characters which are not included in the Latin-1 table, but this does not seem to be a good behaviour from my perspective. This is not the case for NVARCHAR fields, they are automatically imported as V_WString, which contains those special characters.
The solution was to just cast in the SQL query (redesign of the database layout would also work). Shouldn't this be solved a little easier, or are there good reasons to force using a V_String?
Best regards
Max
It would be good to be able to fix pie chart colours (either automatically of manually), so that when building a report, categories are given the same colour throughout the report across multiple pie charts. Currently, if the number of categories being shown varies, there is no way to manually align the colours (In the Bar Chart type there is a Style Mode for the Series where you can use a formula to assign a colour based on a criteria such as the name, but not for pie charts).
More and more applications in R are written with tidyverse code using tidy data principles. According to rdocumentation.org, tidyverse packages are some of the most downloaded. Adding this package to the default offering will make it easier to transfer existing R code to Alteryx!
I have an app that contains 4 check boxes. Each check box is independent, and when checked, two other prompts open up to the user (in this case, text boxes which are also independent of the other check boxes).
I would like to be able to "Check All", so that with one click, ALL four check boxes are checked, and their prompts all open up.
I would like to be able to pause a module A, run module B then restart A at a later time.
The Legacy Excel output Driver has the ability to Delete Data & Append as an output option for Excel files. This is useful to retain custom formatting and conditional formatting on a worksheet.
However, the new Excel Output Driver and Macro-Enabled Excel Driver do not have this option.
I think this would be very helpful for a lot of our business needs, as we still use Excel for a lot of our reporting needs. I know that Tableau is a very powerful tool for exactly this sort of situation, but we do not yet have any widespread adoption at our company.
Particularly, conditional formatting would be a fantastic option, as it would save a lot of post-run manual process.
When a user connects the Input tool to a database, the Tables view lists the tables the user can see. Please add a search feature and an option to export the list.
I want modification of the Email Tool to support running it at a specific point, defined by developer, within a workflow where currently "The Email tool will always be the last tool to run in a workflow".
We use the tool to send notification of completion of jobs and sometimes attach outputs but we would like to be able to also send notifications at the start or at key points within a workflows processing. Currently the email tool is forced to be the last tool run in a flow, even if you use block until done tool to force order of path execution to hit the email tool first.
If we could add a setting to the configuration to override the current default, of being the last tool run, to allow it to run at will within a flow that would be awesome! And of course we would want the same ability for texting, be it a new feature of the email tool or a new tool all its own.
The Texting option refers to an issue in Andrew Hooper's post seeking enhancement of the email tool for texting, search on "Email tool add HTML output option" or use link...
Hello!
I had found this quirk whilst working on a fairly large workflow, where i had multiple tools cached to keep things quick. I had moved one of the tools on the canvas to a pre-existing container, and it removed the caching on my whole workflow.
Steps to reproduce:
1) setup a super basic workflow (or any workflow):

2) Cache part of the workflow:


3) drag one of the tools (in this case the formula) into the container:

