Alteryx Designer Desktop Ideas
Share your Designer Desktop product ideas - we're listening!Submitting an Idea?
Be sure to review our Idea Submission Guidelines for more information!
Submission Guidelines- Community
- :
- Community
- :
- Participate
- :
- Ideas
- :
- Designer Desktop
Featured Ideas
Hello,
After used the new "Image Recognition Tool" a few days, I think you could improve it :
> by adding the dimensional constraints in front of each of the pre-trained models,
> by adding a true tool to divide the training data correctly (in order to have an equivalent number of images for each of the labels)
> at least, allow the tool to use black & white images (I wanted to test it on the MNIST, but the tool tells me that it necessarily needs RGB images) ?
Question : do you in the future allow the user to choose between CPU or GPU usage ?
In any case, thank you again for this new tool, it is certainly perfectible, but very simple to use, and I sincerely think that it will allow a greater number of people to understand the many use cases made possible thanks to image recognition.
Thank you again
Kévin VANCAPPEL (France ;-))
Thank you again.
Kévin VANCAPPEL
In some cases, the information about incoming columns to tools are (temporarily) forgotten, e.g. if Autoconfig is switched off, if the incoming connection is temporarily missing, or if column names are generated dynamically and the workflow has not been executed, yet.
Many tools deal with that situation well, e.g. Selection, Formula, or Summarize. In these cases, the tools tell the user that they cannot find incoming columns, but they preserve the configuration so that the user still can (at least partially) work on these tools and important information on the configuration is not lost:
Example Select Tool
- First step: Connections present, configuration typed in:
- Second step: Connection cut, confguration opened. The configuration looks screwed up but implicitly contains all settings:
- Third step: Connection re-connected. The configuration is as before:



Other tools behave the opposite, for example Unique or Macro Input (an for sure many other tools). If the incoming columns are currently unknown to the Designer and you click once on the symbol, the entire configuration of this tool is lost. You might try to get the configuration back by pressing undo. This, in most cases does not work. Or, even worse, you find out what happened later when it's too late for undo. In this case, you either have an old version of that workflow to look up the configuration or you have to re-develop it. In any case, this is unnecessary and time-consuming software behaviour.
Example Unique Tool
- Step 1: Connections present, configuration typed in:
- Step 2: Connection cut, confguration opened. The configuration is empty:
- Step 3: Connection re-connected: The entire configuration is permanently lost:



I wasn't sure whether I should report this as a bug or a feature enhancement. It is somehow in between. Two aspects tell me that this should be changed:
- Inconsistent behaviour of different tools for now reason,
- Easy loss of programming work, resulting in time-consuming bug fixing.
Please make sure that all tools preserve their configuration also if information on incoming columns is temporarily lost.
Hi everyone,
Add two additional features to a directory tool. Something like this:

