Alteryx Designer Desktop Ideas
Share your Designer Desktop product ideas - we're listening!Submitting an Idea?
Be sure to review our Idea Submission Guidelines for more information!
Submission Guidelines- Community
- :
- Community
- :
- Participate
- :
- Ideas
- :
- Designer Desktop: New Ideas
Featured Ideas
Hello,
After used the new "Image Recognition Tool" a few days, I think you could improve it :
> by adding the dimensional constraints in front of each of the pre-trained models,
> by adding a true tool to divide the training data correctly (in order to have an equivalent number of images for each of the labels)
> at least, allow the tool to use black & white images (I wanted to test it on the MNIST, but the tool tells me that it necessarily needs RGB images) ?
Question : do you in the future allow the user to choose between CPU or GPU usage ?
In any case, thank you again for this new tool, it is certainly perfectible, but very simple to use, and I sincerely think that it will allow a greater number of people to understand the many use cases made possible thanks to image recognition.
Thank you again
Kévin VANCAPPEL (France ;-))
Thank you again.
Kévin VANCAPPEL
It would be great to have an outbound connector on output tools for 2 reasons:
a) if this outbound connector can carry key results of the output process, this can be saved in an audit log. For example - rowcounts; success/failure. This kind of capabiltiy (to generate a log, or to be able to check the rowcount of rows committed to a database) is important for any large BI ETL process
b) this woudl also allow the process to continue after the output process and also act as a flow of control. For example:
- First output the product dimension
- once done - then connect (using the outbound connector) to the next macro which then updates the Sales fact table using this product dimension (foreign key dependancy)
-
Category Connectors
-
Data Connectors
Improve HIVE connector and make writable data available
Regards,
Cristian.
Hive
| Type of Support: | Read-only |
| Supported Versions: | 0.7.1 and later |
| Client Versions: | -- |
| Connection Type: | ODBC |
| Driver Details: | The ODBC driver can be downloaded here. Read-only support to Hive Server 1 and Hive Server 2 is available. |
-
Category Connectors
-
Category Input Output
-
Data Connectors
Please add Parquet data format (https://parquet.apache.org/) as read-write option for Alteryx.
Apache Parquet is a columnar storage format available to any project in the Hadoop ecosystem, regardless of the choice of data processing framework, data model or programming language.
Thank you.
Regards,
Cristian.
-
Category Connectors
-
Category Input Output
-
Data Connectors
There are a number of requests for bulk loaders to DBs and Im adding MySQL to the list.
Really every DB connection (on prem and cloud) need some bulk loader capabilities to be added (if they don't have it already)
-
Category Connectors
-
Category In Database
-
Category Input Output
-
Data Connectors
Our Terdata environments use LDAP authentication and we really need the Teradata bulk load connection in Alteryx to support this feature with Teradata. ODBC works fine with LDAP but Bulk Load Connection doesn't.
Alteryx Development has confirmed this is currently not a feature and also has put this into their backlog.
-
Category Connectors
-
Data Connectors
Hi currently the s3 upload tool only allows file format of *.yxdb , *.json, *.csv and *.avro
In order to optimize loading to redshift, it would be good to have a few more functions
1. Ability to s3 upload with *.gz format
eg: Reading in a file using the input tool -> s3 upload tool (which has a gzip function with the following options - record limit, delimiter, UTF8)
http://docs.aws.amazon.com/redshift/latest/dg/t_loading-gzip-compressed-data-files-from-S3.html
2. Change max record limit, delimiter, UTF8 format
3. Change the objectName to 'take file/table name from field' with filename containing filename or part of filename similar to the 'Output tool'
Adrian
-
Category Connectors
-
Data Connectors
Preface: I have only used the in-DB tools with Teradata so I am unsure if this applies to other supported databases.
When building a fairly sophisticated workflow using in-DB tools, sometimes the workflow may fail due to the underlying queries running up against CPU / Memory limits. This is most common when doing several joins back to back as Alteryx sends this as one big query with various nested sub queries. When working with datasets in the hundereds of millions and billions of records, this can be extremely taxing for the DB to run as one huge query. (It is possible to get arround this by using in-DB write out to a temporary table as an intermediate step in the workflow)
When a routine does hit a in-DB resource limit and the DB kills the query, it causes Alteryx to immediately fail the workflow run. Any "temporary" tables Alteryx creates are in reality perm tables that Alteryx usually just drops at the end of a successful run. If the run does not end successfully due to hitting a resource limit, these "Temporary" (perm) tables are not dropped. I only noticed this after building out a workflow and running up against a few resource limits, I then started getting database out of space errors. Upon looking into it, I found all the previously created "temporary" tables were still there and taking up many TBs of space.