As you can see, the workflow is no longer cached and i have to re-cache it.
This would be a welcome change as that is an unexpected behaviour to me, and so I would imagine others too. A workflow no longer being cached can cost the developer a lot of time (and potential resource, if hitting a Snowflake instance, for example).
Thanks,
TheOC
In the summary tool, we often use the summary tool to concatenate strings - we love this functionality.
However, we would also like to be able to concatenate just the unique values of strings. This could be done if we ran the preceding text field through the unique tool first, and then concatenate. But when we are doing this for multiple text variables and when we need to summarize other types of data at the same time, this becomes a very un-natural combination of joins & macros.
Thanks for considering,
Jeremy
Pre-v10, I could set a default tool for each tool palatte. For example, for the Summarize tool pallate, I could make the Summarize tool the default (that already was the default, but you get the point). I could then simply drag the tool palatte icon onto the canvas and the Summarize tool would be there. Now, I have to navigate to the tool pallate and drag my tool on the canvas. Yes, I know I could add it to my favorites, but screen real estate goes quickly after adding just a few favorites to the already defaulted favorites. It would've been nice if this functionality wasn't removed with v10.
Hello,
I see no reason why Insight is deactivated by default... it would be so smarter to make it active. That's all, 5 minutes of a developer.
Best regards,
Simon
When I am working with 2 different versions of Alteryx (e.g., a current version and a beta version), I set different background colors for each version through user settings. This a great because I don't want to accidentally modify a current workflow when beta testing; the canvas color is a clear, but subtle indicator of which version I'm working in.
Similarly, I'd like the option to set a custom canvas color for each workflow. Use case - I have two versions of a workflow, e.g., one production and one in development, both in the same version of Alteryx. I don't want to accidentally modify the production workflow instead of the dev workflow. My current workarounds are to open the workflow in two different windows on separate monitors or to add an obtrusive comment box making the dev version as in development. Neither is a great option. If I could set the canvas for the workflows to different colors, that would reduce the possibility of making this mistake.
My idea is to expand this the custom canvas-coloring functionality to allow users to set a custom canvas color for each workflow.
After evolving my workflows to provide email alerts after they run with errors I thought it would be a good idea to include conditional alerts. Meaning: incorporating formulas(if then) to determine when the alert will run. Currently, the only options are "Before Run, After Run, After Run with Errors, After Run Without Errors, Disabled".
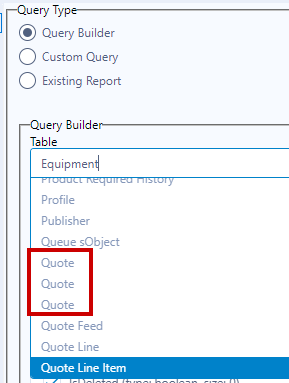
In the Python 3.6/3.8 versions of SF Input Tool, the business name of an object is returned (e.g., Quote). In the now-deprecated Macro-based version of SF Input, the technical name was returned (e.g., Quote, Quote__c, SBQQ_Quote__c).
With the Python Input tools, there are multiple occurrences of "Quote" to select from with the SF Input tool. This is confusing and leads to "guessing" which object is the right one.
See attached screenshots.
My proposal is to add an option to the SF Input tool to allow the workflow developer to choose whether technical or business names should be returned.
Can there be a User or System setting option for Desktop Designers to save the default SMTP server to be used for all email functionalities?
I recently upgraded from 2018.1 to 2019.1 version and with that lost the "Auto detect SMTP server" option in the email tool.
The existing workflows still seem to work. However the email tool errors out when I make any enhancements to those existing workflows. Dictating the email tool to use the default SMTP server pre-configured by the user in the user/system setup options will be extremely helpful.
As reported in this post, I would suggest to only add new browse tools to outputs that do not have a browse tool attached already when using the "Add All Browse" feature.
Thank you!

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- New Idea 206
- Accepting Votes 1,838
- Comments Requested 25
- Under Review 149
- Accepted 55
- Ongoing 7
- Coming Soon 8
- Implemented 473
- Not Planned 123
- Revisit 68
- Partner Dependent 4
- Inactive 674
-
Admin Settings
19 -
AMP Engine
27 -
API
11 -
API SDK
217 -
Category Address
13 -
Category Apps
111 -
Category Behavior Analysis
5 -
Category Calgary
21 -
Category Connectors
239 -
Category Data Investigation
75 -
Category Demographic Analysis
2 -
Category Developer
206 -
Category Documentation
77 -
Category In Database
212 -
Category Input Output
631 -
Category Interface
236 -
Category Join
101 -
Category Machine Learning
3 -
Category Macros
153 -
Category Parse
74 -
Category Predictive
76 -
Category Preparation
384 -
Category Prescriptive
1 -
Category Reporting
198 -
Category Spatial
80 -
Category Text Mining
23 -
Category Time Series
22 -
Category Transform
87 -
Configuration
1 -
Data Connectors
948 -
Desktop Experience
1,492 -
Documentation
64 -
Engine
121 -
Enhancement
274 -
Feature Request
212 -
General
307 -
General Suggestion
4 -
Insights Dataset
2 -
Installation
24 -
Licenses and Activation
15 -
Licensing
10 -
Localization
8 -
Location Intelligence
79 -
Machine Learning
13 -
New Request
176 -
New Tool
32 -
Permissions
1 -
Runtime
28 -
Scheduler
21 -
SDK
10 -
Setup & Configuration
58 -
Tool Improvement
210 -
User Experience Design
165 -
User Settings
73 -
UX
220 -
XML
7
- « Previous
- Next »
- vijayguru on: YXDB SQL Tool to fetch the required data
- Fabrice_P on: Hide/Unhide password button
- cjaneczko on: Adjustable Delay for Control Containers
-
 Watermark
on:
Dynamic Input: Check box to include a field with D...
Watermark
on:
Dynamic Input: Check box to include a field with D...
- aatalai on: cross tab special characters
- KamenRider on: Expand Character Limit of Email Fields to >254
- TimN on: When activate license key, display more informatio...
- simonaubert_bd on: Supporting QVDs
- simonaubert_bd on: In database : documentation for SQL field types ve...
- guth05 on: Search for Tool ID within a workflow
| User | Likes Count |
|---|---|
| 41 | |
| 30 | |
| 19 | |
| 10 | |
| 7 |