Use cases:
1. Since it is not possible to use a folder browse on the Gallery, this could help a basic user create a list of possible folders to select from with the help of a drop-down
2. Directory analysis for cleaning purposes - currently, if you want to get a list of the folders with Alteryx, it takes forever for big file servers since Alteryx is mapping all the files
Both are achievable today through regex or a bat script.
Thank you,
Fernando Vizcaino
It would be great if you could include a new Parse tool to process Data Sets description (Meta data) formatted using the DCAT (W3C) standard in the next version of Alteryx.
DCAT is a standard for the description of data sets. It provides a comprehensive set of metadata that can be used to describe the content, structure, and lineage of a data set.
We believe that supporting DCAT in Alteryx would be a valuable addition to the product. It would allow us to:
- Improve the interoperability of our data sets with other systems (M2M)
- Make it easier to share and reuse our data sets
- Provide a more consistent way to describe our data sets
- Bring down the costs of describing and developing interfaces with other Government Entities
- Work on some parts of making our data Findable – Accessible – Interopable - Reusable (FAIR)
We understand that implementing support for this standards requires some development effort (eventually done in stages, building from a minimal viable support to a full-blown support). However, we believe that the benefits to the Alteryx Community worldwide and Alteryx as a top-quality data preparation tool outweigh the cost.
I also expect the effort to be manageable (perhaps a macro will do as a start) when you see the standard RDF syntax being used, which is similar to JSON.
DCAT, which stands for Data Catalog Vocabulary, is a W3C Recommendation for describing data catalogs in RDF. It provides a set of classes and properties for describing datasets, their distributions, and their relationships to other datasets and data catalogs. This allows data catalogs to be discovered and searched more easily, and it also makes it possible to integrate data catalogs with other Semantic Web applications.
DCAT is designed to be flexible and extensible, so they can be used to describe a wide variety. They are both also designed to be interoperable, so they can be used together to create rich and interconnected descriptions of data and knowledge.
Here are some of the benefits of using DCAT:
- Improved discoverability: DCAT makes it easier to discover and use KOS, as they provide a standard way of describing their attributes.
- Increased interoperability: DCAT allows KOS to be integrated with other Semantic Web applications, making it possible to create more powerful and interoperable applications.
- Enhanced semantic richness: DCAT provides a way to add semantic richness to KOS , making it possible to describe them in a more detailed and nuanced way.
Here are some examples of how DCAT is being used:
- The DataCite metadata standard uses DCAT to describe data catalogs.
- The European Data Portal uses DCAT to discover and search for data sets.
- The Dutch Government made it a mandatory standard for all Dutch Government Agencies.
As the Semantic Web continues to grow, DCAT is likely to become even more widely used.
DCAT
- Reference Page: https://www.w3.org/TR/vocab-dcat/
- Dutch (NL) Standard: https://forumstandaardisatie.nl/open-standaarden/dcat-ap-donl
- WIKI Pedia on DCAT: https://en.wikipedia.org/wiki/Data_Catalog_Vocabulary
RDF
- Reference Page: https://www.w3.org/TR/REC-rdf-syntax/
- Dutch (NL) Standard: https://forumstandaardisatie.nl/open-standaarden/rdf
- WIKI Pedia on DCAT: https://en.wikipedia.org/wiki/Resource_Description_Framework
Hello all,
According to wikipedia https://en.wikipedia.org/wiki/Materialized_view
In computing, a materialized view is a database object that contains the results of a query. For example, it may be a local copy of data located remotely, or may be a subset of the rows and/or columns of a table or join result, or may be a summary using an aggregate function.
The process of setting up a materialized view is sometimes called materialization.[1] This is a form of caching the results of a query, similar to memoization of the value of a function in functional languages, and it is sometimes described as a form of precomputation.[2][3] As with other forms of precomputation, database users typically use materialized views for performance reasons, i.e. as a form of optimization.
So, I would like to create that in Alteryx, for obvious performance reasons in some use cases.
This is not a duplicate of https://community.alteryx.com/t5/Alteryx-Designer-Desktop-Ideas/In-DB-Create-View/idi-p/157886
Best regards,
Simon
Hello,
As of today, we can't choose exactly the file format for Hadoop when writing/creating a table. There are several file format, each wih its specificity.
Therefore I suggest the ability to choose this file format :
-by default on connection (in-db connection or in-memory alias)
-ability to choose the format for the writing tool itself.
Best regards,
Simon
To allow users to pull data from Power BI, eg. datasets and usage data, to allow it to be manipulated in Alteryx.
Ability to color the connector lines to symbolize a path or data. This would help when you have multiple sources into a Join to determine that a path is still the same set of data when you have multiple paths created.
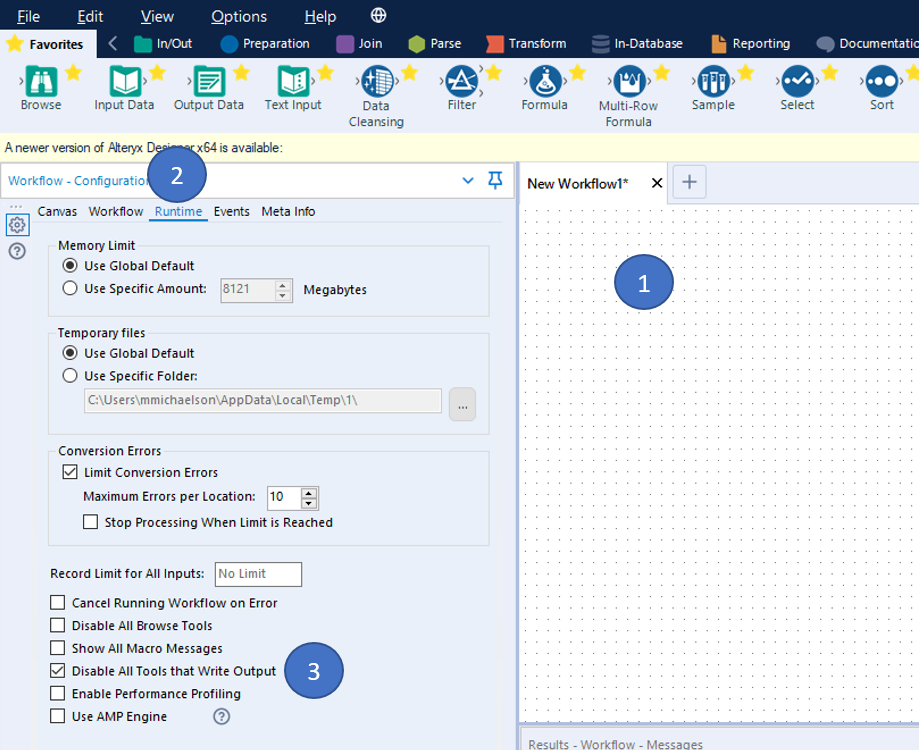
Today, there is an checkbox to "Disable All Tools that Write Output" within the Runtime settings for a workflow. Setting this option requires at least 3 clicks:
- Click on the canvas
- Click the "Runtime" tab in the Configuration pane
- Click the checkbox
Could a keyboard shortcut be added for this? I've spoken to several users who leverage this feature and, while it is already a time saver, it seems helpful enough where a keyboard shortcut is warranted.
Hello all,
Big picture : on Hadoop, a table can be
-internal (it's managed by Hive or Impala, and act like any other database)
-external (it's managed by hadoop, can be shared among the different hadoop db such as hive and impala and you can't delete it by default when dropping the table
for info, about suppression on external table :
https://docs.cloudera.com/HDPDocuments/HDP3/HDP-3.1.4/using-hiveql/content/hive_drop_external_table_...
Alteryx only creates internal tables while it would be nice to have the ability to create external tables that we can query with several tools (Hive, Impala, etc).
It must be implemented
-by default for connection
-by tool if we want to override the default
Best regards,
Simon
If the tables in the config window has lots of rows, it is quite complicated to find those of interest.
Please add a filter or search option (e.g. by the field name) to display only the relevant rows.
It would also be helpful to select or deselect multiple selected rows with one click.
Find an example from the "Select-Tool":