My proposed solution is for Alteryx's in-DB tools to drop any "temporary" tables it has created when a run ends - regardless of if the entire module finished successfully.
Thanks,
Ryan
-
Category Connectors
-
Category In Database
-
Data Connectors
-
Engine
Given redshift prefers accepting many small files for bulk loading into redshift, it would be good to be able to have a max record limit within the s3 upload tool (similar to functionality for s3 download)
The other functionality that is useful for the s3 upload tool is ability to append file names based on datetimestamp_001, 002, 003 etc similar to current output tool
-
Category Connectors
-
Category Input Output
-
Data Connectors
It would be cool if a connector line would turn red when you select it, making it easier to trace the path (similar to how the lines turn red when you click on a join tool).
-
Category Connectors
-
Data Connectors
The challenge:
We have hundreds of SOAP based Salesforce (SF) connectors in our scheduled modules that were created with Alteryx 9.0-9.5. Alteryx 10.0+ is now using REST API based SF connectors. We have to replace all of these connectors when we move to 10.0+.
Proposed idea:
Alteryx creates an automated process for converting SOAP SF connectors to REST API SF connectors, so that when you open an old module in 10.0+, they are automatically updated.
This seems feasible as the information supplied by Alteryx users for the SOAP SF connectors is sufficient for the REST API SF connectors to work (i.e. URL, username, password, security token, table name, fields, WHERE clause, etc...).
Thanks,
Jeremy
-
Category Connectors
-
Data Connectors
-
Category Connectors
-
Data Connectors
-
Category Connectors
-
Data Connectors
-
Category Connectors
-
Data Connectors
Issue: It appears that the Marketo Input SOAP API Connector needs to go through all 500 + columns of lead object data before it filters out the specific request I indicated. What this means is that to process 1 day of lead data for 3 columns of data, it takes 45 minutes plus and not ideal.
Client Services indicated that there is a limitation with the Marketo SOAP API tool and it would be best to utilize the Download tool and build a custom connection to the CRM System (Microsoft Dynamics) to get a predefined list of Lead IDs and then use that as a filter via the Marketo Input SOAP API connector.
Request:
1. Add Microsoft Dynamics Connector
2. Try to innovate a better Marketo Service Connector to just grab the defined fields as opposed to go through the entire processing for all records to only filter back down to.
Eric
-
Category Connectors
-
Data Connectors
-
Category Connectors
-
Data Connectors
Currently we are limited to chossing one of two layout direction options, vertical or horizontal. Why not make the direction assignable at the tool icon instead of as a module level control. I could right click the tool and have layout direction as an option which would activate a visual handle which could either allow infinite rotation control or rotation control in 45 degree increments. You can use Viso as an example of rotational control for a shape. In Visio the shape rotates, in our case since we are really looking to change the flow direction the icon could remain in the same orientation as it does now but the conenctor point(s) would rotate around the compass in say 45% increments base on the drag of the rotation handle that appears
-
Category Connectors
-
Data Connectors
-
Category Connectors
-
Data Connectors
-
Category Connectors
-
Data Connectors
Hello,
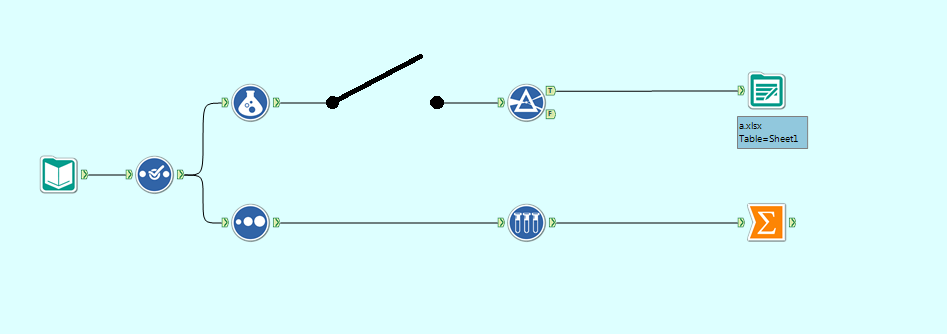
I think it would be extremely useful to have a switch connector available in Alteryx. What I mean by a switch connector is a connecting line with an on/off state that will block the data stream through it when off. Something like below:
Switch Connector in an "Off" state
This would be extremely useful when you only want data to flow down some of the paths. In the example above, I might turn the switch connector to off because I want to see the Summarize results without outputting to a document.