We have discussed on several occasions and in different forums, about the importance of having or providing Alteryx with order of execution control, conditional executions, design patterns and even orchestration.
I presented this idea some time ago, but someone asked me if it was posted, and since it was not, I’m putting it here so you can give some feedback on it.
The basic concept behind this idea is to allow us (users) to have:
- Design Patterns
- Repetitive patterns to be reusable.
- Select after and Input tool
- Drop Nulls
- Get not matching records from join
- Conditional execution
- Tell Alteryx to execute some logic if something happens.
- Record count
- Errors
- Any other condition
- Order of execution
- Need to tell Alteryx what to run first, what to run next, and so on…
- Run this first
- Execute this portion after previous finished
- Wait until “X” finishes to execute “Y”
- Orchestration
- Putting all together
This approach involves some functionalities that are already within the product (like exploiting Filtering logic, loading & saving, caching, blocking among others), exposed within a Tool Container with enhanced attributes, like this example:

The approach is to extend Tool Container’s attributes.
This proposition uses actual functionalities we already have in Designer.
So, basically, the Tool Container gets ‘superpowers’, with the addition of some capabilities like: Accepting input data, saving the contents within the container (to create a design pattern, or very commonly used sequence of tools chained together), output data, run the contents of the tools included in the container, etc.), plus a configuration screen like:

- Refers to the actual interface of the Tool Container.
- Provides the ability to disable a Container (and all tools within) once it runs.
- Idea based on actual behavior: When we enable or disable a Tool Container from an interface Tool.
- Input and output data to the container’s logic, will allow to pickup and/or save files from a particular container, to be used in later containers or persist data as a partial result from the entire workflow’s logic (for example updating a dimensions table)
- Based on actual behavior: Input & Output Data, Cache, Run Command Tools, and some macros like Prepare Attachment.
- Order of Execution: Can be Absolute or Relative. In case of Absolute run, we take the containers in order, executing their contents. If Relative, we have the options to configure which container should run before and after, block until previous container finishes or wait until this container finishes prior to execute next container in list.
- Based on actual behavior: Block until done, Cache, Find Replace, some interface Designer capabilities (for chained apps for example), macros’ basic behaviors.
- Conditional Execution: In order to be able to conditionally execute other containers, conditions must be evaluated. In this case, the idea is to evaluate conditions within the data, interface tools or Error/Warnings occurrence.
- Based on actual behavior: Filter tool, some Interface Tools, test Tool, Cache, Select.
- Notes: Documentation text that will appear automatically inside the container, with options to place it on top or below the tools, or hide it.
This should end a brief introduction to the idea, but taking it a little further, it will allow even to have something like an Orchestration layout, where the users can drag and drop containers or patterns and orchestrate them in a solution, like we can do with the Visual Layout Tool or the Interactive Chart tool:

I'm looking forward to hear what you think.
Best
Not sure I'd call this a user setting, but I couldn't figure out the right heading this belongs to.
When opening files, there are often times a couple of files at that aren't run on any kind of schedule or set time frame but you come back to when you need to run them.
There should be a way to set "FAVORITES" for a handful of files that you find yourself referring to on a repeated basis, but too far back to be on the 'recents' list because you open too many other files.
Hello all,
According to wikipedia :
https://en.wikipedia.org/wiki/Embedded_database
An embedded database system is a database management system (DBMS) which is tightly integrated with an application software; it is embedded in the application.
It's often like a single file/dll that you can use inside an application without the user having to connect (or at least to configure it) to it (it's all done inside the application). So, it's widely portable.
Why it does matter ?
As of today, there is not a single example of in database workflow because all the supported databases need the user to:
1/install an odbc driver (most of time, he won't have the rights to do so)
2/configure an odbc connection (sometimes, he doesn't have the rights to)
3/configure a connection on Alteryx (ok, he can)
So it requires IT action, which can be pretty long (in ùany organization, it requires several weeks !!). And even with all of that,the users must be granted privilege to access database and the customer need to develop its own examples and write its own specific documentation.
Well, this is not efficient.
What I suggest is Alteryx to use one of embedded database for training support/one tool examples. SQLlite seems good, maybe a more analytics oriented (like DuckDB ) would be more efficient.
The requirement are, I think, the following :
-OpenSource and free
-Fast
-SQL compliant
-With a bulk load ability
Best regards,
Simon
Hello --
Many times, I want to summarize data by grouping it, but to really reduce the number of rows, some data needs to be concatenated.
The problem is that some data that is group is repeated and concatenating the data will double, triple, or give a large field of concatenated data.
As an example:
Name State
| A | New York |
| A | New York |
| A | New Jersey |
| B | Florida |
| B | Florida |
| B | Florida |
The above, if we concatenate by State would look like:
| A | New York, New York, New Jersey |
| B | Florida, Florida, Florida |
What I propose is a new option called Concatenate Unique so I would get:
| A | New York, New Jersey |
| B | Florida |
This would prevent us from having to use a Regex formula to make the column unique.
Thanks,
Seth
Please add a toggle for Dark Mode as Alteryx, after all these years of using it, is burning out my retinas.
The OS and most apps have a Dark Mode theme so flipping back to a bright white canvas is very jarring. I tried to adjust the canvas colors in a more muted way but never can get it to work satisfactorily and still be as easy to read as the retina burning default.
Hello all,
We all love pretty much the in-memory multi-row formula tool. Easy to use, etc. However, the indb counterpart does not exist.
I see that as a wizard that would generate windowing functions like LEAD or LAG
https://mode.com/sql-tutorial/sql-window-functions/
Best regards,
Simon
Add Unicode category to the cleansing tool
I have developed many workflows, macros, and apps, and I have always had to find a workaround for displaying information on the user config page or user interface.
For example, I want to input 'Default text' into the Text Box interface tool, but the problem is that it does not accept any external connection.
It would be great if this tool had a Q input anchor that could accept data from a connected tool (in both single or multi-line mode) or from external input (such as a file for DropDown list or List Box tools).


When making any type of macro, it's important to test the functionality of the macro via a debug. This is accomplished successfully with normal tools, however there's a bug that will not allow the user to debug In-DB macros that use either of the following standard Alteryx tools:
- Macro Input In-DB
- Macro Output In-DB
If either of these tools are included in the macro you are building, an error message will appear not allowing you to open a debug.
Error message: Question Tool Load Error: A question tool with a tool id of XXX is missing the associated question data.
Of course, Macro input and output tools do not require any specific action/question tool associated with it. This is a bug. A user pointed out the XML issue almost 3 years ago here:
In summary: "It appears that the tool itself inserts a hidden Question attribute into the XML which can also be seen in Workflow Configuration"
Source:
Examples....
A normal macro, using standard tools:

After debugging a standard macro, the Macro Input/Output tools correctly change to a Text Input and a Browse tool. This allows the macro author to test the macro.

However, when trying the same thing with In-DB tools in a macro, an error message appears:
In-DB macro 1:

In-DB Macro error message (after clicking "Open Debug"):

{kind=link}
Toggle individual expressions on/off in the formula tool.
On more than a few occasions I have a number of expressions in a single formula tool and find myself wanting to turn off a few or many, but not all.
It'd be great if there was a checkbox to activate/inactivate : on/off : include/exclude : select/deselect (whatever language you like for the concept) an individual expression.
Simple as a text box. with maybe a 'select/deselect ALL box available incase you want to turn most off then only select a single one?
- New Idea 208
- Accepting Votes 1,837
- Comments Requested 25
- Under Review 150
- Accepted 55
- Ongoing 7
- Coming Soon 8
- Implemented 473
- Not Planned 123
- Revisit 68
- Partner Dependent 4
- Inactive 674
-
Admin Settings
19 -
AMP Engine
27 -
API
11 -
API SDK
217 -
Category Address
13 -
Category Apps
111 -
Category Behavior Analysis
5 -
Category Calgary
21 -
Category Connectors
239 -
Category Data Investigation
75 -
Category Demographic Analysis
2 -
Category Developer
206 -
Category Documentation
77 -
Category In Database
212 -
Category Input Output
632 -
Category Interface
236 -
Category Join
101 -
Category Machine Learning
3 -
Category Macros
153 -
Category Parse
75 -
Category Predictive
76 -
Category Preparation
384 -
Category Prescriptive
1 -
Category Reporting
198 -
Category Spatial
80 -
Category Text Mining
23 -
Category Time Series
22 -
Category Transform
87 -
Configuration
1 -
Data Connectors
948 -
Desktop Experience
1,493 -
Documentation
64 -
Engine
122 -
Enhancement
275 -
Feature Request
212 -
General
307 -
General Suggestion
4 -
Insights Dataset
2 -
Installation
24 -
Licenses and Activation
15 -
Licensing
10 -
Localization
8 -
Location Intelligence
79 -
Machine Learning
13 -
New Request
177 -
New Tool
32 -
Permissions
1 -
Runtime
28 -
Scheduler
21 -
SDK
10 -
Setup & Configuration
58 -
Tool Improvement
210 -
User Experience Design
165 -
User Settings
73 -
UX
220 -
XML
7
- « Previous
- Next »
- vijayguru on: YXDB SQL Tool to fetch the required data
- apathetichell on: Github support
- Fabrice_P on: Hide/Unhide password button
- cjaneczko on: Adjustable Delay for Control Containers
-
 Watermark
on:
Dynamic Input: Check box to include a field with D...
Watermark
on:
Dynamic Input: Check box to include a field with D...
- aatalai on: cross tab special characters
- KamenRider on: Expand Character Limit of Email Fields to >254
- TimN on: When activate license key, display more informatio...
- simonaubert_bd on: Supporting QVDs
- simonaubert_bd on: In database : documentation for SQL field types ve...