The current methods for having a path/set of tools present but unused are insufficient for my needs. The two methods I and Alteryx support were able to find were:
2. Putting the tools in a disabled tool container - I cannot see the tools when the container is disabled. I want to be able to see my tool set-up even when I am not using it.
This is inspired by the use of switches in electrical circuit design, such as:
Please comment if you also think this would be useful, or if you have ideas for ways to improve it further. Thank you!
-
Category Connectors
-
Data Connectors
I think it would be extremely useful to have a switch connector available in Alteryx. What I mean by a switch connector is a connecting line with an on/off state that will block the data stream through it when off. Something like below:
Switch Connector in an "Off" state
This would be extremely useful when you only want data to flow down some of the paths. In the example above, I might turn the switch connector to off because I want to see the Summarize results without outputting to a document.
The current methods for having a path/set of tools present but unused are insufficient for my needs. The two methods I and Alteryx support were able to find were:
2. Putting the tools in a disabled tool container - I cannot see the tools when the container is disabled. I want to be able to see my tool set-up even when I am not using it.
This is inspired by the use of switches in electrical circuit design, such as:

Please comment if you also think this would be useful, or if you have ideas for ways to improve it further. Thank you!
-
Category Connectors
-
Data Connectors
- New Idea 277
- Accepting Votes 1,818
- Comments Requested 24
- Under Review 174
- Accepted 56
- Ongoing 5
- Coming Soon 11
- Implemented 481
- Not Planned 116
- Revisit 62
- Partner Dependent 4
- Inactive 674
-
Admin Settings
20 -
AMP Engine
27 -
API
11 -
API SDK
218 -
Category Address
13 -
Category Apps
113 -
Category Behavior Analysis
5 -
Category Calgary
21 -
Category Connectors
247 -
Category Data Investigation
77 -
Category Demographic Analysis
2 -
Category Developer
208 -
Category Documentation
80 -
Category In Database
214 -
Category Input Output
640 -
Category Interface
239 -
Category Join
103 -
Category Machine Learning
3 -
Category Macros
153 -
Category Parse
76 -
Category Predictive
77 -
Category Preparation
394 -
Category Prescriptive
1 -
Category Reporting
198 -
Category Spatial
81 -
Category Text Mining
23 -
Category Time Series
22 -
Category Transform
89 -
Configuration
1 -
Content
1 -
Data Connectors
963 -
Data Products
2 -
Desktop Experience
1,536 -
Documentation
64 -
Engine
126 -
Enhancement
329 -
Feature Request
213 -
General
307 -
General Suggestion
6 -
Insights Dataset
2 -
Installation
24 -
Licenses and Activation
15 -
Licensing
12 -
Localization
8 -
Location Intelligence
80 -
Machine Learning
13 -
My Alteryx
1 -
New Request
193 -
New Tool
32 -
Permissions
1 -
Runtime
28 -
Scheduler
23 -
SDK
10 -
Setup & Configuration
58 -
Tool Improvement
210 -
User Experience Design
165 -
User Settings
80 -
UX
223 -
XML
7
- « Previous
- Next »
- TUSHAR050392 on: Read an Open Excel file through Input/Dynamic Inpu...
- NeoInfiniTech on: Extended Concatenate Functionality for Cross Tab T...
- AudreyMcPfe on: Overhaul Management of Server Connections
-
 AlteryxIdeasTea
AlteryxIdeasTeam on: Expression Editors: Quality of life update - StarTrader on: Allow for the ability to turn off annotations on a...
- simonaubert_bd on: Download tool : load a request from postman/bruno ...
- rpeswar98 on: Alternative approach to Chained Apps : Ability to ...
-
 caltang
on:
Identify Indent Level
caltang
on:
Identify Indent Level
- simonaubert_bd on: OpenAI connector : ability to choose a non-default...
- maryjdavies on: Lock & Unlock Workflows with Password